Imported into Civitai from https://rentry.org/LazyDAdaptationGuide
This guide is a repository for testing and tweaking DAdaptation V3 LoRAs, introduced by Kohya on 05/25/2023 .
For reference to my guide on collating a dataset, and the old method of utilizing the
AdamW8Bit optimizer, see - https://rentry.org/lazytrainingguide
Useful links:
Kohya - https://github.com/kohya-ss/sd-scripts
bmaltais training GUI (Dreambooth localhost, DADAPT V3 HAS NOW BEEN IMPLEMENTED) - https://github.com/bmaltais/kohya_ss
With the inclusion of DADAPT V3 into bmailtais, I have provided a .json via https://files.catbox.moe/8yh7ko.json - edit your img folders, max epochs, dim/alpha, weight decay etc.
DAdaptation is an adaptive optimizer that automatically selects and tweaks the TE/UNET/LR values as it trains.
I have spent the past few months tweaking the older DAdaptation implementation (Assumingly 1.5) via the derriandestro repo. With the release of V3 and other versions of the DAdaptation optimizer, I firmly believe that this is the best optimizer to use and oust AdamW8Bit as the default optimizer.
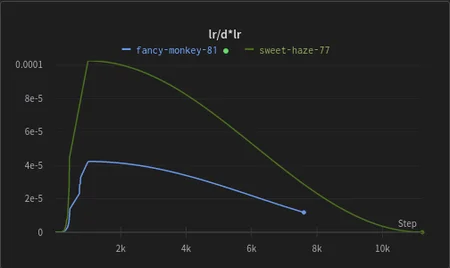
Here is an example of the shift in learning rates between DAdapt V2 (green) and DAdapt V3 (blue) - in general, it's less heavy in blasting out a higher learning rate and cooking the image faster, meaning we can keep the weight decay lower than previously practiced:
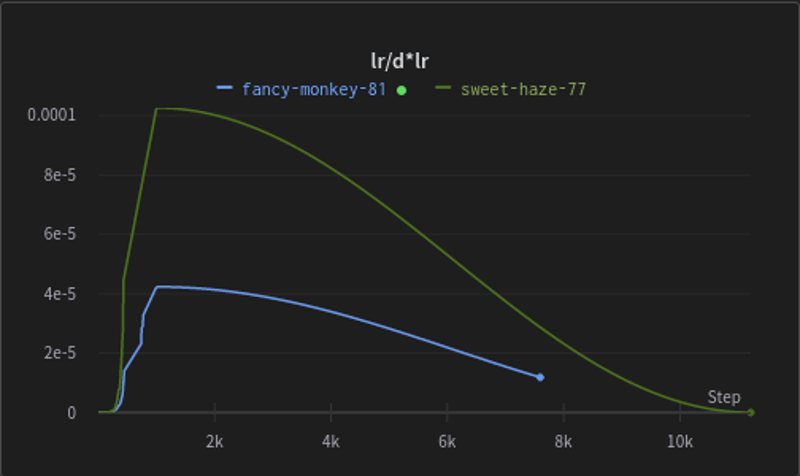
DAdaptation removes the need for setting restarts, setting learning rates, text encoders, unet learning rates etc. Simply put, you can flick a switch and it will generate your LoRA with minimal effort.
DAdapt can be used for all LoRAs. Characters, concepts, artist, style etc.
DAdapt needs a higher 'weight decay' value, as expressed in the research data and the LoRA results. This is the primary method for tweaking your LoRA. Is your LoRA not learning enough before it overfits? Increase the weight decay in .1 increments. With the release of V3, it seems to blast the learning rate a lot less heavily than V1.5 or 2, and so we can usually get away with reducing the weight decay more than we used to for the previous interations of the optimizer.
DAdapt should have the learning rate, text encoder and unet learning rate set anywhere from 0.5 to 1. This is personal preference, but I've found keeping it at '1' and tweaking the weight decay is the simplest method of fine-tuning training.
DAdapt needs the argument --optimizer_args "decouple=True" setting along with the weight decay settings (for example): "weight_decay=0.4" "betas=0.9,0.99"
This can be done in the Bmaltais Kohya GUI through the parameters boxes.
Here are a few of the settings I have confirmed work well:
Learning Rate (LR) 1
Text Encoder (TE) 1
UNET 1
Weight Decay (WD) - From 0.2-1 - will require longer training to learn more, but FAR less prone to overfitting
Repeats 1 for each data subfolder - Allows for tweaking of steps via epochs and removes the need to do math
Resolution 512 - DAdapt is a heavier train and needs better hardware. 768 is not worth it
Clip Skip 2 - For NAI based models
Training Model NAI
Scheduler Cosine - Constant is not good, and I'm not sure why it was originally recommended for DAdaptation
Batch Size - As high as you can go for your hardware. For example, 6 for a 3060 - From my experience it's better to set this and forget it, and focus on more impactful settings for training
Epochs - Set it as high as you want. As an example, I have tested a 36 image, 3 character LoRA. This started to burn out at around 230 epochs at weight decay 0.4 totalling around 2400 steps at batch 6 - Once again, DAdapt needs more steps to achieve results as we're actively hampering the learning through decay
DIM32 - (or set it lower to '8' for example, increase training time/reduce weight decay)
Alpha16 - (match the DIM if set to 8 or lower)
Warmups - Relatively untested, but I just set it to 0.1 to give it a bit of time to calibrate (?) - set warmups to 0 if you're using the above .json and the "growth_rate=1.02\" argument
How many training steps for my LoRA? - Final steps are divisible by your batch - for example, at batch 6, for a single character LoRA on DAdaptation I would probably expect anywhere from 600-1200 steps. Generally, training til overfitting and going back down the epochs will save needing to re-train the LoRA all over again with new settings
Examples:
XYZ plot starting at 100 epochs, up to 234 - 1/1/1 TE/UNET/LR, 0.4 weight decay, 0.1 warmup steps - training at batch 6 totalling around 2,400 steps
Note that these are trained on a tiny dataset of 12 images per character with one outfit, and should not be a representation of the plability of character clothing, positions etc.

LoRA trained on 3 characters, example tags:
Aru - Aru, long hair, breasts, bangs, shirt, gloves, ribbon, yellow eyes, white shirt, pink hair, horns, collard shirt, red ribbon, coat, blunt bangs, fur-trimmed coat, halo
Shiroko - Shiroko, long hair, breasts, bangs, blue eyes, animal ears, animal ear fluff, mismatched pupils, cross hair ornament, blue scarf, grey hair, halo
Karin (Bunny) - Karin, large breasts, black hair, halo, animal ears, cleavage, hair between eyes, fake animal hears, playboy bunny, rabbit tail, yellow eyes, very long hair, dark skin
(The final epoch version has been uploaded to this Civitai post)
Example .safetensors -
Final Epoch - https://files.catbox.moe/muah1o.safetensors
200 - https://files.catbox.moe/luvylf.safetensors
180 - https://files.catbox.moe/xkemzm.safetensors
160 - https://files.catbox.moe/ane6p6.safetensors
140 - https://files.catbox.moe/frshlg.safetensors
120 - https://files.catbox.moe/47hsmp.safetensors
100 - https://files.catbox.moe/qgbxs9.safetensors