Video Generation on a Laptop
Hello!
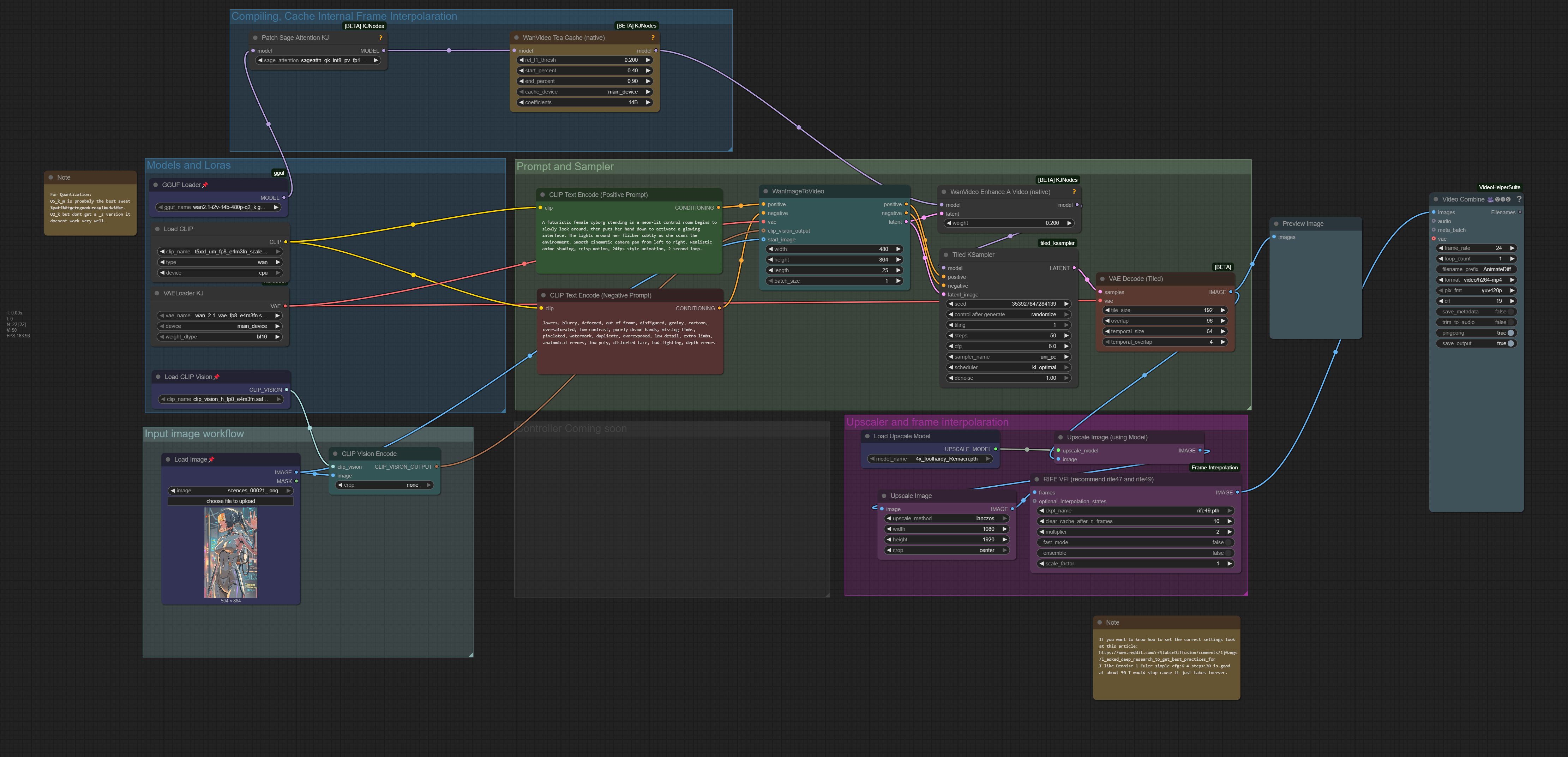
This workflow utilizes a few custom nodes from Kijai and other sources to ensure smooth performance on an RTX 3050 Laptop Edition with just 4GB of VRAM. It's optimized to improve generation length, visual quality, and overall functionality.
🧠 Workflow Info
This is several ComfyUI workflow capable of running:
2.0-ALL -- Includes all workflows:
Wan2.1 T2V
Wan2.1 I2V
Wan2.1 Vace
Wan2.1 First Frame Last Frame
Funcontrol (experimental)
Funcameraimage (experimental)
Coming soon: Inpainting experimentals get updated
🚀 Results (Performance)
*to be updated
🎥 Video Explainer (Vace edition):
🎥 Installation Guide (V1.8):
📦 DOWNLOAD SECTION
⚙️ Nodes Used (Install via ComfyUI Manager or links below)
Note: rgthree Only needed for Stack Lora Loader
📦 Model Downloads
*these are conversions from the original models to run on less VRAM.
most versions
Faster/Better quants for i2v
fun,inpainting,T2V,Vace
fun-control
🔗 WAN2.1 Fun-Camera-control 14B GGUF
fun-Camera-Control
All these GGUF conversions are done by:
https://huggingface.co/calcuis
https://huggingface.co/QuantStack
*If you cant find the model you are looking for check out there profiles!
🧩 Additional Required Files (Do not downlaod from Model Downloads)
📥 What to Download & How to Use It
✅ Quantization Tips:
Q_5 – 🔥 Best balance of speed and quality
Q_3_K_M – Fast and fairly accurate
Q_2_K – Usable, but with some quality loss
1.3B models – ⚡ Super fast, lower detail (good for testing)
14B models – 🎯 High quality, slower and VRAM-heavy
Reminder: Lower "Q" = faster and less VRAM, but lower quality
Higher "Q" = better quality, but more VRAM and slower speed
🧩 Model Types & What They Do
Wan Video – Generates video from a text prompt (Text-to-Video)
Wan VACE – Generates video from a single image (Image-to-Video)
Wan2.1 Fun Control – Adds control inputs like depth, pose, or edges for guided video generation
Wan2.1 Fun Camera – Simulates camera movements (zoom, pan, etc.) for dynamic video from static input
Wan2.1 Fun InP – Allows video inpainting (fix or edit specific regions in video frames)
First–Last Frame – Generates a video by interpolating between a start and end image
📂 File Placement Guide
All WAN model
.gguffiles →
Place them in yourComfyUI/models/diffusion_models/folder⚠️ Always check the model's download page for instructions —
Converted models often list exact folder structure or dependencies
🔗 Helpful Sources:
Installing Triton: https://www.patreon.com/posts/easy-guide-sage-124253103
Common Errors: https://civarchive.com/articles/17240
Reddit Threads:
https://www.reddit.com/r/StableDiffusion/comments/1j1r791/wan_21_comfyui_prompting_tips https://civarchive.com/articles/17240
https://www.reddit.com/r/comfyui/comments/1j1ieqd/going_to_do_a_detailed_wan_guide_post_including
🚀 Performance Tips
To improve speed further, use:
✅ Xformer
✅ Sage Attention
✅ Triton
✅ Adjust internal settings for optimization
If you have any questions or need help, feel free to reach out!
Hope this helps you generate realistic AI video with just a laptop 🙌
Description
-No torch compiler doesn't seem to work anymore
split between I2v T2V
Video Guide For installation
FAQ
Comments (15)
Failed to find C compiler. Please specify via CC environment variable. :(
Make sure you have all the envivorment values on path for cuda and triton.
Prompt execution failed
Prompt outputs failed validation: LoaderGGUF: - Value not in list: gguf_name: 'None' not in []
Sorry for the late reply but did you download the gguf model and put it in the right folder the video should show you which folder I think diffusion_models
It seems I have some issue with sageattention:
ImportError: cannot import name 'sageattn_qk_int8_pv_fp16_cuda' from 'sageattention'
Could u plz share some solutions?
I don’t have a soloution sage attn and torch are difficult especially cause very update changes so much I would disable that if you can’t get it to work hope that helps a little sorry..
@The_frizzy1 Thanks anyway~ I'm going to ignore that.
@Diaoshini8280128 did you try doing everything in this video for the installation I tried the workflow again and with the updated KJnodes I even got torch working again. https://m.youtube.com/watch?v=DigvHsn_Qrw&t=13s
@The_frizzy1 Thanks~!! I'll try later.
Does Sage Attention require CUDA 12.8 or higher? If so, that's the problem.
Working. 3060 12gb vram + 16gb ram. You should create a low vram version with LORA node
What models did you download to get it to work? I have 12gb VRAM (3060) and 32GB ram. I'm a bit lost here :/
Thank you!
@WaifuAIDegenPrompter i have a 3050 ti laptop version and the highes i could go was Q3_.. highes I would go with that setup is Q5 hope that helps
@The_frizzy1 Do you need the text encoder thing as well? if so, which one?