
















✨ What Makes This Model So Special? ✨
🔄 Perfect fusion of Flux1-dev and Flux1-schnell strengths
💾 Full FP8 version (includes CLIP and VAE)
💻 Runs smoothly on modest 12GB GPUs
🖼️ Premium quality outputs rivaling resource-hungry monsters
🛠️ How To Get The Most Out Of It:
👑 Advanced Workflow:
📁 Setup Structure
📂 ComfyUI/
├── 📂 models/
│ ├── 📂checkpoints/
│ │ ├── SPEED-FP8.safetensors
💻 Tested on forge https://civarchive.com/images/24458443
👏 Special Thanks
Big thanks to @Dunc4n1dah0 ! 🙌
👨💻 Developer Information
This workflow guide was created by Abdallah Al-Swaiti:
For additional tools and updates, check out the OllamaGemini Node: GitHub Repository

Description
I found little enhancment using e5m2 quantization !
FAQ
Comments (85)
Please remake with e5m2 weight type, it's more close to fp16.
thanks , i will try as soon as possible
Exactly what I was looking for. I will test this asap. Thanks.
..what e5m2 and e4m.. !!??
that's types of AI model quantization (make it smaller in size with keeping same quality) whatever some times e5 better sometimes e4 better its depend on model , here choose what you see it better ,,, i think e5 more accurate
@AbdallahAlswa80 well explained , thank you
It's a level in Heretic.
I'v get only black images. What i do wrong?
D model works fine.
did you try this work flows https://civitai.com/models/629858 or https://comfyanonymous.github.io/ComfyUI_examples/flux/flux_schnell_checkpoint_example.png
{kind=link}
I had to remove some nodes, but it worked almost flawlessly on an Intel I5, Geforce 3060 6GB VRAM, 32 GB RAM.
Thank you sir! I offer you my first comment on civitai
that awesome please let us see what you have
This gives me hope, since the first time I've tried Flux on my 12 gb, it froze whole PC for half an hour.
@karnas the very first time, I got a bsod! but then everything went almost smoothly. rendering time is decent
awesome! Finally i got FluxDev to work
The new version actually does seem to give me better results too. Thanks for the update
Where to put this? in unet or in checkpoint? and if put in checkpoint and load with checkpoint loader how to change type?
Use workflow from description just remove Geminy and make prompt youself.
those models prepared to be used as any other model just put the in checkpoit folder and start creating
E5M2. NICE! Output-wise, it's great. Also, there's no need to put a double clip, and no need to choosing the weight is a bonus. It works like a charm on the RTX 3060 12GB, taking about 30 seconds only, with sharp and vibrant output. If someone want to copy workflow, search "what the flux is schnell" bellow in gallery, and click icon copy nodes from info popup, then Ctrl+V in blank ComfyUI window.
A niche note: somehow it's better than original Flux-1 Schnell to output the facial combination of mixed races than the original Flux. For example, "woman with mixed ethnicity of Malay Indonesian Singaporean Persians Irish Dutch Norwegians Ukrainian" produces a facial representation that really combines those ethnicities and nationalities, while the original Flux-1 Schnell struggles with this and weirdly producing East Asian-like facial features.
With your workflow on my RTX 3060 12GB the process takes about 250 seconds, what am I doing wrong?
@serikenhik is it turned to be lowvram? here:
Tips Avoiding LowVRAM Mode (Workaround for 12GB GPU) - Flux Schnell BNB NF4 - ComfyUI (2024-08-12) : r/StableDiffusion (reddit.com)
I now using Schnell BNB NF4 btw.. lots faster.
I don’t understand what e5m2 is, please explain. And what is the generation time?
this is one kind of quantization , has acurate result
@AbdallahAlswa80 thank you, I understand what you're talking about, I wish I knew how faster this model is
@AbdallahAlswa80 thank you, I understand what you're talking about, I wish I knew how faster this model is
@content_for_inte4086 there is awesome comments about that its depend on your Gpu device theres many factors
Exponent 5, Mantissa 2, Sign 1
Damn, great job! This is working really well and thank you for the simple instructions! This model barely but perfectly fits into my 16Gb vram. 768x1280 takes 8.5s on a 4060 Ti with 4 steps.
also tested on 6 Giga vram , show me your arts
@AbdallahAlswa80 How long does it take to generate after you change prompts? I mean I get the 1st generation takes a lot of time to load the model but is it every time?
Is this a fusion model of dev and schnell fp8, so the protocol is still non-commercial. Am I right?
yea , i used them as source so the license still same
so the t5xxl is also fp8 ? baked in?
i think for my 24GB VRAM it's better to use fp8 flux with fp16 t5xxl
its not noticed when using lcm as in this model , increasing 1 step mean = t5xx fp32
@AbdallahAlswa80 ok i just read in reddit that it's a very bad idea to use fp8 t5xxl, major prompt adherence loss:
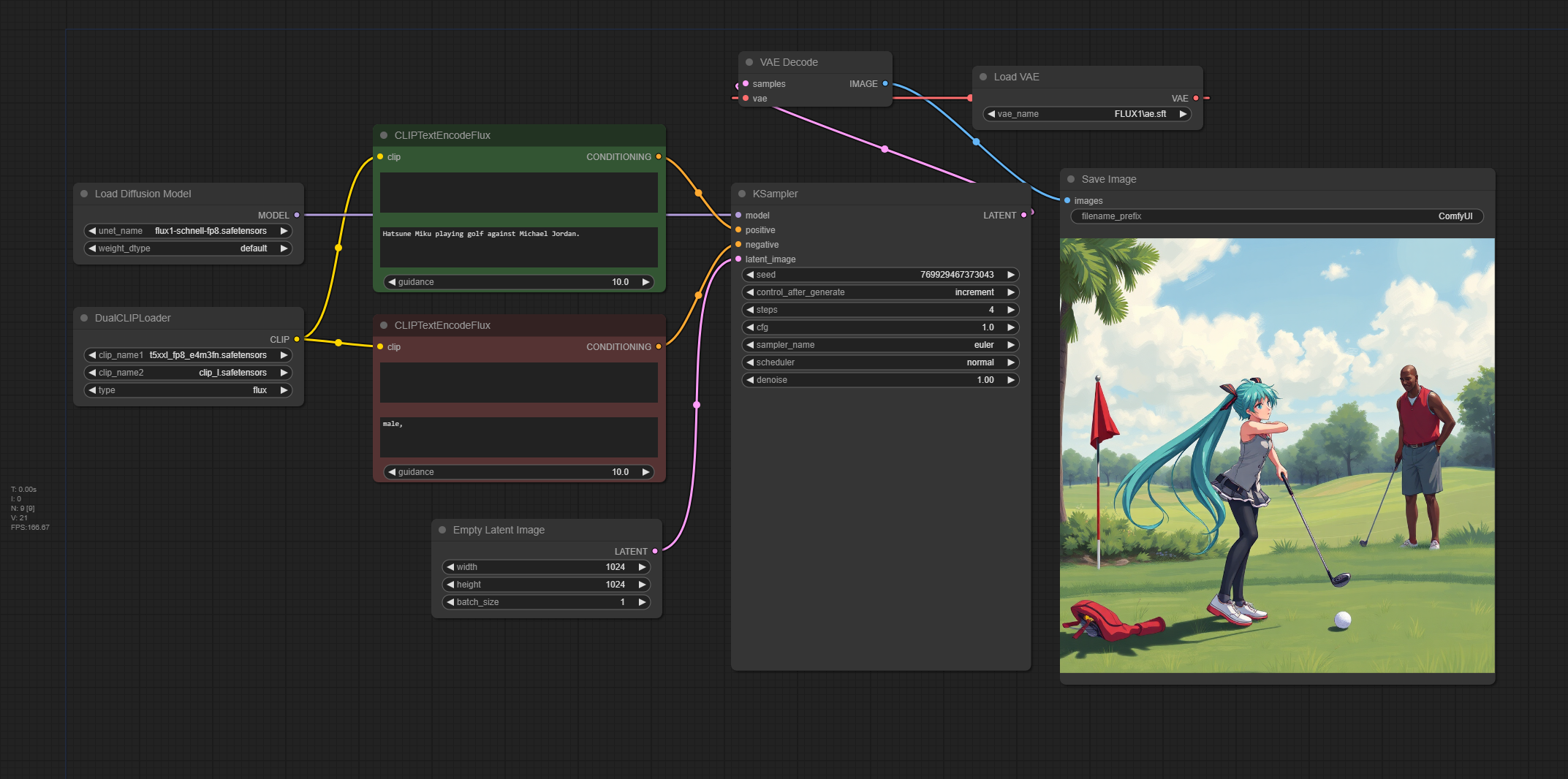
check out this comparison:
prompt: "Miku playing golf with Michael Jordan"
https://files.catbox.moe/uqsii5.png
{kind=link}
And this the picture with the T5 fp16 with the same exact seed
https://files.catbox.moe/olsf64.png
SOURCE:
https://www.reddit.com/r/StableDiffusion/comments/1el79h3/comment/lgqqmv8/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
{kind=link}
@tazztone try that yourself , the article was not detailed about which flux version he used , what ever if the prompt become more complex , the diffrence between fp8 and fp16 start apearing , so if you smart in writing prompt , the result will become the same , also here the scheduler is "LCM"
@tazztone even I'm using your workflow (T5 fp8) with same seed, it produce miku and michael jordan playing golf just fine. I'm using Flux Schnell FP8 + T5 FP8. here's the workflow jpec89.png (2145×1066) (catbox.moe) (it's png, can be dropped into ComfyUI for you to try). I heard many times that T5 FP8 is bad, and it's should be, because it's lower in size, but it's not THAT bad.
{kind=link}
@somerandomguy then maybe it was cherrypicked example :shrug
8gb performance?
i think it works how much ram do you have?
RTX 4060 mobile 8 GB VRAM + 32 GB DDR5 SDRAM took ~142 seconds.
i tried it and usually it takes like less than 1 minute per step using my cpu with any large model but this one the step passed over than 12 minutes , would like you to share with me your thoughts what's really wrong ? i'm tried my own setup and the comfy wf , both ran to this very slow 12mins per step while sampling ?! what should i d to figure out that ?
unfourntly , this model "flux" 1step = 6-10 steps of other model , thats normal, sorry for that
@AbdallahAlswa80 thanks , then there's nothing wrong with my setup ...they have to mention that , they didn't . that flux required more h.w power , then if i want to use any flux model i have to get more h.w .
@AbdallahAlswa80 is that for all flux right ? should i save my time and don't try any other merge ?
@amazingbeauty i think if it converted to onyx or another type but it's yet not supported ,
The file name entails e4m3, shouldn't that be e5m2? Maybe I don't get it...
sorry for hear that , what is your opinion depend on ?
@AbdallahAlswa80 my mistake, sorry, forget about it.
For those who are confused by this. There are two commonly used ways to "compress" a 16-bit floating point to 8-bit floating point:
https://new.reddit.com/r/FluxAI/comments/1ej3uga/what_is_the_difference_between_fp8_e5m2_and_fp8/
Does this still go in unet folder or checkpoints now?
checkpoint
This is the best Fluxdev-model on civit right now. It works great in swarmUI for me.
if we could only uncensor it, then this would defeat not only SD3, but also pony :D
it used schnell as base !
Yeah right now flux is cool as a concept or as an alternative to some other things; but if you want NSFW material, or cartoons, or good character lora functionality, etc....all that only comes from SD and pony.
im having some issues with upscaling, inpainting and img2img using this (in swarmUI).
Let me know if anyone else managed to make it work well. the upscaling is distorting more than increasing in quality, and the inpainting is hard to control..
@pihlawrkr738 That aged like fine milk. It took a while and will always be a work in progress (as is the case with Pony, it took a while to get third party extensions), but there are a decent number of good options for Flux now, enough that I don't reach back to the older models. And of course it stacks up against SD3, they exfiltrated the training data for SD3 and included it in Flux's base training set.
@lesjo Yes, stuff improves over time. Eventually something better than both will come around. Right now I've been preferring Illustrious for most things; flux still is not great for what I personally want to generate.
No need to be so sour about it; and there is no need to get so attached to any one model. Things are always changing as models and the technology improve.
@pihlawrkr738 Oh I know full well that Flux is just the current new hotness, just as Pony was, and XL, and so on and so on. I just thought it would have aged better if it had said "WHEN we can uncensor it" because it was a clear selling point from the start that Flux is not actually censored, just untrained in certain areas. Then kohya and OneTrainer added Flux LoRA support, and the floodgates started to open.
This did not seem to be an faster for me on w 2080 TI, with 64 GB of RAM...
100%|████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:50<00:00, 12.66s/it] Requested to load AutoencodingEngine Loading 1 new model Prompt executed in 98.21 secondsDid I do something wrong with my ComfyUI flow? i put the e5m2 file into my checkpoints directory, and loaded that as a checkpoint. Using the model's linked workflow.
who say its faster , and which model you compare with , the fp8 way just use less gpu so the low gpu ram can used it , in your device setup i think most of model loading go to cpu , which lower speed ,time needed =expfunc(cpu percentage)
Amazing Speed for m2...in 60s per image for same prompt. in my RTX3060 6GB laptop..i7 12th gen
For me it's 3 minutes with Ryzen 9 32Gb ram and RTX 3060Ti 8Gb...
I must have the wrong workflow, which workflow do you use, cliploader and vae... please..?
can i use this in forge?
yes you can use it as nf4 or fp8e52 dev or schnell as show in this video https://civitai.com/images/24458443
Ok this seems great on paper, i wanna ask before downloading, will this be faster than the normal NF4 on forge?, the other question is which is the whole reason why i want to download FP8 is 1- my other FP8 model only goes to unet folder which forge doesn't support. 2- currently most loras are only supported by the FP8 version is this the case with this custom model?
this model support lora ,,, work on comfyui and forge
Very good model and very fast - only 26 seconds for an image of 896 X 1152 px
AMD Ryzen 5 5600X 6-Core Processor 3.70 GHz
Installed RAM 32.0 GB
NVidia RTX 3070 8G Vram
For me it's 3 minutes with Ryzen 9 32Gb ram and RTX 3060Ti 8Gb...
I must have the wrong workflow, which workflow do you use, cliploader and vae... please..?
@polloloco769 I obtained this performance with forge and found that this model was slower with ComfyUI, but I'm just starting out with this one.
I advise you to try the GGUF Q8 versions is fast enough for me :
Here's a basic workflow for this model :
https://civitai.com/images/27892896
Good luck!
THE BEST!
Suggestion: Adding some pointers to run this would have been awesome!
https://civitai.com/models/628210/advanced-ai-art-remix-workflow-for-flux
https://civitai.com/models/644552?modelVersionId=721172
and this model because some guidelines was needed for single model
How to use this models in diffusers FluxFillPipeline python code guys
its normal flux not flux-fill
@AbdallahAlswa80 yeah i means how to use it in diffusers python code. do you have a example code or any thing would be a big help bro
@tuantpa925 it need to be converted to diffusers , if u favorite diffusers i'll send u useful link
@AbdallahAlswa80 thank you
@tuantpa925 theres way called load from single file (load transformer) and then load normal flux-dev ,
from diffusers import FluxPipeline, FluxTransformer2DModel
HF_TOKEN = "hf_***"
flux_repo = "multimodalart/FLUX.1-dev2pro-full"
ckpt_path = "https://huggingface.co/Comfy-Org/flux1-dev/blob/main/flux1-dev-fp8.safetensors"
transformer = FluxTransformer2DModel.from_single_file(ckpt_path, subfolder="transformer", torch_dtype=torch.bfloat16, token=HF_TOKEN)
pipe = FluxPipeline.from_pretrained(flux_repo, transformer=transformer, torch_dtype=torch.bfloat16, token=HF_TOKEN) ,,, this work for single model not full checkpoint , search around if theirs a way
@AbdallahAlswa80 so you mean is try to convert this check point (SPEED FP8) to diffusers and then load it to a transformer (FluxTransformer2DModel) and use others stuff like tokenizer , text encoder of the Flux dev1 ?
@tuantpa925 no you can load model directly in that way , but this is checkpoint witch contain 3 parts , the transformer(main model), text encoder , and vae ! try !
Thank you for mentioning me. I really appreciate it :-)
Very good model