RefControl Flux Kontext – Reference Pose LoRA
📝 Short description
A LoRA for Flux Kontext Dev that fuses a reference image (left) with a pose control map (right).
It preserves identity and style from the reference while following the pose and body structure from the control.
Trigger word: refcontrolpose
Workflow https://civarchive.com/models/1894175
[Demo Video] https://youtu.be/8eTjC7InE44
Huging face page: https://huggingface.co/thedeoxen/refcontrol-flux-kontext-reference-pose-lora
📊 Examples
InputOupttut




📖 Extended description
This LoRA was primarily trained on humans, but it can also be applied to stylized characters and some objects.
Its main goal is to transfer identity — facial features, hairstyle, clothing, or object details — from the reference image, while adapting them to the pose and skeleton structure defined by the control map.
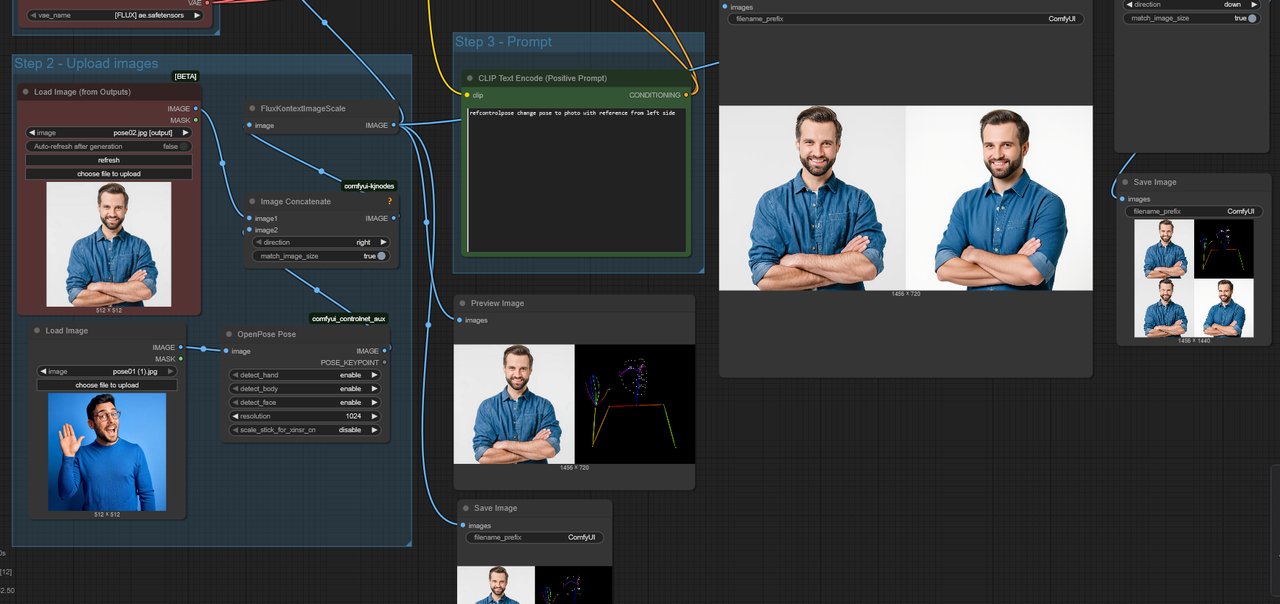
⚙️ How to use
Concatenate two images side by side:
Left: reference image (character, person, or object).
Right: pose control map (skeleton, keypoints).
Add the trigger word
refcontrolposein your prompt.Adjust LoRA weight (recommended 0.8–1.0) depending on how strongly you want to preserve identity.
Worklow:
For workflow you need to install in ComfyUI:
✅ Example prompt
refcontrolpose change pose to photo with reference from left side
🎯 What it does
Preserves character identity across generations.
Adapts the subject to a new pose or action.
Works well for character consistency in sequential generations.
⚡ Tips
Best results when the pose map has similar proportions to the reference image.
Combine with text prompts to refine background or mood.
Can be chained with other RefControl LoRAs (depth, lineart, canny) for multi-constraint generation.
📌 Use cases
Character posing for illustrations, comics, or storyboards.
Consistent character design across different poses.
Re-posing stylized characters while keeping their identity.
Creating animation keyframes from static references.
Description
FAQ
Comments (23)
❤️❤️thank you so much!!
thank you for usage and comment! 🙌
@thedeoxen is lineart too on the way? ,i am too exited to try it,Thank you again.❤️❤️
@LastDelivery4801226 Hey, just released lineart 🙌 Hope it will be helpfull for you
https://civitai.com/models/1902256?modelVersionId=2153190
@thedeoxen Thank you ,will try it soon👌👌❤️❤️
Чет он так хорошо переносит, что даже шакальное качество перетекает на результат. И исправить это не получается. У меня есть рендер без антиальясинга. И он все лесенки и хреновые полигоны, переносит на результат. Как я только не пытался писать, стиль не меняется. Если словами менять позу, можно делать генерацию в каком угодно стиле. А если силу Лоры снизить, то результат лучше не становится, так еще и поза не переносится.
Да у сожалению плохое качество он может воспринимать как "стиль" и переносить его(
The result almost always fails. I downloaded you workflow, changed ksampler with taesd, but something must have gone wrong. Can you show us a screenshot of the workflow so we can reconstruct it?
https://i.postimg.cc/fbwv63Kk/Screenshot-2025-08-26-at-14-44-34-73-75-KSampler-Efficient.png
{kind=link}
hey, attached image with workflow
https://postimg.cc/CdpsffFV
hot it will help. Sorry didn't work with teasd
Thank you for workflow. I think all is right, but something doesn't works, thank you for your work!
I don't know if you use nuncnaku_ nodes, but I encountered the same issue of being unable to load LoRA, and it was successfully resolved after replacing the LoRA loader in nuncnaku_ nodes.
Works ok with Nunchaku.
This LoRA is such a cool idea, thanks a lot for putting it out there! 🙏
I’ve noticed it can struggle sometimes, especially with close-up faces or really complex poses, but overall it’s already very impressive. Would love to see a V2 with some extra training data to handle those tricky cases.
Just a thought: have you tried blending the pose map with the input image? That might help keep things tighter and bring out even more detail in the results.
excited to see where this goes!
I have to say that the performance of this Lora in terms of full-body character consistency is really terrible. The half-body images perform well, but the full-body vertical images can hardly maintain character consistency. This should not be a problem that occurs with a kontext'sLora. If you use full-body pose reference images to control your full-body character pictures, it will not yield good results; it almost undermines the advantage of kontext in character consistency.
I don't know if the author used a half-body horizontal image dataset for training, while neglecting the full-body vertical image dataset, which led to such poor results.
Full body works for me. I used full body ref and full body control images. Make sure to use vae and loras listed in notes inside workflow.
So the lora works great! But I can't figure out how to get a non-concatenated output. Any tips other than just splitting the results manually?
Hi, it works very well, thanks for sharing. But I wanna finetune a pose control lora for anime only. I am preparing my datasets. Could you advice the amount of datasets for training?
Hey, thank you! I opensourced dataset that I used you can find it here.
https://huggingface.co/datasets/thedeoxen/refcontrol-flux-kontext-dataset
I used around 100 pairs for poses.
Thanks. It seems a lot for me. And I am preparing some unconditional pose.
Such a great work!!
how to train such a lora model, could you give some tutorials? appreciate!
What settings do I use to prevent noisy output? It's grainy.
It's not working for me, is it working for anyone else? The image is grainy, what settings did you use?
It's not working for me, is it working for anyone else? The image is grainy, what settings did you use?