








Actually played with it and found
This model actually depicts on a 5x5 grid, and the attention is split on the 5x5 lines.
Behold, the rule of 3 is broken with this model. Long live the rule of 5.
This is the first Flux model I've seen with bottom-line 5x5 split attention control.
Update - V1512 is released: 2/15/2025
I'm doing an early release due to needing at least a few days to develop the captioning software to create the next version iteration; and I simply do not have the time of day.
I'm releasing mostly because of the discovery with Hunyuan, and I'm also releasing a working Hunyuan merge with Simulacrum Schnell that produces very fun stuff... and it really shouldn't.
This version's core features;
does not require negative prompting
works with Flux1S models
works with Hunyuan -> throws some errors just ignore them
works with the various clip_l_omega versions
unfinished, but far more robust
tons of nsfw depiction and control
absolute ton of spatial understand and entirely new methods of reasoning for the model to understand it
up to 20 identifiable characters simultaneously per image, this was not done yet so the outcomes are very hit or miss at times.
Grid and screen depiction control baked into the core.
Full comics on request, also wasn't done yet.
Tremendous amount of outfits, screen control, truncated sectioning, grid control, rotation control, offset control, size control, and even more; hit or miss due to not being completely trained yet.
Configuration:
Load using the CLIP_24_L_OMEGA for full effect, as this version of Simulacrum Schnell was heavily trained using the post SDXL CLIP_L version.
I'm uncertain if this CLIP_L is the exact same version, but it's definitely pretty similar if it isn't and should work with other versions of CLIP_L omega.
For Flux 1S
Positive prompt is plain English peppered with booru tags, and then use booru tags as solidifiers later on.
Prompt using a mix of styles, offsets, whatever. Just talk to the thing, it'll probably understand what you want. I gave it additional intelligence for many sectors in the human world.
Whatever you do, don't put anything into the prompt that you don't want to see. It is much more intelligent and more literal than it's Flux counterpart.
This is NOT Flux how you know it. It's far more unchained and far more flexible.
There's a reason why these things take so long to come out, and you'll see it here if you play with it too much.
This thing IS DEFINITELY NOT a safe model, nor is it meant for all ages. It was never given a full controlled polish finetune for v2, so it will produce what you want, and you WILL get the monkey paw with it.
This is NOT Schnell. This is finetuned so heavily that it barely reflects the original at times, and other times it's basically base Schnell
Be VERY WARY. You WILL see monsters.
Positive Prompt TLDR:
<setting, placement, location, situation>
<context caption>
<quality><styles...>
<subject counts>
<action caption>
add outfits, clothing, interactions, whatever here
masterpiece, most aesthetic, very aesthetic,
<superimposed captions>
<t5 captions for UI and overlays>
Mix and match these for negative;
Negative Prompt TLDR:
sex, nsfw, explicit, questionable, safe,
anime, 3d, realistic,
line drawing, digital artwork,
interpolated frame, blurry, grid_, depicted-, size_, behind, side, front,
bad anatomy, bad hands, mutated, extra limbs, missing limbs, amputee, quadruple amputee, blood, gore, guro,
humanoid, anthro, furry, censored, uncensored,
lowres, good aesthetic, very displeasing, disgusting, Steps: 12-58 -> 32
CFG: 2.5-9 -> 3.5
DCFG: 0 (flux guidance)
Samplers:
Euler -> Simple
DPM-2M -> Beta/Simple
DPM-2S -> Beta/Simple
DEIS -> SGM Uniform <<< Just found it, so good.
Resolutions:
1308x1308 (really close to this can't remember), very big.
1216x1216, 1216x832, 832x1216
1024x1024
1024x832, 832x1024, 832x832
768x768
512x512, 512x768, 768x512
For Hunyuan
It's not the easiest setup yet.
This wasn't TRAINED for Hunyuan, but the next version WILL BE trained for Hunyuan. Direct Hunyuan interpolation control.
However, this thing works for some reason and I still haven't figured out why.
Steps: 12-64 ->
12 works okay, but it tends to get blurry or pixelated
24 works probably the best but takes a while with many frames
Frames:
65-200
I did most of my testing around 130 or so, so don't think this is a strict rule.
CFG:
3.5 - 9
They all produce interesting outcome. 9 is actually really good sometimes.
My go-to is 6.4
LORA STRENGTH:
You will likely need two or three lora loader nodes to make it work, but it does work.
- Single Blocks 0.80
- Double Blocks 0.20
- CLIP - 1.0Consult the SDXL-Tag Guide for a full list of trained bbox data.
Interpolative video training data used for 3d and realistic.
Update - V2 is still brewing : 2/6/2025
I've turned up the NSFW knob and broke it off. If this thing doesn't produce high grade high complexity NSFW I'll be shocked.
It'll probably take another week of cooking to fully reach maturation, so bare with the time.
Update - V2 is brewing :1/30/2025
V2 will not need a negative prompt. I've been running the same data that I ran through SDXL for an epoch to see what it'll do. It's already starting to take, and the need for a negative prompt is going away rapidly.
It's about 300,000 or so images, roughly a third with plain English prompts.
So either the 5x5 grid will work, or the model will burn to a crisp.
It's attached to CLIP_L OMEGA V4, so be aware it'll behave a little... a little differently than you expect compared to the first version. This CLIP_L is 10 million samples smarter.
I made everything so you can download it while you aren't logged in, so no login validation or keys required to auto-download it.
As of V129 DEPICTION OFFSET works in a substantial way. Experimentation required.
I can officially declare V122 ADVANCED PROMPT GRADE NSFW. You should be able to create the majority of common NSFW related acts and detailed situations with the current released version. I fed 1D these exact images in MULTIPLE epochs and it laughed at me.
The further along the training goes, the more plain English depiction it'll be able to handle. Currently this is not a simple process, but you can work it out if you give it a bit of elbow grease.
I'll be writing three articles soon based on using this model, because it's quite different than Flux1D and it's VERY VERY underestimated. The power here is substantial and responsive to training, while Flux1D often fell apart during training.
Simple Schnell subject fixation using the rule of 3
Complex scene interactions and careful caption planning for Schnell NSFW training
Prompting NSFW interactions and adult depictions with Simulacrum Schnell V1
I guarantee this model is far more powerful than is expected of it, and the outcomes from training are far more powerful than expected. The QUALITY is suffering a bit currently, but the additional training is showing certain traits are most definitely clearing up over time. This is only going to compound when I provide it with more training and more information for the requests.
I STRONGLY advise using "Shuttle 3 Diffusion" Schnell to inference this lora. It amplifies the capabilities a large amount with less prompting. Shuttle v3.1 is okay but doesn't work as well with this lora, it's more compliant with it's own thing.
Standard Flux Schnell FP16 and FP8 depict a FAIR QUALITY with the same settings now that we've hit Epoch 5/10. Many details that Shuttle 3 Diffusion is hiding or replacing with it's own training appeared from the training as emergent traits in standard Schnell, while Shuttle is still hiding the effects. FP8 is a little lesser but not by much. I actually ran the first epoch on FP8 at a higher learn rate for the baeline, so it should respond pretty well with FP8. The additional 4 were on BF16 mixed training however, which makes them substantially more powerful with the BF16 and FP16 versions of Flux Schnell. I haven't tried the BF16 version yet, but I assume it's good.
Schnell FP16 requires a bit of a balancing act with prompts to make the dataset pop out, but it's not too bad. You can usually generate some fair quality stuff with a few tries and some prompt tinkering.
Be sure to use the SimV4 CLIP_L no matter which model you use, as it's required for a proper experience.
You MUST use NEGATIVE PROMPT for the full experience.
Euler -> Simple
DPM2M -> Simple
Steps 28
CFG 3.5V122 Epoch 5 - Generation Settings:
The model .safetensors says e4 but I mislabeled it. It's definitely e5.
Inference:
1024x1024, 1216x832, 832x1216
1216x1216,
1024x768, 768x1024,
768x512, 512x768,
768x832, 832x768
rule34.xxx and rule34.us tags for 3d.
danbooru/gelbooru tags for anime.
plain English for realistic.
Nothing special REQUIRED for positive prompt, but these do help.
Positive Prompt:
anime, realistic, real, 3d \(artwork\), 3d,
<CAPTION HERE>
very aesthetic, aesthetic, masterpiece
#########################################
### BASE SCHNELL FP16 Negative Prompt ###
#########################################
censored, censor, bar censor, blur censor,
lowres, bad quality, low quality, bad anatomy,
blur, depth of field, distorted, pixelated,
bad hands, blurry hands, extra digits, missing digits, missing hands, extra hands, unexplained hands, merging,
penis, erection, sex toy, dildo, pussy, cameltoe,
multi penis, deformed, mutated, monster, vore,
disembodied, floating object,
disembodied hand, disembodied foot, disembodied head,
extra feet, unexplained feet, unexplained arm, 3 legs, missing leg, missing arm,
simple background, blurry background, cave,
####################################
### SHUTTLE BF16 Negative Prompt ###
####################################
nsfw, explicit,
censored, censor, bar censor, blur censor,
lowres, bad quality, low quality,
blur, depth of field, distorted, pixelated,
monochrome, greyscale, comic, 2koma, doujin, manga,
bad hands, blurry hands, extra digits, missing digits, missing hands, extra hands, unexplained hands,
penis, erection, flaccid, pussy, cameltoe,
multi penis, deformed, mutated, monster, vore, pregnant,
cum, ejaculation, messy, unexplained white liquid,
disembodied, floating object, disembodied penis, disembodied hand, disembodied foot, disembodied head, jumping, floating, extra feet, unexplained feet, unexplained penis, unexplained arm,
simple background, blurry background, cave, The home for the Simulacrum Schnell model zoo.
The article with more detailed information about the training and process can be found here.
The Simulacrum Schnell versions require the Simulacrum V4 CLIP_L to function properly.
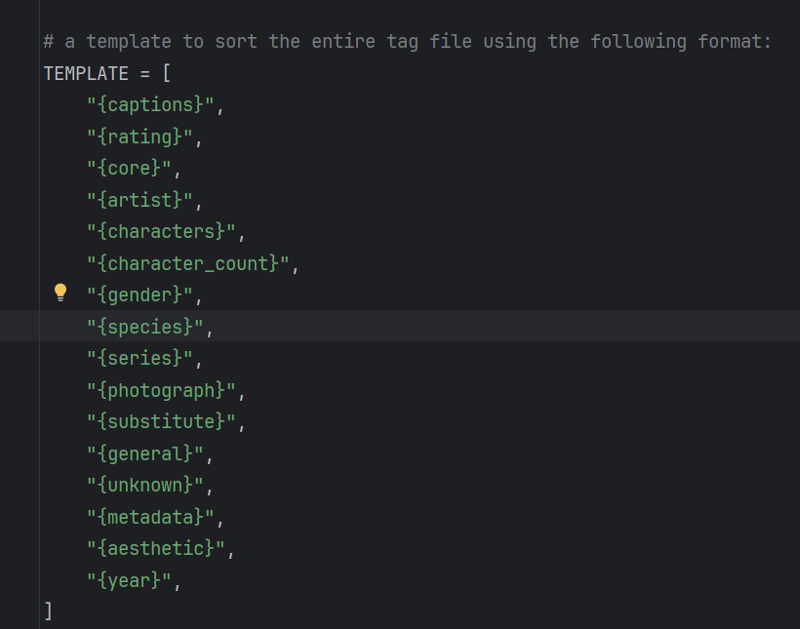
The tagging template is the same as Simulacrum V4.
Simulacrum Schnell is protected under a slightly modified Apache Open Source 2.0 license.
Copyright 2025 Abstract Powered
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this model or model zoo compliant component except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
model zoo compliant component
Any code, component, image, derived image, Schnell based ai model released unto, Schnell based AI model released as derived and trained by Abstract Powered directly posted and hosted on Huggingface, Civit, or any other legal hosting service herein.
I hereby grant this direct exception to this license:
I grant the individual, small business, influencer, researcher, research facility, research groups, and small non-corporate entity direct and free of use to inference, train, replicate, modify, alter, or derive their own personal works based on all Schnell Simulacrum versions indefinitely without monetary contribution. You are free to use this model within the constraints of applicable law within your country of residence.
Special Exceptions:
Huggingface and Civit are both exempt from this rule and can profit monetarily without contribution.
Compliance:
Corporate entities, derived corporate entities, subset business entities, and for-profit research groups, or any similar group that fits the for-profit model, are to contact me directly for commercial and monetary use unless they are exempt via the exception rules.
By downloading the Simulacrum Schnell or any of it's derivatives trained and uploaded for distribution and sharing directly by Abstract Powered, you hereby accept this license.I'm not a lawyer. Just know that my intent is for the individual, small business, and influencer to monetarily gain from this model.
Have fun everyone. I'll be posting many models.
Description
Be sure to use the SimV4 CLIP_L no matter which model you use, as it's required for a proper experience.
You MUST use NEGATIVE PROMPT for the full experience.
V12 - Attempt 2 Generation Settings:
Inference:
1024x1024, 1216x832, 832x1216
Nothing special required for positive prompt, but these do help.
Positive Prompt:
anime, realistic, real, 3d \(artwork\), 3d,
<CAPTION HERE>
very aesthetic, aesthetic, masterpiece
Negative Prompt:
nsfw, explicit,
censored, censor, bar censor, blur censor,
lowres, bad quality, low quality,
blur, depth of field, distorted, pixelated,
monochrome, greyscale, comic, 2koma, doujin, manga,
bad hands, blurry hands, extra digits, missing digits, missing hands, extra hands, unexplained hands,
penis, erection, flaccid, pussy, cameltoe,
multi penis, deformed, mutated, monster, vore, pregnant,
cum, ejaculation, messy, unexplained white liquid,
disembodied, floating object, disembodied penis, disembodied hand, disembodied foot, disembodied head, jumping, floating, extra feet, unexplained feet, unexplained penis, unexplained arm,
simple background, blurry background, cave,
Euler -> Simple
DPM2M -> Simple
Steps 28
CFG 3.5FAQ
Comments (31)
What is the function of this lora?thanks
It includes a full safe image setup, a questionable image setup, and a full nsfw sex depiction and interaction setup.
It does everything that Simulacrum V4 does or was supposed to do, but far, far, better control. So, 10s of millions of things different and more potently.
Camera angles, human control, coloration accuracy, body pose, body control, scene control, depth of field control, multi-subject control, multi-object control, offset control, outfit control, background control, and many many more things.
It's the do-all when it comes to depicting a controllable scene with humans, and it's only going to get better.
Simulate your world how you want it to be.
Oh interesting, I wonder what the "Special Training Method" that Shuttle uses for Schnell is? They haven't really elaborated much on the specifics of what they did, I mean that I've found so far just poking around anyways.
I haven't figured it out yet. I checked the settings on the V3 repo for some hints but it seems like they are just training similarly to how the original schnell upload suggests you train.
Wouldn't mind getting in touch with them to get some details on how to do a full finetune in Shuttle since they've already done it for 3.1.
@AbstractPhila ~promptly snoops through your things as one does~ Wha... 45,194... 😦
@LemonSparkle What's that mean? Is it the amount of listed steps? If so multiply that by 5 +-15000.
@AbstractPhila The number of training images O:
@LemonSparkle It was about 47500 but I took some out.
@AbstractPhila 45k images and it's still under 700mb... 🫠
Witch! xP lol
But I knew my little Schnelly had it in her after all, I just had a feeling about it ^^
@LemonSparkle It's only LEARNED from those images, they aren't actually stored in there. They are math trained dynamic responses using floats and a multitude of awkward formulas and data moving.
It's actually been trained with more than 275k now.
Soooooo, is it hardcore or what do you mean nswf?
@emricmaysin118 If you want it to be. It'll just function as a standard uncensored image model.
See the thing is, I'm teaching it everything using a generic pose dataset mixed with hagrid hands. This basically means I'm modifying it's core form and shifting it's direction, without completely obliterating the internals. I mean I AM obliterating the internals, but not in a directly detectable and noticeably damaging way due to my attention to logistics and detail.
My tested usage of this pair of datas has shown a higher context shift than anything else I've ran, so I have to include it in everything and match tags that are commonly used in my dataset to ensure they bleed over. You can't see the pose images in the metadata, because they have matching tags for this epoch and I'm not shoving all the samples from all the trainings into it every single upload.
Currently it's primarily booru tags, but they work fine with whatever plain English is used, so it can generate whatever as long as you stick to the rule of 3 for generation and use the negative prompt. Without the negative prompt, Schnell still misbehaves for now. It's getting better though.
@AbstractPhila I mean, I get it's not actually storing the images, it's using a bunch of math that would probably make me cry (and I'm not half bad at math even).... it's just training on ~70 images got me up to nearly 300mb, and my whole set was only ~106mb of pngs.
Even though I know it should be possible, with the core models being trained on billions of images but only being gigabytes in size. It's just that how there can be that much difference between stuff still makes my brain hurt sometimes lol...
@AbstractPhila Then, why isnt this in the CNN, BBC and reddit already?:)))))))))If its capable for good hardcore poses, than you made a big breakthrough.
So, what you wrote earlier about T5, that its censored, is it still and you made a bypass?
@emricmaysin118 Yes, I shattered the T5. I broke it, it only took 3 months of research to figure it out. It can generate some really insane stuff. I've been testing it's limits and I almost didn't release it.
This model is uncensored.
It's far beyond anything I've seen in the NSFW realm, and it has a tremendous powerhouse of SFW data at it's disposal too. It's a tamed monster.
I like to think of tools like this like a knife. It needs to be sharp to work. It may be dangerous, but we have to carefully choose what we cut with it.
@AbstractPhila You are genius. I dont use Flux, because of hardware, but this is big. I will link this lora to some model and people.
@emricmaysin118 Im just a hard working diligent engineer fixing problems. Ill take the complement though. :>
@AbstractPhila You promised an XL model. How its going?
@emricmaysin118 You want one? I'll make one from core ass SDXL using the same exact data. I won't even change the Kohya version, I'll just swap Flux to SDXL with SIMV4 CLIP_L jammed in there like a cruiseliner into the square hole. Similar outcome highly probable because it runs clean with SIM_V4 CLIP_L and it behaves similarly to Flux before it's been issued a full finetune, but way, way faster to train. I'll just merge the CLIP_L with the lora and have a Flux1D + Flux1S + standalone finetuned CLIP_L to shove the entire dataset into SDXL with after these 5 Flux epochs finish. I'll cook it at a similar learn rate.
It shouldn't take very long. It honestly might run any LORA due to the methodology behind the system.
I want to add a few blocks similar to flux-based blocks for T5 small attention in SDXL, but that would involve getting the diffusers guys to host my model and that's a time consuming process it seems. Theoretically it would amplify models like NoobXL into heights of new attention prowess. The pain in the ass part is probably why won't make that model over the weekend though. I also won't train SD3, or SD35L, because those things are less responsive than Flux1D was, and Flux1D basically laughed at me in a very stubborn way when I tried to teach it stuff.
Y'know I think Flux1D can just be retrained using a slider lora setup and an afternoon into a proper de-distilled version of itself. It would probably behave similarly to Schnell though and be slow as balls, so I'd rather just use Schnell.
I thought about just flat removing a third of the Double blocks, since they're mostly devoted to text generation and they eat up a ton of VRAM for less outcome than you'd think. It can generate text properly with the T5 running on only 8 of it's blocks, and it has a ton of them, so it was a good experiment to try when making something like an anime model I think.
@AbstractPhila Thanx man.
@AbstractPhila You really think that will work? Like why isn't everyone doing this already lol, has just nobody thought to be that crazy? And you think the old loras would still even work too? o-O
@AbstractPhila Dont we need your T5 version then?
@Mescalamba NOPE. This has EVERYTHING to do with how I'm training CLIP_L to fight it. I'm making a solid contender. That means we'll be able to use this CLIP_L to fight everything soon.
The next version I DUB; CLIP_L_OMEGA. Since SIMV4 was included to TRAIN this version of CLIP_L, I can guarantee that this is going to be something otherworldly when I do a full finetune of SDXL using it while freezing the CLIP_G.
@AbstractPhila Hm.. I think zer0int tried to bypass T5XXL and CLIP G in order to use just CLIP L. Seems like your approach is aiming for same, just in very different way. Its interesting that CLIP L can somehow override T5. And very handy.
Unsure if or why CLIP G is problem, but I guess you know better. I guess given possible token length of later CLIP L models, there isnt much need for CLIP G anyway.
Given you are using CLIP L to fight T5, does that mean one should input only CLIP L, or mirror CLIP L, or? I guess there is going to be some token length limit compared to using T5?
Btw. Pony v7 solved issues by not using regular T5 XXL, but T5 XXL trained on Pile, I presume its that one from Eleuther AI. Unsure how they went around using different tokenizer. Also AuraFlow works bit different to FLUX, so less issues for them too.
@Mescalamba CLIP_G is actually HIGHLY important for context awareness. It's essentially a form of context management for the subsystem that gets over trained and BURNED really quickly. That's why it becomes unresponsive and SDXL becomes insanely unstable until retraining occurs.
To combat this problem, I'll train SDXL with a completely frozen CLIP_G. This will allow CLIP_L to cut through for more important details, while still allowing CLIP_G to contrast and compare using world-based elements similar to how T5XXL works- but in a much faster way.
This isn't a hunch, I guarantee this will work. CLIP_L handles more information than people think it does.
@AbstractPhila Thats pretty interesting. Looking forward to see it in action.
@Mescalamba "T5 XXL trained on Pile"
Why this method would cause NSFW, hardcore? Im noob at LLM, but i googled Pile and its data contains nothing NSFW.
Thanx for your answer.
@jaseanfreedom934 I'm not an expert either, but I think it's not so much that it specifically makes it NSFW, instead it's just making version of T5 that isn't deliberately made (broken) to be censored.
@LemonSparkle Yes, thanx. That was my second thought. So we have an uncensored t5, will it be usable for other models, when Pony7 will be released?
@jaseanfreedom934 "This model was trained on the Pile, a dataset known to contain profanity and texts that are lewd or otherwise offensive."
In general its just not filtered. It wasnt aimed or tweaked towards NSFW or hardcore, but it wasnt prevented from it either.
I didnt try it with FLUX, but I dont think it will be usable as it is. Main issue can be and probably is using tokenizer LLamaFast and it has somewhat different UMT architecture, whatever that is.
I tried using its sibling, Pile T5 XL and stuff that takes T5 XL as input couldnt work with it. Given what I tried it on is very similar to FLUX, its possible it wont work at all. But, you are free to try it, if you want, or anyone really, maybe it does. Dont have spare space atm so cant test it.
Holy crap depiction offset works pretty good for epoch 6, but not so well for epoch 5.
It's oddly stable in ways I wasn't expecting.