



















Please read our in-depth Guideline for prompting at Cagliostrolab Blog
Overview
Animagine XL 4.0, also stylized as Anim4gine, is the ultimate anime-themed finetuned SDXL model and the latest installment of Animagine XL series. Despite being a continuation, the model was retrained from Stable Diffusion XL 1.0 with a massive dataset of 8.4M diverse anime-style images from various sources with the knowledge cut-off of January 7th 2025 and finetuned for approximately 2650 GPU hours. Similar to the previous version, this model was trained using tag ordering method for the identity and style training.
With the release of Animagine XL 4.0 Opt (Optimized), the model has been further refined with an additional dataset, improving stability, anatomy accuracy, noise reduction, color saturation, and overall color accuracy. These enhancements make Animagine XL 4.0 Opt more consistent and visually appealing while maintaining the signature quality of the series.
Changelog
- 2025-02-13 – Added Animagine XL 4.0 Opt and Animagine XL 4.0 Zero
Better stability for more consistent outputs
Enhanced anatomy with more accurate proportions
Reduced noise and artifacts in generations
Fixed low saturation issues, resulting in richer colors
Improved color accuracy for more visually appealing results
- 2025-01-24 – Initial release
Model Details
Developed by: Cagliostro Research Lab
Model type: Diffusion-based text-to-image generative model
License: CreativeML Open RAIL++-M
Model Description: This is a model that can be used to generate and modify specifically anime-themed images based on text prompt
Fine-tuned from: Stable Diffusion XL 1.0
Usage Guidelines
The summary can be seen in the image for the prompt guideline.

1. Prompt Structure
The model was trained with tag-based captions and the tag-ordering method. Use this structured template:
1girl/1boy/1other, character name, from which series, rating, everything else in any order and end with quality enhancement
2. Quality Enhancement Tags
Add these tags at the end of your prompt:
masterpiece, high score, great score, absurdres
3. Recommended Negative Prompt
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Optimal Settings
CFG Scale: 4-7 (5 Recommended)
Sampling Steps: 25-28 (28 Recommended)
Preferred Sampler: Euler Ancestral (Euler a)
5. Recommended Resolutions
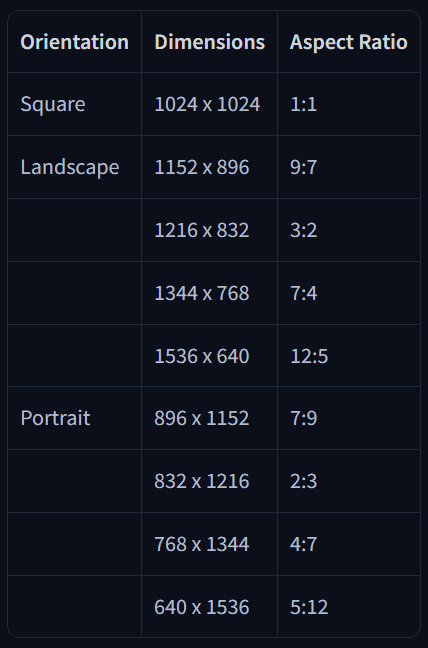
6. Final Prompt Structure Example
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Special Tags
The model supports various special tags that can be used to control different aspects of the image generation process. These tags are carefully weighted and tested to provide consistent results across different prompts.
Quality Tags
Quality tags are fundamental controls that directly influence the overall image quality and detail level. Available quality tags:
masterpiecebest qualitylow qualityworst quality
Score Tags
Score tags provide a more nuanced control over image quality compared to basic quality tags. They have a stronger impact on steering output quality in this model. Available score tags:
high scoregreat scoregood scoreaverage scorebad scorelow score
Temporal Tags
Temporal tags allow you to influence the artistic style based on specific time periods or years. This can be useful for generating images with era-specific artistic characteristics. Supported year tags:
year 2005year {n}year 2025
Rating Tags
Rating tags help control the content safety level of generated images. These tags should be used responsibly and in accordance with applicable laws and platform policies. Supported ratings:
safesensitivensfwexplicit
Training Information
The model was trained using state-of-the-art hardware and optimized hyperparameters to ensure the highest quality output. Below are the detailed technical specifications and parameters used during the training process:

Acknowledgement
This long-term project would not have been possible without the groundbreaking work, innovative contributions, and comprehensive documentation provided by Stability AI, Novel AI, and Waifu Diffusion Team. We are especially grateful for the kickstarter grant from Main that enabled us to progress beyond V2. For this iteration, we would like to express our sincere gratitude to everyone in the community for their continuous support, particularly:
Moescape AI: Our invaluable collaboration partner in model distribution and testing
Lesser Rabbit: For providing essential computing and research grants
Kohya SS: For developing the comprehensive open-source training framework
discus0434: For creating the industry-leading open-source Aesthetic Predictor 2.5
Early testers: For their dedication in providing critical feedback and thorough quality assurance
Contributors
We extend our heartfelt appreciation to our dedicated team members who have contributed significantly to this project, including but not limited to:
Model
Gradio
Relations, finance, and quality assurance
Data
Fundraising Are Now Open Again!
We're excited to introduce new fundraising methods through GitHub Sponsors to support training, research, and model development. Your support helps us push the boundaries of what's possible with AI.
You can help us with:
Donate: Contribute via ETH or USDT to the address below.
Share: Spread the word about our models and share your creations!
Feedback: Let us know how we can improve.
Donation Address:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Github Sponsor: https://github.com/sponsors/cagliostrolab/
Why do we use Cryptocurrency?:
When we initially opened fundraising through Ko-fi and using PayPal as withdrawal methods, our PayPal account was flagged and eventually banned, despite our efforts to explain the purpose of our project. Unfortunately, this forced us to refund all donations and left us without a reliable way to receive support. To avoid such issues and ensure transparency, we have now switched to cryptocurrency as the way to raise the fund.
Want to Donate in Non-Crypto Currency?
Although we had a bad experience with Paypal, and you’d like to support us but prefer not to use cryptocurrency, feel free to contact us via Discord Server for alternative donation methods.
Join Our Discord Server
Feel free to join our discord server: https://discord.gg/cqh9tZgbGc
Limitations
Prompt Format: Limited to tag-based text prompts; natural language input may not be effective
Anatomy: May struggle with complex anatomical details, particularly hand poses and finger counting
Text Generation: Text rendering in images is currently not supported and not recommended
New Characters: Recent characters may have lower accuracy due to limited training data availability
Multiple Characters: Scenes with multiple characters may require careful prompt engineering
Resolution: Higher resolutions (e.g., 1536x1536) may show degradation as training used original SDXL resolution
Style Consistency: May require specific style tags as training focused more on identity preservation than style consistency
License
This model adopts the original CreativeML Open RAIL++-M License from Stability AI without any modifications or additional restrictions. The license terms remain exactly as specified in the original SDXL license, which includes:
✅ Permitted: Commercial use, modifications, distributions, private use
❌ Prohibited: Illegal activities, harmful content generation, discrimination, exploitation
⚠️ Requirements: Include license copy, state changes, preserve notices
📝 Warranty: Provided "AS IS" without warranties
Please refer to the original SDXL license for the complete and authoritative terms and conditions.
Description
FAQ
Comments (82)
Well done, my man! I can't wait to try it out.
Now that's exciting to try out
很高兴,又见到你了,老朋友
The only question is how it fares against illustrious. Animagine 3.0 was overshadowed by Pony, wonder if it will suffice against another peer this time. Huge project. much deserved fame, let's see.
As expected.
Yeah, not good. I don't really see the appeal when the style has dropped down to Illustrious (mixed artists) and the prompt adherence is the same as the 3.1 version (SDXL). I'm sitting this one out.
@YuuNSFW What are your opinions on this model after using it?
I like this version 4, but it doesn't feel/act like Animagine 3.1.
Some things are better (more user friendly, less tinkering, generally better anatomy, better instruction following, digital painterly styles), somethings less preferable (less expressive artist tags, flat color, two tone, simplified light physics, ai-generated doesn't work in negative prompt, etc.).
I'd say that After some testing and playing with artist tags and characters, this version absolutely can be compared to illustrious like it feels as one of illust models but it's SDXL Definitely a huge improvement from V3.1
This is probably the best Anime base model right now. One of the downsides of Illustrious and Noob is that they are based on a fine tune of SDXL that cooked the text encoder on danbooru tags. This model retains the knowledge from the SDXL base model so it is more flexible and creative.
For example, try this silly prompt and you will see what I mean: "anime screencap, year 2023, best quality, key anime shot, dynamic angles, toho animation, 1girl, hat inspired by lululemon, purple eyes, elf, holding a sword, battle pose, plugsuit designed by Gustave Eiffel, Grand Canyon mystical forest with purple leaves, depth of field, 300 movie inspired"
All the Illustrious and Noob finetunes will fail at this (they are still great models though). You can even use celebrities or internet culture references to make some cool stuffs since this knowledge isn't lost.
Great job and thanks for this release!
People need to quit with the downvoting, opinions are valid.
Illustrious is cool, it has it's merits..
but the minute you use NLP on it, it goes garbo mode. XD
For my testing, the main issue is Anatomy, but it was already mentioned in the Limitations. Ones that is improved or Fixed, this could be really really good.
Also, I noticed BREAK has a lot of power, it could literally separate character and style completely. I will do more testing, so far, I'm enjoying it.
Will there be a 4.1 eventually?
Make it good or bad, this model is not very supportive of furry content.
Then you're not tagging correctly? XD
@duskfallcrew I tried some tags like "furry", "furry female", "brown fur", etc (copied and pasted from danbooru), while they do not work very much. Or at least this model is much less sensitive to those keywords than other models (like Pony or NoobAI)
@hokono because unlike Pony which likely has e621 and pony booru data, Animagine is an all rounder "ANIME" style, and you'll have to tag in which styles of animals you're looking at doing. "FURRY FEMALE" is broad, see if you mention "VIERA" you'll get rabbit ears, if you mention "MIQOTE" you'll get my dumb ass cackling to the way to the bank for the cheats, ebcause just think in game tags (I say that beacuse i'm a Miqote in FFXIV, i'm the dumbass making ffxiv my career XD)
The model isn't optimized on furry content and is purely trained with anime-related images.
@hokono
It can do furry, but I haven't tested it enough though. Here is an image I got from it:
https://civitai.com/images/54460239
In order to using SDXL LoRA, probabaly this is the best model in SDXL 1.0
Prompt Adherence: Ignore the haters - people are still telling me my Pony AND Illustrious ones blow at that.
Style: It works with loras.
This is really great! It's very good with prompt understanding and composition, it even knows the newest genshin character (Lan yan), which I was surprised as they just dropped not long ago at all. It even works with some lora trained on illustrious and noob. Only issue I have now is it seems to need highres fix to polish out any fine details/outlines otherwise it's a toss up whether or not you'll end up with defining lineart that isn't like muddled/squishy. kind of like what happens with an underbaked lora. Since it's random when this happens my guess is that some style and/or artists are undertrained? Without a prominent style and artist added into the prompt it can give you undertrained ones (or maybe that's just the artist's style?) which probably causes those issues. Since, as I put 'garouma' instant clarity. Though regardless thank you so much for this amazing model!
This model very powerful when you combine between character name and series. I can give you an example such as "Nakano Miku" from "Go-Toubun no Hanayome", if you prompt only character name model will doesn't know about this character (but seem it know well about rest of four from Quintuplets, poor Miku lol)
Any reason to use this instead of NoobAI-XL Epsilon (Illustrious 7.5m arts + NoobAI Epsilon 12m arts) or NoobAI-XL V-pred (Illustrious 7.5m arts + NoobAI Epsilon 12m arts + NoobAI-XL V-pred 16m arts)?
more artists, more styles and more characters
@derpmagician how if this checkpoint has less images?
Noob also has the entire e621 dataset
@derpmagician absolutely not. yes animagine has some new characters but overall noob still has more
reason? quality. noobai merges with lesser quality image while this one focuses on absurdres on danbooru.
@Madafada1991 There are only 1.8M absurdres images on danbooru, both animagine and noobai used them plus many million more of lower quality
@Churrus you know that danbooru is not the only place with high quality images right? Some are even in exhentai, plus, training setting can play a differences too.
@Madafada1991 e621 also has such images. There is no reason to compare since these pictures were cropped by buckets when it was in finetuning.
@Madafada1991 What's the point of this argument? The training was from danbooru. Sure, training settings can play a difference, but that's not what you claimed before.
@Churrus if the quality is the same, we would already see the difference. But right now, animagine indeed looks slightly better with higher fidelity. Noob has better versatility BUT also questionable license. Posting on social media requires u to post prompt, seed, cfg, steps, and what noob variant that you use. It sounds impossible to enforce, but its still a license.
@Madafada1991 but in exhentai doesnt have a tag to indicate absurdres quality or similar
Gotta be honest: this has some issues. Artist styles are inconsistent, fingers are abysmal, and it seems to always default to super low saturation.
Quality: Animagine = Illustrious (up to model, lora) > Pony
Characters, Series: Animagine > Illustrious > Pony
Danbooru Tags: Illustrious > Animagine = Pony
Artists, Styles: Animagine > Illustrious > Pony
Fingers, Anatomy: Illustrious > Animagine = Pony
LoRa: Pony > Animagine > Illustrious
NSFW: Pony > Illustrious > Animagine
Overall: Illustrious > Animagine > Pony
I really like this model; I see strong competition with Illustrous. I’m hoping for more versions that try to mitigate what is obviously not easy to fix. Does anyone know of a list of the characters this model has been trained on?
Hi, dev here. For now we don't have a list. But you can check Danbooru for characters that is available before Jan 7th, 2025.
SO GOOD
I've done a few tests and I have to say it's pretty disappointing in terms of quality.
it definitely needs far more prompt wrangling than other models and it doesnt understand most poses or hands.
I like this model, but I get inconsistent results. I hope this issue is resolved soon
Thank you for your input, maybe if we can know what the inconsistency means?
No separate section? Whats goin on?:))
Fairly low quality outputs. Sloppy and uncoordinated structures in the images, as if someone threw paint all over the place.
Sasuga animagine, while it lacks the pose that IllustXL provide, the quality and clarity is crazy. If you guys having finger issue, use "five finger" tag. it'll reduce some of the problem.
what the hell is "Sasuga"?
@wktra "as expected"
@Madafada1991 yikes...
10/10
no way this has achieved a Gaussidorov 10/10!!
@ElectricDreams :)))))))
falls apart when doing more than "1girl"'ing but finetunes should go hard. not as good as base illust but is a solid base for models to build on.
训练信息的图片是不是放错了?
放了推荐分辨率得图片了?
Trained a LoRA for Ani 4.0. Can balance brightness and enhance contrast. Also some hand improvments. https://civitai.com/models/971952?modelVersionId=1340810
This model is very good at generating anime art IF you know the correct prompt and settings for it.
Many people have already mentioned about the broken results. In my case, I get those results mostly because I use the prompt style and settings from another model.
I tried the guidelines in the description, and the results were better than what I usually had. So, the problem could be either the model itself or just a skill issue.
And yes, it still has some weaknesses. But I think this model has improved a lot since the previous version.
Unfortunately, despite the addition of a scoring mechanism similar to Pony, there are still issues that have persisted since version 3.1. The accuracy of character movements remains poor, with problematic hand and limb rendering, and the model seems even less sensitive to NSFW content. The prompt weighting has also become quite inconsistent compared to version 3.1.
On the positive side, the image quality is still excellent, and the lighting effects and background details have improved over version 3.1. However, the anatomy of the characters continues to be problematic. The body proportions often look unnatural, with characters appearing too thin and small, resembling a loli-like body shape. Additionally, without using artist tags or LoRAs, the characters' faces still default to the classic "AnimagineXL anime face."
Overall, while there are some enhancements, I don’t see this as a significant improvement over version 3.1. That said, I appreciate the effort and work put into this update.
1. What do you mean my "addition of a scoring mechanism similar to Pony"? The scoring system is always been there since 3.1, just under different names so people do not get confused like they used to.
2. You must use series name for characters, similar to 3.0 and 3.1. This is semi-mandatory since a lot of characters with smaller dataset struggles without it and will defaults to "Animagine XL face".
https://civitai.com/articles/11092
Prompting Guide. Covers about 300 tags and 60 characters, many of which are not in the github list.
The link throws 404
@eyobayeyo Thats very strange what about if you look here for the animagine one.
https://civitai.com/user/fitCorder/articles
An excellent model; I particularly appreciate its color scheme and attention to detail. Its composition and background are truly commendable. However, the issues with the fingers are quite critical, showing poor anatomical accuracy. If this problem could be resolved, it would outshine models in the 'il' series
Really like this model.
It takes a bit more generating/inpainting compared to noobai but the aesthetics are way better.
What are diffusers and is it a must to have?
its a python library, maybe for generating directly using code
I think this version has lost some of its former strengths. The style has been compromised by fads and it doesn't look like the anime I was familiar with. The physique is too similar to a particular artist. However, I cannot recall their names.
I think the aim was to update the dataset so the model recognizes more characters.
This model looks super interesting!
a40, I call it that, It's definitely a great model.
animage31 used to be my favorite anime model.
Sorry for the possible offense, I made some suggestions and comments.
Characters, backgrounds, style, body structure.
a40 and noob e11 characters may be comparable, a40 characters are newer, but a little character features seem not fixed enough, probably because a40 starts from sdxl, while noob comes from illu, with more inheritance.
I think a40 may look better in the background,But the stability of the limbs may be inferior,and probably because of multiple views, it is easy to have one more person in the horizontal image..
But in terms of style, the artist's words are almost not obvious, and the default style and physique seem too distinct.
Hi, try to move enhancement tags at the end of your prompt. It's causing some issue if you're trying to put it at the front. Also, don't forget the series tags because it is semi-mandatory.
Cheers.
when can we expect to see the dit based animagine?
Can this recognize artists from Twitter?
100/10
Cool
How do I get the diffusers?
where to get character tag file?
I also want to know!!! :(
100/100
lots of anime characters arent showing up. Is it just me?
Are you using the recommended prompt structure?
Try to put "1girl/1boy, danbooru character tag, danbooru serie tag..." at the start of your prompt.
If you put the character tags later in the prompt it will mess up the character.
Details
Files
animagineXL40_v40.safetensors
Mirrors
animagine-xl-4.0.safetensors
animagineXL40_v40.safetensors
animagineXL40_v40.safetensors
animagine-xl-4.0.safetensors
animagineXL40_v40.safetensors
animagine-xl-4.0.safetensors
animagineXL40_v40.safetensors
animagine-xl-4.0.safetensors
animagine-xl-4.0.safetensors
animagine-xl-4.0.safetensors
animagine-xl-4.0.safetensors
animagine-xl-4.0.safetensors