







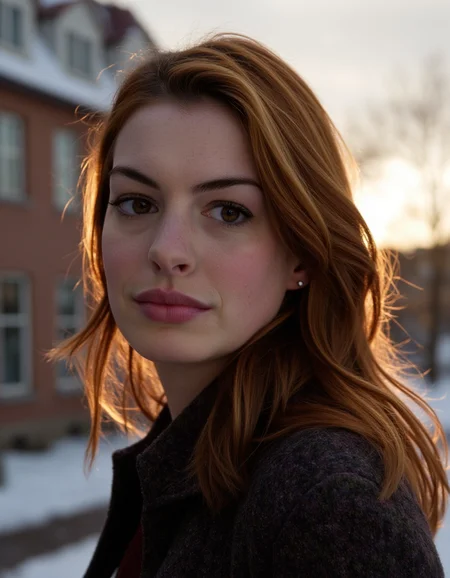

Please Donate Buzz for FLUX Lora Training !
FLUX v1.0 Hathaway :
Trained on FLUX.1 [dev] with 80 photos of Anne Hathaway with detailed GPT-4 captions. Tested on FLUX 1.dev (full) and FLUX fp8 and FLUX nf4 ! Use around strength 0.8-1.0. Distilled CFG around 1-4 and CFG 1.0 (without negative prompt). Clipskip 1. Can be used for example as follows:
Positive : {Artstyle, Character and scene description in usual FLUX fashion}, <lora:Anne_Hathaway_FLUX_v1_epoch_49:1>
SDXL v2.0 :
Trained on Juggernaut X with 199 photos of Anne Hathaway with an improved Lora training method for better likeness and flexibility. Tested on Juggernaut X, Juggernaut v7, RealismEngine 2, RealVisXL3 and AlbedoBaseV2! Use with keyword : "anxhthway" . Use around strength 1.0. CFG 5.0-7.0. Clipskip 1. Can be used for example as follows:
Positive : {Artstyle}, {Character and scene description}, anxhthway, <lora:anhathaway_juggerX_xl_1_standard_wocap_merger_56prev_51_72_04_03_03-anxhthway:1.0>
Negative : ugly, deformed, airbrushed, photoshop, rendered, (multiple people), child, mouth open
SDXL v1.0
Lora trained on 190 images of Anne Hathaway on the SDXL 1.0 base model. The recommended Lora strength for ComfyUi is 0.9-1.1.
Description
FLUX v1.0 Hathaway :
Trained on FLUX.1 [dev] with 80 photos of Anne Hathaway with detailed GPT-4 captions. Tested on FLUX 1.D (full) and FLUX fp8 and FLUX nf4 ! Use around strength 0.8-1.0. Distilled CFG around 1-4 and CFG 1.0 (without negative prompt). Clipskip 1. Can be used for example as follows:
Positive : {Artstyle, Character and scene description in usual FLUX fashion}, <lora:Anne_Hathaway_FLUX_v1_epoch_49:1>
FAQ
Comments (4)
Can you ask why your lora training style is so small? 18M, are the pixels of the training set collected by the network? 1024?
I am training on 1024 pixels but I keep alpha/dim at 2/16. So the output netwrok is quite small. It costs quite a bit of buzz to train so I haven't tested enough. I am training some new models with slightly different dimension and netwrok alphas to see how it goes. if that goes fine I will also experiment with the number of training images, captioning depth, training steps, scheduler and lerning rate. I simply dont have enough buzz to do so constantly though.
Hi steffangund,
your models are truly some of the best I’ve seen!
I noticed you used GPT-4 for generating captions. Can I ask you the prompt you used to tell GPT4 to act as prompt generator (or maybe you used Caption Helper)? did you make any manual adjustments after the generation?
Thanks for your amazing work!
No I kept them just as is . I found a good enough preompt where most of the captions are quite good. The most important thing is the image quality and variety.
Details
Files
Anne_Hathaway_FLUX_v1_epoch_49.safetensors
Mirrors
657620_Anne_Hathaway_FLUX_v1_epoch_49.safetensors
Model_Anne_Hathaway.safetensors
Anne_Hathaway_FLUX_v1_epoch_49.safetensors
Anne_Hathaway_FLUX_v1_epoch_49.safetensors
Anne_Hathaway_FLUX_v1_epoch_49.safetensors
flux_train_replicate.safetensors
Anne_Hathaway_FLUX_v1_epoch_49.safetensors
76-Anne_Hathaway_FLUX.safetensors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.