











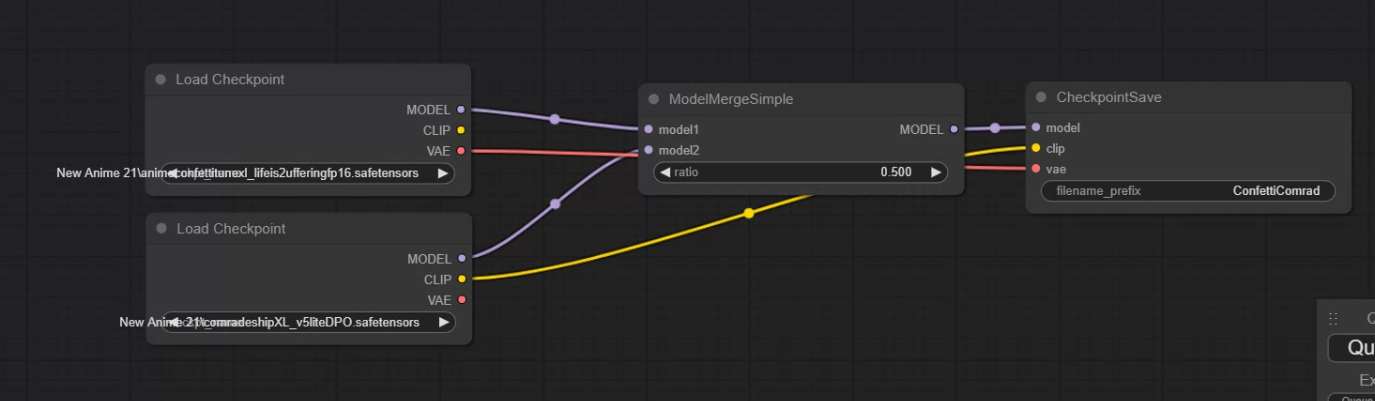
I mixed these two models listed below 50:50 In the was shown in the attached Image and the result has been the best model I've ever seen in my two years of playing with this stuff. If someone who really knows what they're doing tries this It'll be insane.
https://civarchive.com/models/184813/animeconfettitunexl?modelVersionId=306585
https://civarchive.com/models/246299/comradeship-xl?modelVersionId=305497
Have fun playing with this guys :D
Description
FAQ
Comments (55)
Currently, the best folk SDXL model that can achieve ainme NSFW.
PonyDiffusion V6 and this model are the current NSFW kings.
I love this model! It's so much easier compared to original pony xl v6.
But hard to move from default style.
Yeah, extremely coherent model. I have never seen anything like it.
Pony itself is way less coherent. But what is the source of competence of this model? I can think only of DPO Lora merged in...
Glad you were able to get some use out of my model! I trained various different styles directly into my model -- you can call them with Art by ARTISTNAME -- I don't know how much info was lost in the merge, but if you up the weight, you may be able to wrangle the style a bit. Art by JCM2, Akiko Takase, or bluethebone, are some of the strongest effects. I also have a retro anime tag that shifts the images. I have examples of the artist styles and a txt document with all artists I trained in that version on my page that you helpfully linked. <3
The link from your page with artists is https://1fichier.com/dir/xazkNCbB
Also storing it on catbox or HF would be more longterm
@pr_director I'll add a catbox on my page. I have a 1fi account, so that was just easiest for me, but if peeps like catbox =====> https://files.catbox.moe/ucv9if.txt that's my most up to date list. I think there are a few on there that isn't on the posted model, but once I post my next version, it'll match up.
Thanks for the suggestion! <3
For me style started to change a bit at weights around 2 and only at 3 it started to look similar, but at the cost of some details. Some artists are not working at all. I'd say this model is great for consistent quality output in default style, but not for diverse styling, which is still pretty impressive.
Thanks for your model too, btw :3
I need to know how did you make this model achieve such good results without loras just by pronting,for example:it can replicate characters like:Mavis dracula,Jinx,Katarina and many other characters without the need of a lora,this model and the Pony 6 have been the only models that are consistent by pronting,I have tried about 10 XL models and none are as good as the 2 already mentioned,it is almost as good and accurate as Novelai v3. 0,I'm impressed,are there any other models that are as good as this one? I need a realistic one and at least a semi realistic one.
I've posted an image of the method I used to make the model. TO be honest it was just chance we have no idea why this models is so good.
@mowens420th could you make more models with the same method? famous models like dreamsharper,cartoon3d realistic,among others are not even a small part of what yours is,i would like to see models of yours that can have styles of the most famous models of civitai,with a comic style,2.5d,realistic,etc would be fine,i have tried more than 400 models and this one by far is the best,it is very close to be as good as Novelai 3.0 is. ,i am new using comfyui and i am having a lot of fun learning,hope i can learn more,hope to see more of your models in the future,it is something magical and somewhat curious that you can replicate characters to perfection,the prompts are pretty good,i would say too good to be true, This model and the pony model can become a revolution in civitai, I would like to see more XL loras that are missing a lot, I think with this model as a base you can get to do many great things, I was testing and characters like chun-li, cammy, hinata does it perfectly.
We've been trying but we don't really understand what happened here. Two models that were fairly typical with a few quirks combined to make this model and I did it randomly. We need to get someone who really understands how to peel a model apart to look at this I think.
@mowens420th maybe the few creators who have created models as good as yours can help you, I think some of them must know how this works, testing I have found a few interesting ones that do a similar job to yours:
1- Pony Diffusion V6 XL was the first model in civitai to be versatile.
https://civitai.com/models/257749/pony-diffusion-v6-xl
2-Js2Prony https://civitai.com/models/280321/js2prony this one is the same,the creator has several models that apparently can give good results I have tried this one and it works very well(needs vae)
3-AutismMix SDXL this creator used your model as a base to mix and create another one,he also has a mix with the Pony Diffusion v6 model,this one is pretty good as well
https://civitai.com/models/288584?modelVersionId=324524
4-Animagine XL V3 this is a very curious model,according to its description it is a model that has very good prompt improvements,it can't recreate existing characters without loras,with the others mentioned I could,I need to try this one out more.
https://civitai.com/models/260267/animagine-xl-v3
I keep searching all over civitai looking for models like yours with great potential,it is boring for me to keep testing prompt with 1.5 and with 98% of XL models that are practically the same as 1.5 and many times worse,I hope the information is helpful and you can test them and if you find any other model out there with good results or create others I would be happy to download it and try it.
@mowens420th update: I've done my research, the good results of your model are due to the fact that you mixed this
https://civitai.com/models/246299/comradeship-xl?modelVersionId=305497
that model has DPO a natural language technology that has been developed since December last year and is open source since January this year, I think that mixing models that already have DPO with other existing ones in civitai you can achieve excellent things, if you mix a DPO model with dreamsharper for example you could have similar results, my suggestion is that you use a DPO model and another that you are interested in testing to see what results you get, all models that I left in the previous comment all use DPO
here is the explanation of how it works:
https://civitai.com/models/242825?modelVersionId=273996
I tried the 1.5 lora to test with results only 2% better,the anatomy is still horrible and the arms and legs are still deformed,although it understands a little better the prompts,reading a little the forums they say the DPO works great for XL but as far as I see very mediocre for 1.5,so I would like to see more models with more styles and Loras with this new technology,maybe 1. 5 will improve someday but for now I prefer to keep experimenting with XL,in the next months I think this will have a great potential,for now many people don't know DPO that's why they are still making mediocre XL models,but I know this will change in the next months,I would like to know your opinion and I would like you to share the information with more creators to make grow more the community of good models and creators.
@FireBlack85 I thought it was the DPO model too but then I went and tested the other model in this mix and it is very good at prompting and I think it is underestimated how good that model is and a new version just dropped confetti3 that is crazy good at following prompts. It needs a push in the negative prompt to create stronger styles but I think thats why it is so good merged with models that naturally have stronger style . https://civitai.com/models/184813?modelVersionId=329516
@fikxzer currently there are many underestimated models, little by little they are creating models with DPO, I will try the one you shared with me and see how it goes, I leave you the new models with DPO that I have tried.
2.5D_Prony
https://civitai.com/models/298707/25dprony?modelVersionId=335499
2.6D_Prony
https://civitai.com/models/298908/26dprony?modelVersionId=335720
2.7D_Prony
https://civitai.com/models/298717/27dprony?modelVersionId=335508
also this other one that is very recent that I have to try out
https://civitai.com/models/299991/astro-lance-xl?modelVersionId=336926
many people still don't know that DPO exists,but I'm sure it will be a standard in a few months,there are incredibly good models with DPO with very few downloads,people are still downloading the most popular XL models without DPO,I had more than 400 1.5 models and I have deleted almost all of them and I am only downloading the XL models that have DPO
I barely have enough VRAM to use it, so i don't really know how to run SDXL, but this is miles ahead of every other model i've tried.
Can anyone explain the "score_9, score_8_up, score_7_up, score_6_up, source_anime, source_explicit" etc. tags?
Hi, fellow enthusiast here! Those are the required tags for Pony Diffusion XL, which Comradeship uses as a base model. By the way, source_explicit is not a correct tag. It should be rating_explicit. I recommend using these tags for NSFW anime art (optional for this model):
Positive Prompt: score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up, source_anime, rating_explicit
Negative Prompt (not needed): source_pony, source_furry, source_cartoon, censored, 3d, sketch, hyperrealistic
If you're okay with Western-style, then include source_cartoon in the positive prompt.
Other settings I recommend:
CLIP Skip 2, CFG 6 or 7, Steps 28 to 30. HiRes Fix 1.5x your favorites if your hardware can handle it.
Resolution: 1024x1024, Portrait 832x1216, Landscape 1216x832
Sampler: Euler A, or, DPM++ 2M Karras
(If this model's creator sees this, feel free to add all of the above to the description.)
About the VRAM issue - I recommend using "Tiled VAE" extension. It's a lifesaver that comes at almost no cost to your PC or the image composition. It automatically detects the best settings for you, so you only need to check "Enable" on Tiled VAE.
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
It works even better if you have ControlNet Tile, but that's optional.
@heathergreen95
Already using tiled vae. I can get 960x960 and inpaint at 896x896 with my 1080ti, but can't do any higher than that.
On DPM++ 2M Karras, 20 steps seems to be just enough, surprisingly. i've been using a cfg of 5, going higher seems to make everything a bit blobby.
I'll see what difference "rating" rather than "source" makes in a bit.
@spunkymcgoo Ah, okay, sorry to hear about the GPU issue. I don't have any other suggestions for that, sadly, but just keep in mind SDXL might give different results when the ratios don't add up to 1024x1024.
I agree that less is more with the CFG and steps. I've noticed CFG 5 with DPM++ 2M Karras helps to add more variety in the artstyles. At 20 to 24 steps, I saw the biggest difference in colors or oversaturation, but the character details remained mostly the same. 30 steps usually seemed like overkill and caused some character variations.
This specific model has a tendency towards NSFW content, so rating_explicit might only cause a change in showing "private" areas 100% of the time rather than say, 50%, depending on the prompt. Just to note, the other tags are rating_questionable and rating_safe. Good luck!
@heathergreen95 If i close EVERYTHING else on my system, i can run 1024x1024, although it tends to do a few OOM errors at the start before enough free VRAM is available to start it. I tried running --medvram-sdxl, but there's some kind of bug that makes RAM usage skyrocket after the image generates. eats up all my RAM and my swap in seconds.
@spunkymcgoo Sorry about this late reply - I recently came across a VAE for SDXL which might help with your VRAM issue.
https://civitai.com/models/140686?modelVersionId=155933 "As good as SDXL VAE but runs twice as fast and uses significantly less memory."
You could also try WebUI Forge, which is built on A1111 but uses less VRAM. https://github.com/lllyasviel/stable-diffusion-webui-forge
Hello! Thank you for your work! I recommend updating your model to the latest versions of Confetti and Comrade, which are Anim3Conf3tti and Comradeship-v5A-DPO. I created my own 50/50 merge of these two models and the results are fantastic.
Ive been meaning to try this, mostly been using Anim3Conf3tti because of its amazing variety.
Can you upload it to Civitai?
@silvereq Hi! I'm sorry that I missed your comment for so long. Someone else has a 50/50 merge of the most recent versions, Confetti v4 and Comrade v5A, uploaded. I'm glad, because I had trouble creating a safetensors file. A1111 would only create ckpt for some reason.
wow this is the second model that is perfect. also does upside down character perfectly. its even better that the first one.
Anyone else struggling to do night/dark scenes? Is that a problem with this merge or with the SDXL models in general?
It's an issue with SDXL models in general. Use https://github.com/Seshelle/diffusion-noise-alternatives-webui to work around that. For night scenes you want to lower red and green, but set blue very high.
Am I doing something wrong? All my images come out pretty blurred, specially in the eyes.
This model requires a very, very low CFG. Try around 3 - 3.5
@westinghouse Thank you! Since I'm a beginner I didn't knew how CFG worked, is there any wiki that explains each function?
@CornetF No, but this checkpoint is a merge of Comradeship which also required a low CFG, so you have to kind of extrapolate based on the model's composition.
@CornetF If I remember correctly then CFG determines how heavily it tries to draw exactly what you specify in the prompt at the cost of producing a lower quality image.
I use cfg 5, with DPM++ 2M Karras, at 20 steps. Also, you might need this extension on automatic1111 https://github.com/hako-mikan/sd-webui-prevent-artifact
If you need to fix faces, you can inpaint them at full resolution with "only masked" in the inpaint tab.
Anybody else having long queues to make gen's using Confetti Conrade? one pic takes like 14 minuets on my 3060ti where as other similar models take like 30 seconds.
This IS the MOST insane fucking absolute best model out there! It understands EVERYTHING perfectly and result are supreme!!!! That's insane! TOP 1 favourite forever!
Does this Checkpoint need any VAE or other setup? Or just running it by it self works?
Probably the best SDXL model i've tried so far. Highly recommend to everyone!
Did you had to use any VAE or any other extra setup to run it? Or it works by it self?
You're a fucking genius! This is one of the best models I have ever used!
It's so amazing that mixed those two models can create such a good model!
Thank you very much for your work!
Thank you but I did just kinda combine two random models and pure magic happened. I've tried to develop it a bit but it's a strange beast.
https://civitai.com/models/311817
Everyone, I recommend you try this newest version of Confetti/Comrade. I believe the original uploader no longer maintains this model.
It has a more consistent anime style and backgrounds. Make sure to read the description for best results.
I love this model, it's the best in class for both NSFW and SFW with tons of artist styles. Recognizes almost any canon character and handles multiple-character interactions well.
I honestly found this version to be a lot better than that one
I've tried to update this model but it was kind of a fluke I think a personal mix I have may be slightly better but I wouldn't just upload something that might be slightly better.
Is it possible to train LoRas with this model? I tried couple times but I'm getting errors that CLIP data is messed or UnpicklingError: invalid load key, '^' during latent conversion. This model is great and versatile, and it matches my dataset captions perfectly, so it would be great if it could be used with LoRas
I have no idea I haven't tried yet myself I've had some success training Loras into the model but not tried training a lora into it.
@mowens420th Turned out the issue was that Collab Kohya trainer didn't understand checkpoint name when downloaded from CivitAI, since it had weird url query parameters in the filename. Once I renamed model files to model.safetensors, it worked correctly
Hmmm, actually the thing I wrote was about another model, but somehow related.
The Unpickling Error was fixed, but I get error during Lora training:
Error(s) in loading state_dict for CLIPTextModel: Missing key(s) in state_dict: "text_model.embeddings.position_ids"
Tried to fix it with Automatic1111 Toolkit extension, but here is what is says about this model:
Model is 6.46 GB. Model type identified as VAE-v1-BROKEN. Model components are: VAE-v1-SD.
Contains 6.31 GB of junk data!
Seems it doesn't understand the model structure at all.
When you're trying to do pov handholding and it keeps generating suspiciously penis shaped hands at the bottom of the screen
Does this Checkpoint need any VAE or other setup? Or just running it by it self works?
This is still the best pony model
Really liked this back in the MageSpace days. As I don't create anything locally I haven't used this since. Would be nice to see it available here some day. <3