







This lora is testing the ability to improve the faces of SDXL without significant financial investment
I had only $0.33 left for the runpod - and this money was only enough for this micro lora (80Mb).
Dataset: 300 quality portraits of men, women and children. 10 epochs, 16 neurons. ~30 minutes on 3090,
Dataset example:

Despite the tiny size, there are visible improvements in the quality of hair, eyes and skin. Close-up noise is gone. The lighting is more natural.
There are also negative consequences. The trend towards anime style photorealism, for example:

Desc: anime trends to realism (its wrong), but it remove noise and "blurry"
Lora's at this resolution is not enough for small details, shots in the distance.
I think the dataset should be more balanced with different types of images. This will require more processing time and more substantial investment (more money). I have invested a lot of time and personal funds into training models with zero return on investment. Colorful and Animatrix models, fixing clip skip in RevAnimated and merging algorithm through the cosine similarity (implemented in SuperMerger) - these are my developments.
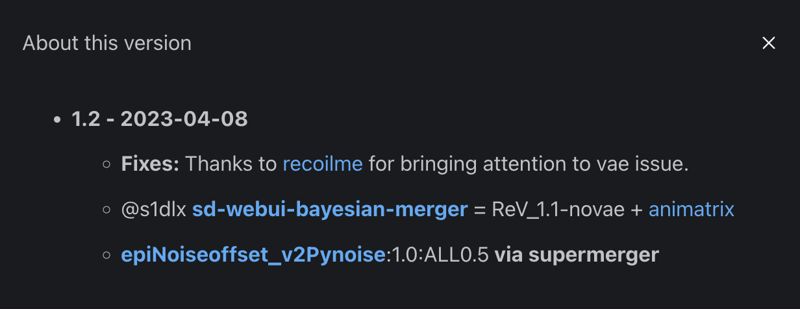
RevAnimated version info:
My models are free to use, and algorithms under Mit license
I would welcome offers to help fund training SDXL. I don't need money, but I need runpod loans (resources). I will be happy to mention in the description of the model your name and a short text that you provide (64 characters).
By the way - current trends to train SDXL on 1.5 output is totally wrong (by my opinion).
TLDR: I know how to fix SDXL right, but i'm not sure what i need to do it for my money and time (again)
My contacts for sponsors (if any):
https://www.reddit.com/user/recoilme
My telegram channel:
PS: Sorry, I poured out some of my pain here. I am very motivated by your support and comments in any case. Have a good day!
Description
# Training Settings
UNet_Training_Epochs= 10
# Epoch = Number of steps/images
UNet_Learning_Rate= "2e-6"
# Keep the learning rate between 1e-6 and 3e-6
Text_Encoder_Training_Epochs= 0
# The training is highly affected by this value, a total of 300 steps (not epochs) is enough, set to 0 if enhancing existing concepts
Text_Encoder_Learning_Rate= "1e-6"
# Keep the learning rate at 1e-6 or lower