
https://huggingface.co/deepseek-ai/Janus-Pro-1B
https://huggingface.co/deepseek-ai/Janus-Pro-7B
Note: The CY-CHENYUE/ComfyUI-Janus-Pro nodes doesn't support .safetensors.
So I updated/forked the model_loader.py to automatically download, and support .safetensors. It refused to let me rename the files, so you need to keep them named model.safetensors
For the 7B version, I could not get shard-merging to work. So they will be sharded in 3 parts.
Installation instructions
Install ComfyUI
Install the CY-CHENYUE/ComfyUI-Janus-Pro node-pack
Manually overwrite the
model_loader.pyinComfyUI\custom_nodes\ComfyUI-Janus-Pro\nodes\model_loader.pywith the one aboveYou can use the ComfyUI Workflow above
The updated model_loader script will automatically download the model and place it in the correct folder
To do it manually, unzip the files for your desired version in the model list above so that the folder structure looks something like the screenshot below.
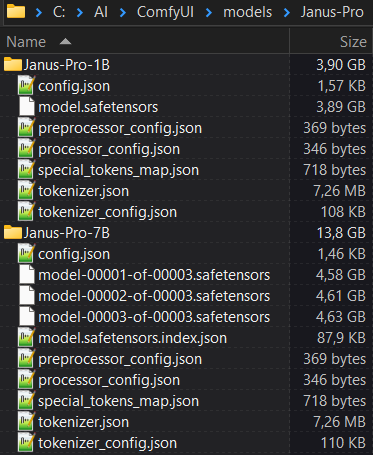 So the model path for the 1B version should be:
So the model path for the 1B version should be:
ComfyUI/models/Janus-Pro/Janus-Pro-1B/model.safetensors
But remember that you also need the config and the rest of the files, which is why it's uploaded as a .zip
There's also a version that is just the support-files, if you would rather combine that with the original .bin checkpoint models.
Congratulations!
With a 3090, 24gb, you can enjoy speedy 8-minute generations for a 384x384 image that looks much worse than anything Stable Diffusion 1.5 spits out in 0.5 second.
Janus-Pro is a novel autoregressive framework that unifies multimodal understanding and generation. It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility. Janus-Pro surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus-Pro make it a strong candidate for next-generation unified multimodal models.Janus-Pro is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation. Janus-Pro is constructed based on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.For multimodal understanding, it uses the SigLIP-L as the vision encoder, which supports 384 x 384 image input. For image generation, Janus-Pro uses the tokenizer from here with a downsample rate of 16.This is the converted .safetensors version of the model.
The original 7B ones can be found here: https://huggingface.co/deepseek-ai/Janus-Pro-7B/tree/e6ac502c7931490e5b56b0ff2d30413f2a21b887
Description
FAQ
Comments (76)
awesome, is there a safe tensors conversion of the 7b model available?
Yes. I've combined them and I'm uploading it right now.
You can also find the safetensors here: https://huggingface.co/deepseek-ai/Janus-Pro-7B/tree/e6ac502c7931490e5b56b0ff2d30413f2a21b887
@muxelmann Thanks!
I didn't know how to get the link to the PR, so I got them manually, and wanted to save people the time and effort to get the model files in that way :)
J-ANUS 🫱(‿¤‿)🫲
Huh lol, is it any good?
@P_Universe No
@mnemic damn I thought it could be the next success
Can this be used in Forge or is it only compatible with ComfyUI?
Only ComfyUI until someone integrates it into Forge.
It's really slow and isn't giving me great outputs.
At this moment only garbage images from 7B model :/
Yeah, it seems to be incapable of anything reasonable.
The 1b model generates fast after the initial load at least.
What's the recommended cfg and samplers?
The recommended CFG is to go back to SD1.5, it produces better outputs than this garbage.
@mnemic lol
@mnemic I came here to say something like this also...mine was going to be... "Don't" just by looking at the examples here unless you are into the "Nightmare Fuel" aesthetic.
@pychobj2001741 100%
When I realized, I was even more determined to get it working and share the results, just to save people the time.
@mnemic The hero we deserve
@mnemicI i don't know the Batman quote
😕
• takes ~15-20s per generation (on a 4080)
• requires lots of VRAM and still hits oom with more than a simple sentence of prompt (with 16gb VRAM)
• to get outputs with 384x384 resolution with lots of hallucinations and deformations
TLDR: Functions ok as an image captioner ~Florence2 level, but using 10x resources and space...
Yup! It's quite funny :D
@mnemic Maybe something useful will come from it at some point. For now it seems to be quite gimmicky like the Omnigen model, which did everything and nothing, taking ages in the process 😅
@RedPinkRetro Yeah, let's see.
I've watched a few videos on this, doesn't seem to even be worth messing with right now, don't believe the hype people. 🤔
Oh the hype is real, just check out the preview images XD
And this killed 15% of NVidias market share? Oh Boy.
(yes I know this was about the LLM itself and not the image generation - but still)
Buy the Dip ;)
Heheh Making the model open and free to install your own instance is what ate the Market Share.
If I ask 1 model that costs $0.01 per query to describe a image. And it does a great job. To Corporations they'll go with the 1 model that costs $0.009 per query that describes the image even if it's slightly less descriptive.
That's capitalism baby! If 1/10th of a cent can be saved but produces a result that is acceptable, it's all golden.
No, this is one model of a much larger DeepSeek family of models. The one that's tearing the world apart is their reasoning chat model that was made at Costco and is 1/4 of the cost of ChatGPT's best model
So far the generated images have not been good for me. I have used model 1B, lots of deformations and it is not good at handling texts.
Think this is not a 'real' diffusion model, hence the poor results
Explains why they haven’t posted table of comparison for Aesthetics. This looks horrible, worse than SD1.5, somewhere near DALL-E1/Midjourney 1/2.
“Best prompt following!”, yeah, sure.
Is there a change that you downloaded the "7B" version?
Is there a way to run these models with CPU only?
Honestly? Save some power and just don't try it (at least not yet). Scroll through the example images - that's pretty much all you can expect
Yeah, not sure why you would want to run these models :D
I guess it should be doable. I didn't bother trying.
So, they reinvented Craiyon, except it's not viable to run on a potato?
Reminds me of early DALL-E, I'm sure deepseek image gen will improve with time.
How can i change the size of the output?
You can't. Not with this image generator in Comfy yet at least.
Well, they got the regressive part right.
some of these images are rated R and X. Like bro, I can't even understand what's going on in the image
Maybe that's the kink? The uncertainty of this models outputs turns the image scanner on? What will it be next? A WOMAN laying on grass?
Metadata flags
This model works better for CV-Computer Vision applications such as describing an image so you can try to recreate it. such as Florence2. Trying to gen images doesn't make much sense. Use this instead of your other CV models.
It should be pitted against qwen2.5 VL, there's also SmolVLM
@praet Qwen is not local is it though?
https://github.com/MNeMoNiCuZ/SmolVLM-256M-500M-Batch
https://github.com/MNeMoNiCuZ/qwen2-vl-7b-captioner-relaxed-batch
https://github.com/MNeMoNiCuZ/qwen2-caption-batch
Here are some local versions of Qwen 2 and SmolVLM.
I didn't do Qwen 2.5 yet.
@mnemic thanks i will do some local benchmarks, have a great week
@mnemic nice nodes, thanks, will star your repo
2017 was calling and want this model back
In my opinion, the way it follows the prompt is nothing short of miraculous. If they continue to improve this architecture, LLMs will indeed be able to create images!
I am running the native Janus Pro 7B model from github. For s**ts & giggles I quantized the model to QINT8 just to see how it works. Works fine.
I would compare image quality to <= SD 1.5. I upscale the 384 X 384 images using RealESRGAN scale = 4, but you can also use the scale = 2 model.
Hopefully, they or someone can fine tune this model to generate better images in the future. Speed wise it's similar to SD 3.5 on my machine. I am only generating 1 image as opposed to the default (5) images. The text it produces is a bit choppy but works.
SD1.5 called, they said this model sucks!
There are serious issues of image breakdowns during use, and we hope these can be improved.
Makes no sense that they released this
"Congratulations!
With a 3090, 24gb, you can enjoy speedy 8-minute generations for a 384x384 image that looks much worse than anything Stable Diffusion 1.5 spits out in 0.5 second."
This made me laugh way too hard.
Appreciate it. Quite truthful though!
Using this model is meant to make you laugh I guess.
Here's something to keep the laughs up:
https://www.youtube.com/watch?v=_uTMyY1irUg
LOL I had the same reaction when I read that.
加。。。加油
this used to work very well for me, but now it does not any longer? Tensor.item() cannot be called on meta tensors
Are you saying you were actively using this model?
@mnemic I got it working again. I'm not using the model to render images. Instead I'm using it to describe images as it does a heck of a faster job than qwen, ollama, etc. and it doesn't use up tokens in the process that cost like the other guys do... I've got some workflows on this over at https://openart.ai/workflows/@mongrel_monstrous_1
@jeffthomann871 Nice use case!
https://github.com/MNeMoNiCuZ/AThousandWords/
I just released this one (not announced properly yet). It's a VLM suite. Do you reckon that Janus is good enough to warrant implementation there?
@mnemic we'll try it and see what happens. Last time I tested things other than deep seek/janus here it required api keys and things and unless you are paying monthly for access to those types of things will run out of tokens quickly. For instance in gemini it would stop working after about an hour and half once your daily limit is exceeded. P.S. Since this comment is on the Deep Seek Janus, which is just what is in the zip file, and you maintain the new node why not build deep seek janus in to your variant in future versions as this appears to be the only safetensor version of Janus that exists at this point in time. Also, have you tested all of what you have built yet? In ancient days when I was testing out tagger nodes it seemed that some of them would just do weird stuff like make every image of an aniaml be tagged as a pokemon, etc. ...... I did try to install your thousand words thing but it didn't work for some reason. For some reason when I go in to the gui bat file it says PyTorch is MISSING However, I've installed it a few times and it still keeps saying that?!?....
@mnemic @mnemic Thanks! Finally got your thousand words app working. I still cannot get flash attention working so cannot do something things but others work nicely. Took a while to get cuda and venv thing worked out but now it finally works.
Deep Seek: The image showcases a vibrant and colorful design featuring various circular and floral shapes. The background is a dark teal color, which contrasts sharply with the bright and vivid colors of the shapes. The shapes include flowers, circles, and abstract forms, all filled with different colors such as red, yellow, blue, and green. The texture appears to be glittery, giving the design a sparkly and lively appearance. The overall composition is playful and dynamic, evoking a sense of joy and creativity. The intricate details and bright hues make it visually striking and engaging. Same with smolVLM2: The image depicts a vibrant, colorful, and intricate pattern of flowers and shapes, likely made of a material that resembles plastic or a similar substance. The flowers are predominantly in shades of orange, yellow, and blue, with some featuring red and purple accents. The pattern is densely packed, with each flower and shape overlapping and intersecting with others, creating a complex and dynamic visual effect. The background is a dark, textured surface, which contrasts with the colorful foreground. The overall composition of the image suggests a playful and imaginative use of color and pattern, possibly intended to evoke a sense of joy or creativity. There are no discernible texts or other objects in the image, and the relative positions of the objects are such that the flowers and shapes are arranged in a seemingly random yet harmonious manner. The image does not contain any discernible actions or movements, and the focus is solely on the visual elements. Given the detailed and intricate nature of the pattern, it is likely that this image is intended to be a decorative piece, a piece of art, or a product designed to stimulate creativity or imagination. The use of bright, bold colors and the overlapping shapes could be intended to create a sense of depth and dimensionality, making the image appear more dynamic and engaging. In summary, the image showcases a colorful, intricate pattern of flowers and shapes, likely made of a material that resembles plastic or a similar substance, set against a dark, textured background. The pattern is dense and complex, with each flower and shape overlapping and intersecting with others, creating a visually stimulating and imaginative composition.
@jeffthomann871 Great! Sorry to hear you had some trouble, but it seems to have worked out.
Flash Attention is not needed. It can speed SOME models up, but don't worry about it. It's a messy one to get right. You need to find the EXACT file matching your pytorch, python, and cuda. So you gotta understand what those values are, and then find the correct .whl to install it manually.
@jeffthomann871 Smolvlm2 there seem to be too verbose, saying things that ARENT in the image. Which is true, but usually not helpful for captioning. But you can try many different models, and prompts, and settings using AThousandWords. It's meant for you to configure to your own needs.