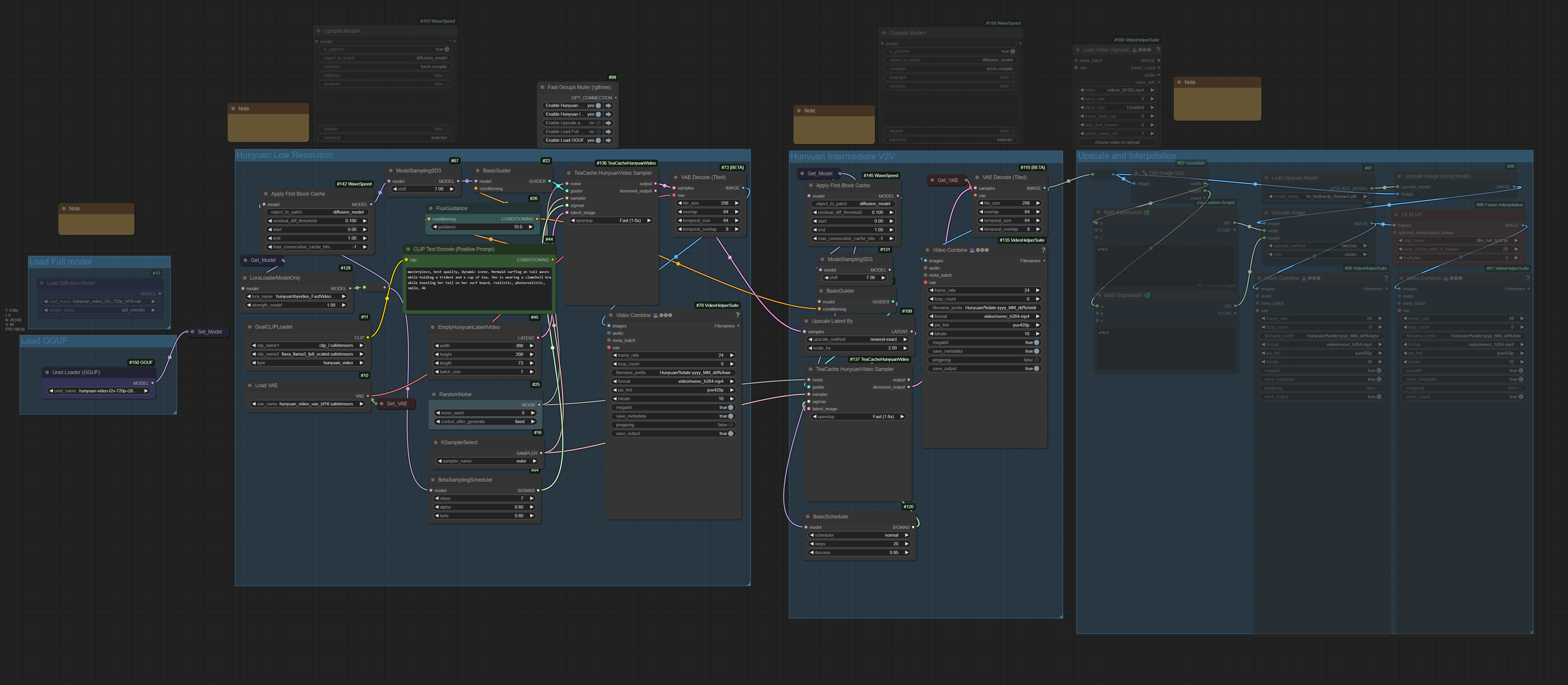
Workflow for Hunyuan video that can generate a small resolution video first very quickly, then upscales it with Hunyuan v2v when you find one you like. There is a third step for upscaling and video interpolation.
Version 1.5 uses the fast video lora to generate the first video in 7 steps, significantly increasing the speed of the first generation without compromising the second.
Version 1.6 uses a TeaCache sampler to increase generation speed by 1.6 and optionally by 2.1 with worse quality.
Version 1.7 adds Wavespeed, which has increased speed for me by about 15 %. To use it you will need to clone the wavespeed repo in custom nodes. Some wavespeed functionality requires installing triton, but if you only use the "Apply first block cache" node you may not need it.
If you already have a video you simply want to upscale, you can connect the muted load video node to the top left connection in the "Upscale and Interpolation" group and mute the previous 2.
This is just the application of some tips from this article with already available workflows.
This is not intended as tutorial on Hunyuan video, please check out the links above.
Description
FAQ
Comments (84)
Hello,
Does anyone know how to address the following missing node types?
ApplyFBCacheOnModel
EnhancedCompileModel
For some reason, the ComfyUI manager cannot find them, and my search on the web/Civitai hasn't been successful.
Thanks for any help!
The wavespeed nodes aren't in the manager for some reason. Clone this repo into the custom_nodes folder: https://github.com/chengzeyi/Comfy-WaveSpeed
@bonetrousers Great work on the workflow you've created, and thank you very much for your prompt response. It's greatly appreciated!
I somehow get better detail in the low rez version(maybe because it's not people).
Also, "it's a pain in the ass to set everything up" - I haven't installed triton, but wavespeed worked well. Am I missing anything?
How much denoise are you using in the upscaled step? For me, anything below 0.85 keeps the low res quality from the first step.
Maybe triton is only necessary for the compile model node, which I ended up not using. I'll ammend the description.
The VAE Decode (Tiled) currently has two options for me: tile_size and overlap. It should have four options, including temporal_size and temporal_overlap. How can I achieve this? I suspect my nodes are not from the correct source (Comfy Core BETA).
I think Comfy Core Beta is right, have you tried updating?
@bonetrousers Thanks a lot it was indeed an update issue, fresh install solve it.
@bonetrousers Sorry to bother you again, but I thought the video duration was set using the temporal_size and temporal_overlap. I doubled both values to change the video duration from 3s to 6s, but it didn't work. Could you please let me know where the video duration is actually set?
@plstable130 It's the length parameter in the "EmtyHunyuanLatentVideo" node. That sets the number of frames, and hunyuan generates at 24 fps, so if you want 3 second videos, you need to generate 3*24+1=73 frames.
May I ask the purpose of the math expression instead of using "upscale by"? Just trying to limit the amount of random nodes used, and wondered if this could be used without them?
I didn't think to look for an upscale by node. Makes sense that one exists 😂. Feel free to change it and I'll simplify it if I do more versions.
Hello, firstly great work, but i do have a issue, when i run the first pass (7 steps block) it runs fine, but when it gets to the second pass (20 steps block) my screen starts to stutter and when i look at VRAM usage it is going from 11gb to 12gb and back to 11gb again, as if it didnt clear what wasnt needed from the last pass or it is trying to load a new copy for the new pass, any ideias?
Also im running ComfyUI with ROCM in a 6700XT
I haven't optimized the workflow for 12 GB, but you should try using the quantized GGUF version of the model, decreasing the resolution and/or decreasing the length. You can also check out other workflows here on Civitai that focus on lowering VRAM.
@bonetrousers thanks for the reply, i will explore more, i tested the upscale and interpolation section by disabling the second pass and it works, something about memory management is messed up when it reaches there, i think it is related to ROCM
Mixing this with MMAudio is incredibly cool!
Rip my entire day getting Torch 2.5.0 running for it though, but super worth it!
That looks pretty neat! Will check it out.
odd, I'm getting this error:
"Missing Node Types
When loading the graph, the following node types were not found
GetNode
SetNode"
and yet, I have nothing else to install from the missing nodes
They are from KJNodes: https://github.com/kijai/ComfyUI-KJNodes. I think they should be in the manager.
@bonetrousers Odd. they were already installed indeed. I just re-ran the installation instructions, even though it already seemed to be installed, and that fixed it. Thanks!
How come there's no mention of what model is required? Comfy threw an error so I had to Google "hunyuan-video-t2v-720p-Q5_K_M.gguf" to find it. It might be helpful to add a note about it in the description with a link.
Any hunyuan gguf Model would work here, and if you change the nodes you could use any other hunyuan model here. Comfyui can have a learning curve, and lots of new nodes that don’t always work together but it’s good to follow the error reports as you have done
Anyone have a clue how to cut the workflow VRAM a little bit more?
At the moment it would fit perfectly into my 12 GB of VRAM if it wasn't the windows overhead pushing it just over, meaning that it falls into RAM and speeds also fall of a cliff because of it
EDIT: I was not using the GGUF model. I highly recommend the GGUF as it is much faster
how do I go about adding a lora to this. where do I connect the nodes to for the 'Load Lora', sorry this is new for me.
Use the node "LoraLoaderModelOnly", add just after loading the hunyuan model, before the set_model node.
@bonetrousers awesome, I got it to work after some experimenting. great work!
I'm getting an out of memory error on the 2nd pass with v1.7 using the gguf model even though I was able to run 1.6 using the full model very smoothly. Any ideas on where to troubleshoot? The error is:
"TeaCacheHunyuanVideoSampler_FOK
Allocation on device"
Thanks
Edit: I tried running with the Load Full Model option instead of GGUF just for the sake of testing and am getting the same OOM error.
Sounds like wavespeed may be using more vram, try muting the apply first block cache node and see if it works again.
@bonetrousers It seems to work fine for the first pass once that node is muted. Is there a way to tame the vram usage for wavespeed? I'm running a 4070 12 gb.
Edit: I realize you may have meant bypass instead of mute? I was able to get this version to run by bypassing both the apply first block cache nodes and using the full model. After some searching it looks like my lack of Triton may be the issue. I'll try installing this and see if it works.
will this work for amd cards with 8gb vram?
I think it would be tough. You would need to use a quantized gguf version of the hunyuan model, limit the upscaled resolution and video length, and possibly remove the fast lora.
Hey, sorry for needing troubleshooting help. I like the interpolation feature. If I put an old video in the "Load Video" box, I drag a line between "IMAGE" and the green dot of the Reroute right at the beginning of the third box. But then it says it can't get the images or the image size. Is there something else I'm supposed to be connecting here?
You should only need to connect the images, but I guess there may be an incompatible resolution after the math. Someone in another comment already pointed out that there is a simpler way to upscale that may also solve your problem. Try substituting the "upscale image" node by an "upscale image by" node. I bet it ensures the resolutions are valid internally.
@bonetrousers Thanks, I'll give it a try :)
@bonetrousers Naturally it worked on the first try today. I guess it just needed a system restart lol. Thanks for the help :)
In case anyone has this question in the future, I'm about 90% sure I found what my problem was. I disabled the first and second sections, leaving just the interpolation section open. When I unmuted the "Load Video" box, it flipped the second box to "on" and my guess is that I turned it off again, which muted the "Load Video" box again.
why is the picture so much different in my first and second blocks? in the first one, I have a more or less realistic image, in the second the purest anime? Do I need to add Lora to the second block?
If you add a lora, make sure you place it before the set model node so that it's used in both steps. Also I use a default denoise of 0.85 to get better quality videos, but it tends to make significant changes, try lowering it a bit.
@bonetrousers thank you
Can you show how it supposed to be linked, however i try, it stops on second group
At the top there's a node that let's you toggle on or off which blocks you want to use.
Updated everything, installed all nodes but still getting a fault on ApplyFBCacheOnModel.
invalid prompt: {'type': 'invalid_prompt', 'message': 'Cannot execute because a node is missing the class_type property.', 'details': "Node ID '#142'", 'extra_info': {}}
in terminal goto custom_nodes directory in comfyui then:
git clone https://github.com/chengzeyi/Comfy-WaveSpeed.git
make sure to reset comfyui after.
@freelake611 Cheers
Hi, thanks for this. I'm wondering if there would be a way to generate multiple low-res videos and then do the mid-resolution HV V2V on the best? I feel like the easiest way would be caching the latents from the low-res T2V to disk, and then reloading the best.
This may not work, but I think you could set up several samplers in parallel generating videos with different seeds in the first step. If you see one you like, you upscale that one only. Maybe using some sort of selector with a user selected index or something.
Personally, I think that it is more expedient to queue up several runs at a time, check likely candidates and accept the time loss of regenerating the first step.
@bonetrousers Thanks. What I'm doing for now is using SaveLatent and LoadLatent nodes which is a bit janky because I have to move the latent I want to inputs/, but it's not too bad. So your strategy is to set the random seed that gave you a good low res?
@logenninefingers888 Forgot to add that since all generated videos have the workflow embedded in them, you can just drag the ones you like into comfyui, enable the second step and add them to the queue. With a click/drag plus 2 clicks, you can do it pretty fast too. This way you don't need to remember seeds or prompts.
im a beginner with a 4070 and it took 35 mins to generate. what settings would you recommend tweaking?
I'm guessing your issue is VRAM. Use a quantized gguf model instead of the full one, reduce the length and resolution of the video. Use task manager or whatever to check on vram use and try to make sure that everything fits into dedicated GPU memory.
@bonetrousers Hi, I have a question: how long should the surfing video take on average to generate? with a 4070? or a 4090, is there a difference?
@The1up Besides computing power, the big difference is the VRAM. An RTX 4070 has 12 GB, and a 4090 has 24. If you can't fit the model and video into vram, you either get an out of memory error or generation speed slows down to a crawl as data goes back and forth between vram and system ram.
Also try turning down the VAE Decode Tile Node to tile_size 128 overlap 32
Can you recommend settings for high-quality 2D video generation? I only get ugly women in 3D((
Most people embed their workflows into the videos they generate, so I suggest you find a post you like, drag it into ComfyUI and experiment with the prompts until you get what you're after.
Also, if you are looking for specific styles, there may be loras that get you there.
Im big newbie, i learn comfyui (i was on automatic before). Im curious about how long for you is the render of the second box. I've got a 3090 and the render was around 10 minutes for V2V boxes. It's normal ? There is a way to make it faster or i shoudln't touche anything. I don't know if i did any shit on my workplace
With a 4090 it takes me about 4 minutes to generate an upscaled video. So roughly, it seems to check out.
@bonetrousers im rocking a 4090 as well but cannot get past V2V, first generation takes about 60 seconds but slows to a crawl on v2v, more than 30 minutes with little progress
any tips?
@DiffusionArchive Monitor your VRAM, make sure that you don't go over 24 GB. If you do, lower the resolution or the length of the video.
Hello. ComfyUI is saying I'm missing four nodes:
- GetNode
- SetNode
- ApplyFBCacheOnModel
- EnhancedCompileModel
Does anyone have any advice on where I can find these?
The first 2 are from kijai nodes, the 3rd one (and probably the 4th) are from wavespeed.
@bonetrousers Thank you!
For ApplyFBCacheOnModel Comfy-WaveSpeed
Please make an update with LeapFusion img2vid lora
ModelSamplingSD3 in bad position and does nothing! It should be right after lora(s)!!!
also with 2 separate noise generation it creates so much nicer vids in v2v section!
noted!
@matecs hello, excuse me! could u explain it more ? i dont understand "also with 2 separate noise generation".... thank you
@a7873572426 Yes, I'd also like to know.
There's a significant speed bump from 1.6 to 1.7v and GGUF, 64sec to run the first low generation for a 720x416 resolution. My problem start when I start the second step (Mid-resolution) with the same resolution and 129 frames, takes from 1.5Hours+ to generate (maybe I'm pushing too hard), My question is, what would be your recommended initial resolution for a "cinematic" shot or widescreen, (and later upscale by.. 2x?), and what resolution for portrait. Taking advantage of your attention, I'm also facing the issue that mid-resolution is completely different from the Low resolution, I confirm I'm loading my Lora right after the Model, just before "Set Model", I tried with gguf and t2v_720p_bf16. with the same result. T2V is faster for me, Thanks sharing!
I'm not following what you mean. I usually set a 368 by 208 initial resolution, then it gets upscaled by 2 in the second step (736 x 416) and the last interpolation step upscales it by 8/3, making it roughly 1080p.
You are starting with double the width and height, so it's no wonder that your generations are taking that long.
Best T2V workflow I've seen so far
hi, i love your workflow, i don,t know why the node **film vfi** in the part upscale don,t work, thanks you!
It should pop up in the manager, either "ComfyUI-frame-interpolation" or just "frame-interpolation".
I have it enabled, but when I start to work it gives me an error and I had to bypass it.
Please make Wan 2.1 version!
I just did! https://civitai.com/models/1346393
@bonetrousers You the man, you the man.
Am I the only one having problems with nvenc in Runpod??
If anybody discovers this - contact the Runpod support and ask for Roman. He found an awesome solution for me.
Thak you I have been looking for a good workflow for Hunyuan and this is great and worth the time to set up
can you give me a WFi can add two loras