

















Stabilizer
Name is misleading. This is NOT a LoRA that can magically fix your overfitted merged base model.
This is a finetuned model from pretrained model. But trained as a LoRA.
11k images. No bias, no default style.
Zero smooth plastic glossy AI image in dataset. Glossy Al images are polluting the world, but not on my watch, I handpicked every single image.
Natural language captions from Gemini, rather than tags in random order with high FPR.
Standard noise scheduler. Inpainting/img2img friendly.
Improvements:
You can get the style exactly as it should be (as long as the model knows).
Comparisons with pretrained base model:
https://civarchive.com/images/84145167 (general styles, you get the style exactly as it should be)
https://civarchive.com/images/84256995 (artist styles, no style shifting because this model does not have bias)
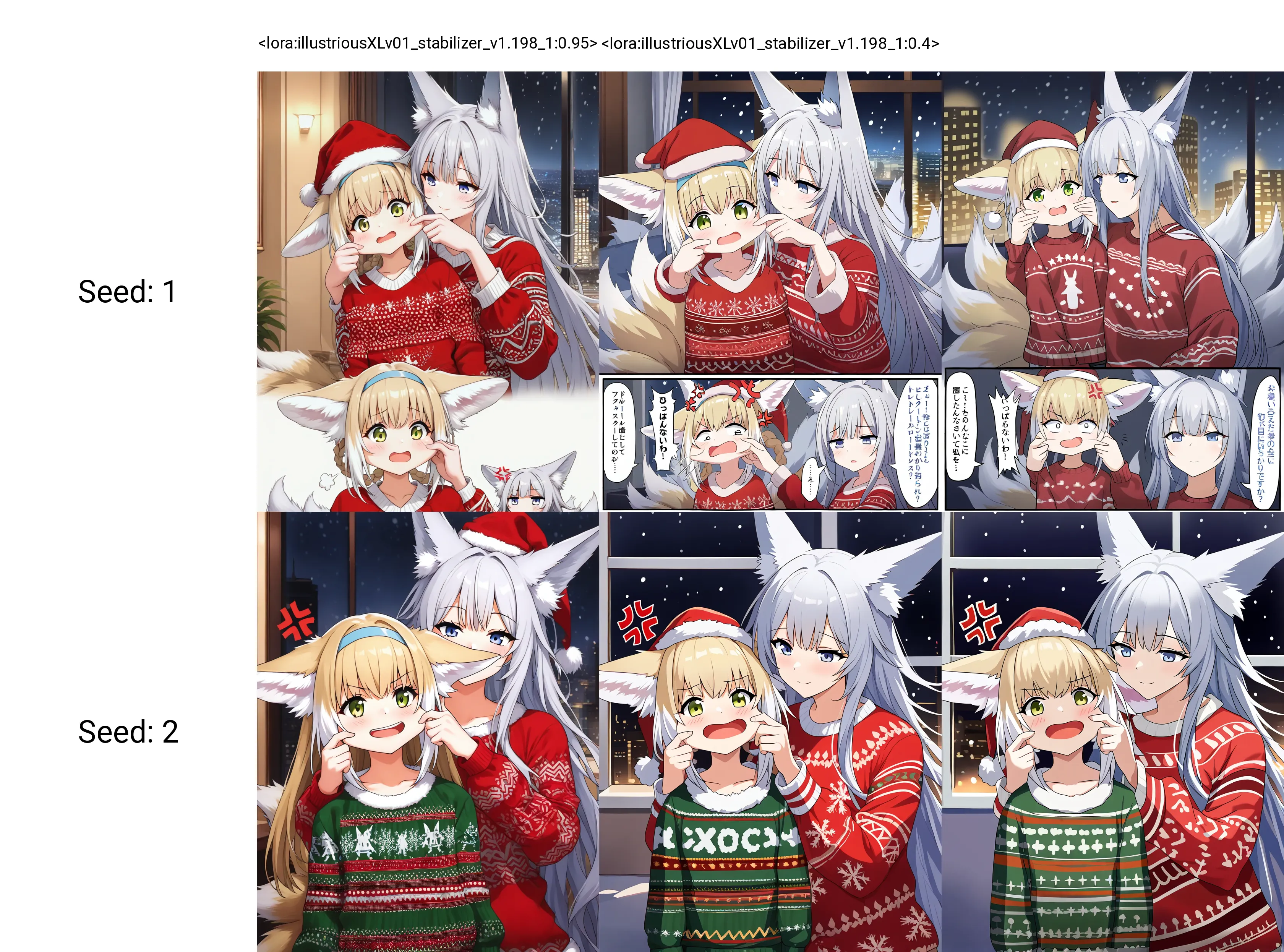
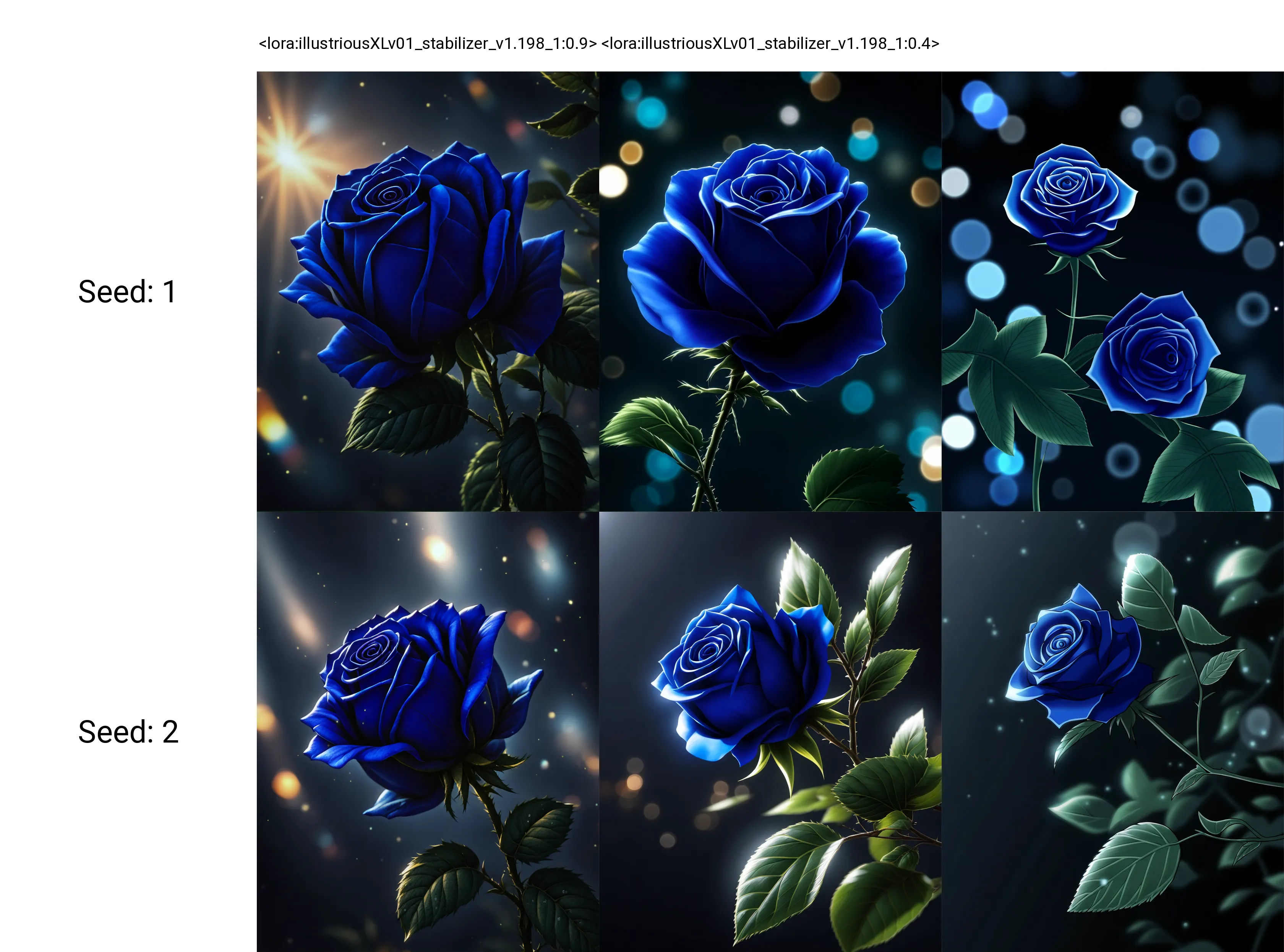
See more xy plots in cover images.
Why LoRA?
This LoRA is a DoRA (from Nvidia), which is more efficient than traditional LoRA.
Enough for thousands of training images.
What? You prefer to download and store a 7GiB checkpoint than a 80Mib LoRA?
Share merges using this model is prohibited. FYI, there are hidden trigger words to print invisible watermark. I coded the watermark and detector myself. I don't want to use it, but I can.
This model only published on Civitiai and TensorArt. If you see "me" and this sentence in other platforms, all those are fake and the platform you are using is a pirate platform.
How to use
It is highly recommended that you use pretrained base model.
And load this LoRA with strength 1.
Versions:
cknb (ChenkinNoob-XL).
nbvp10 (NoobAI v-pred v1.0). FYI: you don't need CFG hacks (RescaleCFG etc.).
nbep10 (NoobAI eps v1.0).
illus01 (Illustrious v0.1).
Load this LoRA first
This LoRA uses a new arch called DoRA from Nvidia, more efficient than traditional LoRA. But the patch weight is dynamically calculated based on the currently loaded base model weights (which will be changed when you loading other LoRAs). To avoid unexpected changes, load this LoRA first.
Specify styles in prompt
This model does not have an strong default style and is very creative. You must specify the style you want in the prompt.
If you want to use it on finetuned/merged base models:
I personally disagree this. This is not the model's original intention. But this is a LoRA after all.
Be aware:
This LoRA can't remove glossy shiny plastic AI style. Although the dataset is "AI image free". It can't make AI image polluted 1girl overfitted 50 versions of Nova furry 3D anime WAI or whatever look better. What the model learned is learned. Use a pretrained base model if you want to get rid of overfitted AI style.
What is "overfitted AI style"? This is what Craft Lawrence (from spice and wolf) should be, if you've seen the anime: img. This is what those AI style polluted 1girl overfitted model generated: img
Some base models already merged this model. If you got deformed images with this LoRA even at low strength (e.g. <0.5). Your base model has already merged this LoRA (and you merged it twice). And the model weights got multiplied (because how the DoRA works) and collapsed.
Beware of fake base model creators, aka. thieves. Some "creators" never do the training, they only grab other people's models, merge them, wipe all metadata and credits, and sell it as their own base model.
Update log
Moved here
Description
FAQ
Comments (29)
did some light testing comparing illus01 v1.185c at 0.6 strength VS illus01 v1.198 at 0.8 strength
and it seems like v1.198 is a nice improvement over v1.185c
the biggest difference I noticed from my short testing is the skin on 3d styles are a whole lot better on v1.198 compared to v1.185c which is very nice and maybe the lighting but I need to do more testing to confirm
thank you again for posting good stuff and while it's kind of sad to see the development of illus01 and noob are coming to an end but I hope Chroma treats you well
thank you for coming to my Ted talk
v1.198 is really good. straight up improves anatomy and quality of the pictures. But noticed that it keeps adding random noise to the background and my indoors pictures end p always having bunch of potted plants and paintings on the walls in comparison to not having this lora. That is the one thing i would like to see improved more in the future if anything before you move on completely.
not sure about potted plants, I don't think my dataset has such high bias towards that. But the paintings on wall are from the "masterpiece". I also just noticed this issue recently. If you use "masterpiece" in original SDXL, you will get a art painting on wall.
This LoRA can hint the model to generate a complex background, but the content mainly depends on the base model itself.
yes pretty much.
What resolution are you using for the initial images?
always 1MP, SDXL detault
After a short 30mins test, 198 has better overall anatomy improvement, but i feel like the hair and nipple texture in 198 is a bit less "lively and smooth" than 185c.
198 also seems to not following the prompt as 185c, i put "white background, simple background" in positve and "detailed background" in negative but 198 still creates background, which never happened with 185c.
Both were tested with 0.6 weight, result might differ with other weight settings.
https://civitai.com/models/1777579?modelVersionId=2060407
try this lora, it contains a dataset i removed from 185c.
background: for better anatomy in v1.198 I removed all simple background imgs, and also finetuned it again with super complex background.
If this a big issue, you can skip this LoRA during early sampling steps (20%)
there's a really nice semi-realistic skin and hair shading/style present at higher weights in versions 164 and older that is no longer present in more recent versions, would it be possible to get that added back in or available separately if you know what was causing it?
keen eyes.
Yeah I dropped a realistic + semi-realistic dataset since v1.164, mostly because it causes 2D anime characters feeling too realistic, which is not ideal.
follow this page for updates
https://civitai.com/models/1777579/style-collection
I think I understand why the C version of this isn't really stable, somehow affected the hair prompt of mine to the point it was useless (Yes, I am talking about the latest version of stabilizer right the time of me writing this, didn't notice the C part was gone)
which base model and LoRAs were you using?
Although c versions are gone, I'm still curious about it's performance and why it effects some models so much.
If you can post an image with metadata that would be really nice.
reakaakasky I'll send when I have the time, but I use Nova anime xl v9 and only used this lora, and the hair prompt in question was hard enough without using the latest lora of this, might be a niche of mine
Noxy_ I think it is because "Nova anime xl v9" was trained on AI images (or merged with AI styles). You can notice the hair style in this model, same as all other Al style models, is super overfitted. The top part of the head.
reakaakasky Makes sense, does look really AI ish style but I did fix my hair prompt by changing it slightly (more descriptive)
You know any good anime models that aren't overfitted AI styles? (for the models currently popular right now) It's kind of hard guessing which has which
you can try furry models, not joke, from my testing most furry models do not have obvious overfitting effects, like fixed hair style and face.
reakaakasky Ah, that's surprising, thanks!
I often struggled with the overly simplistic composition and colors of artist-style images generated by Stable Diffusion, and even using high-definition restoration yielded minimal improvement—until I tried this LoRA. Now, my noob-v prediction model feels valuable again!
How do you exactly change seed for the lora?
If I'm not mistaken they're showing the normal generation seed. It can take any number that's why they're showing seed "1" and "2".
EarNugget2 is right, its just generation seed, and the images you saw are from good old a1111 that not popular anymore.I just too lazy to draw xy plot in comfyui
This is great. Thank you for making this :)
Updated description
+ why and how this LoRA works.
+ why AI styles are problematic.
Can you train a version for Noob v-pred?
The current versions don't work with noob vpred models unless you disable certain model weight layers in the lora related to lighting and color, which causes other issues.
Right now it causes bright lighting explosions and significant artifacts. I really want to see a version for noob vpred that fixes it while not causing lighting to explode.
I like this lora and what it does for EPS models, and I want that for vpred too, but I honestly like having proper lighting in scenes.
tried, several times, but didn't meet my expectations (not as good as eps), so I gave up
我在最受欢迎的lora里找不到这个lora了,这是怎么回事?我以为被删除了,通过下载历史回到了这里
This is awesome, thanks. Do you recommend leaving the negative prompt blank as in your example images? I do seem to get better results when trimming down my negative prompt to a couple of basic tags.
yes, I recommend only use neg prompt when you really need to remove very specific things. Also only enable neg prompt in early sampling steps (~50%)
because neg prompt is a hack during sampling, not a solution. And the cost is stability and details.
reakaakasky Thanks
Details
Files
illustriousXLv01_stabilizer_v1.198.safetensors
Mirrors
126_stabilizer.safetensors
stabilizer_v1.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
illustriousXLv01_stabilizer_v1.198.safetensors
stabilizer-il-nai-ck.safetensors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.