






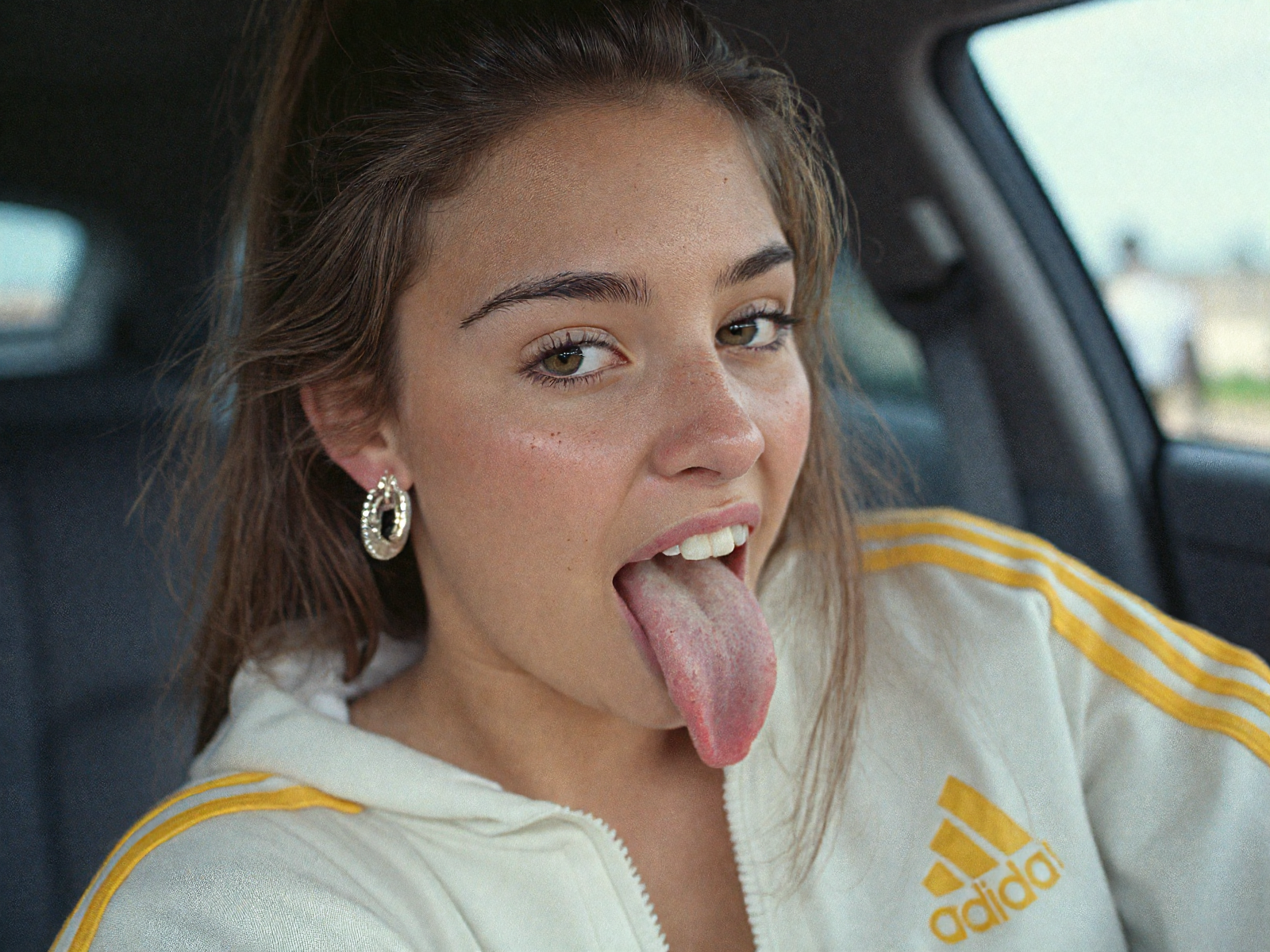
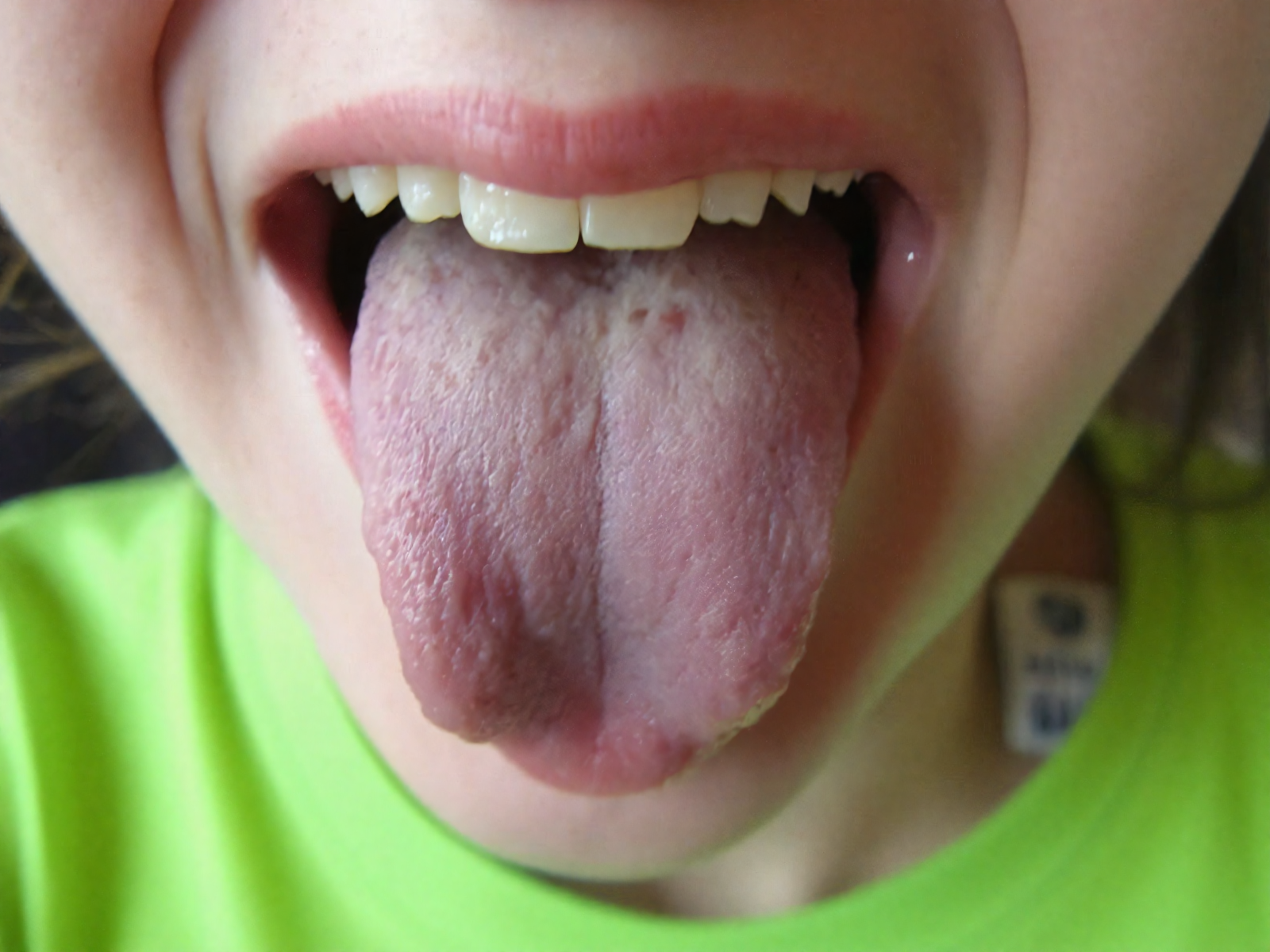





Trained 1024x1024 on 600+ high resolution sharp images of women opening mouth wide, sticking out tongue, showing uvula, displaying teeth, roof of mouth etc.
Most realistic samplers are like DPM++ 2M or DEIS or SD Forge - Flux Realistic (slow) (Scheduler: Beta ), the latter gives amazing results!
Guidance / (distilled) CFG between 1,8 and 2,5, Keep it low for realism!
Lora strength between 0.7 and 1
V2.x has a different, extended, training set and configuration, following prompts better yet with different image results from V1.x, more variety.
V1.2 is the final from V1 training set and config, producing excellent image quality, but not following prompts as well and less variety in output
Description
This version adds more training steps, and generally results in images that look a little more harsh/rough in the details. Really nice for closeups (skin pores, lip cracks, moles, tastebuds etc.)
REMEMBER TO USE LOW CONFIGS (1,8 - 2,2) THIS IS A REALISM LORA
If you need more smooth images, please use the previous versions, they work equally well!
FAQ
Comments (9)
This looks like such an amazing lora will there ever be an equivalent SDXL version?
I have tried, but results were not on par with Flux version, currently I am focusing my time on video :-/ Can you not use Flux , card/memory requirements have dropped significantly recently with GGUF versions, etc.
@jhnprst2150 I'm looking into it right now lol. nice work anyway
hey my dear buddy, i want to ask a question related to this amazing mind blowing lora of yours since I've been using it for quite some time now!!
did you by any chance in ur training data also trained the lora on wide variety of expressions/emotions?? i noticed that not only it improves the tongue-mouth-teeth areas since that's the main focus of it BUT it also gives me a great expressions like (smiling- shocked- suprised- puckered lips- etc).
i say this one of my favorite if not my favorite lora here on civitai, great job my dear mate and tbh you should think about releasing more loras for FLUX dev like this!! 👏😊
Hi you are welcome anytime! I used more than 600 high res images to train this Lora, exactly for that reason! There was actually a lot variety, different face expressions, crazy faces, far away shots, close up shots, smiling, shouting, turned upside down, dancing etc. its sad that the Joy2 captioner I used to caption the images for training was not able to capture the wide variety of expressions actually in the imageset. It really kept close to like 'a smiling female in a joyful setting' etc. even if the girl in question was really making crazy faces all over the place :-) let me know if you are interested in specific type of images, if I find in the trainigset I can send over some of the training captions for it to use in your prompt
Just starting to test this LoRA and think it looks like it will provide more control over my face characteristics. That said, is there any keywords we should be using that it's specifically trained to use?
its trained using joy2 captions, i did not do manual caption (too many images). so there are no exotic or secret hidden trigger words; are you looking anything specific face characteristic I might be able to check the train captions
Curious why this comes up as a Stable Diffusion v1 Lora in SwarmUI vs a Flux 1 Lora?
hi would not know.. i do not use SwarmUI. Its definately Flux-D
Details
Files
tongue-flux-v2.1.safetensors
Mirrors
tongue-flux-v2.1.safetensors
tongue-flux-v2.1.safetensors
tongue-flux-v2.1.safetensors
tongue-flux-v2.1.safetensors
Female Tongue, Mouth and Teeth v2.1 - Flux1D.safetensors
Female Tongue, Mouth and Teeth v2.1 - Flux1D.safetensors
Female Tongue, Mouth and Teeth v2.1 - Flux1D.safetensors
Female Tongue, Mouth and Teeth v2.1 - Flux1D.safetensors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.