



















Pony V7 is a versatile character generation model based on AuraFlow architecture. It supports a wide range of styles and species types (humanoid, anthro, feral, and more) and handles character interactions through natural language prompts.
Fictional
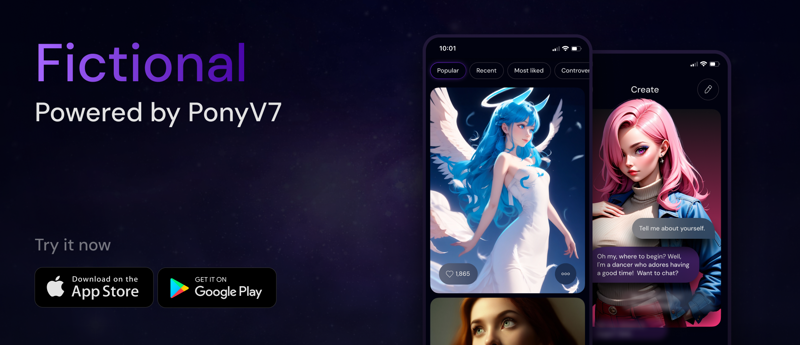
First, let me introduce Fictional - our multimodal platform where AI Characters come alive through text, images, voice, and (soon) video. Powered by PonyV7, V6, Chroma, Seedream 4, and other advanced models, Fictional lets you discover, create, and interact with characters who live their own lives and share their own stories.
Fictional is also what enables the development of models like V7, so if you’re excited about the future of multimodal AI characters, please download Fictional on iOS or Android and help shape our future!
iOS: https://apps.apple.com/us/app/fictional/id6739802573
Android: https://play.google.com/store/apps/details?id=ai.fictional.app
Get in touch with us
Please join our Discord Server if you have questions about Fictional and Pony models.
Important model information
Sorry to keep you waiting for so long, the landscape of the image generation model changes dramatically since the release of V6. Please check this article to learn more about why it took so long for us to ship V7 and upcoming model releases.
Model prompting
This model supports a wide array of styles and aesthetics but provides an opinionated default prompt template:
special tags, factual description of image, stylistic description of image, additional content tagsSpecial Tags
score_X, style_cluster_x, source_X - warning: V7 prompting may be inconsistent, please see the article as we are working on V7.1 to address this.
Factual description of image
Description of what is portrayed in the image without any stylistic indicators. Two recommendations:
Start with a single phrase describing what you want in the image before going into details
When referring to characters use pattern
<species> <gender> <name> from <source>For example "Anthro bunny female Lola Bunny from Space Jam".
This model is capable of recognizing many popular and obscure characters and series.
Stylistic description of image
Any information about image medium, shot type, lighting, etc. (More info TBD with captioning Colab)
Tags
V7 is trained on a combination of natural language prompts and tags and is capable of understanding both, so describing the intended result using normal language works in most cases, although you can add some tags after the main prompt to boost them.
Captioning Colab
To get a better understanding of V7 prompting, we are releasing a captioning Colab with all the models used for V7 captioning.
TBD (next week)
Supported inference settings
V7 supports resolutions in the range of 768px to 1536px. It is recommended to go for higher resolutions and at least 30 steps during inference.
Highlights compared to V6
Much stronger understanding of prompts, especially when it comes to spatial information and multiple characters
Much stronger background support - both generation of backgrounds and using background with character
Much stronger realism support out of the box
Ability to generate very dark and very light images
Resolution up to 1536x1536 pixels
Expanded character recognition (some V6 characters may get less recognized, but generally we extended the knowledge by a lot)
Special thanks
Iceman for helping to procure necessary training resources
Simo Ryu and the rest of FAL.ai team for creating AuraFlow and emotional support
City96 for help with GGUF support
diffusers team for supporting AuraFlow integration work
PSAI Server Subscribers for supporting the project costs
PSAI Server Moderators for being vigilant and managing the community
Many supporters that decided to remain anonymous but their help has been critical for getting V7 done.
Technical details
The model has been trained on ~10M images aesthetically ranked and selected from a superset of over 30M images with roughly 1:1 ratio between anime/cartoon/furry/pony datasets and 1:1 ratio between safe/questionable/explicit ratings. 100% of all images have been tagged and captioned with high quality detailed captions.
All images have been used in training with both captions and tags. Artists' names have been removed and source data has been filtered based on our Opt-in/Opt-out program. Any inappropriate explicit content has been filtered out.
Limitations
This model does not support text generation and has degraded text generation capabilities compared to base AuraFlow
Special tags (including quality tags) have much weaker performance compared to V6, meaning score_9 would not necessarily yield better results on some prompts. We are working on a V7.1 follow-up to improve this
Small details and especially faces may degrade significantly depending on art style, this is a combination of outdated VAE and insufficient training which we are trying to improve in V7.1
LoRA training
We recommend using SimpleTuner for LoRA training following this guide.
, please stand by for diffusers support, Comfy workflows and training guides.
Downloads
Comfy Workflow: TBD
Commercial API
We provide commercial API via our exclusive partner FAL.ai
License
This model is licensed under a Pony License
In short, you can use this model and its outputs commercially unless you provide an inference service or application, have a company with over 1M revenue or use in professional video production. This limitations do not apply if you use first party commercial APIs.
If you want to use this model commercially, please reach us at [email protected].
Explicit permission for commercial inference has been granted to CivitAi and Hugging Face.
Description
FAQ
Comments (934)
Showing latest 308 of 934.
... this shits so wank 😭
My final word on Pony 7 is that it's an absolute disaster.
I am erasing from my memory and stopping all discussion of this garbage, in comparison to which the failed SD3 looks like a diamond. Let's bury Pony in the dustbin of history.
Yes, I tried to get at least 1 good image, Pony v7's outputs looks like they are from a bad SD 1 model, so disgusting and awkward. And there's still no promised distilled or enhanced version! I am not gonna use it
i'm hopeful for v7.1 and finetunes, but honestly i think all of the problems are coming from the auraflow architecture. the base model for auraflow suffers from similarly bad artifacting and anatomy mistakes
@7oxytron Their app, Fictional, is for 12 years old kids, check the rating on Play Market. Anyway, even my local anime AI slopper said NOOO after seeing those "beautiful" sample images
@7oxytron Who's gonna finetune this? Realistically?
RIP PonyDiffusion, you will be remembered for v6.
@Slowmoe And the truth is that it would be a titanic job for anyone who dares to do it.
Which one is better?
Pony v7 FP16 or SD1 Q2?
I know it's a hard question, but I'm really wondering which one is better
At least, SD 1 is lightweight and needs less memory. Pony v7 creates worse images
chroma is better imo
sd1 can atleast do cats.
there is no aura in this aura flow model.
aura flow more like aura flaw
@EBIX
https://reddit.com/r/StableDiffusion/comments/1o7b4dz
https://reddit.com/r/StableDiffusion/comments/1njhxmw
+their AuraSR model is worse than normal GAN upscalers
@EBIX Even Latent Diffusion can show us normal cats 🐱 not monsters
@EBIX Yeah but SD1 can't create this: https://civitai.com/images/105475436
@Plswin 🤯
https://civitai.com/models/7371/rev-animated better Ponyv7 =)
@meikerAI3d The model is legendary
guys please have patience the model is just pregnant with 3 sd1.3 models.
on the side note guess what we have, pony 6 and pony 7, on time to be a meme!
This is the hype??
not looking good so far.
FYI, the download is just the checkpoint so far as I can tell. I think you need to go get the AuraFlow text encoder from HuggingFace and VAE from either HuggingFace or here on CivitAI. But I'm not a developer of this model, so I don't actually know those are the correct ones.
Now if only HuggingFace downloads actually worked... :(
I know the results so far leave a lot to be desired, but I like the open source nature of AuraFlow and the idea of not being chained to SDXL's text encoder.
@2P2 Thanks.
I also finally figured out how to clone HuggingFace repos with git, so now my downloads might actually work!
Bruh... Is this SD 0.3?
Nah, it’s VQGAN+CLIP. Some of these look worse than even Disco Diffusion
EEEEEasy guys! Keep in mind this is the author that produced THE PonyV6 for all of us! The mother of all nsfw models so come on now! Give them sometime please! This can only get better and better! keep up the good work!
er
We wait ponyv8.
Give them time? To do what? Take another year for another release?
@2P2 damn someone called you schizo.. smh... https://www.reddit.com/r/StableDiffusion/comments/1ofvh27/not_cool_guys_who_leaked_my_vae_dataset_come/
@newbieAiUser thx for sharing :) It's the second time when I see smth about myself like that
So yeah. Looks like it could be interesting. But what the f**k are "style clusters"? And is the locked to being used with ComfyUI only? Because ComfyUI is anything but comfy to use. It is, in fact, a goddamn nightmare.
There's a patch/addon to run AuraFlow on Forge Neo, so you could probably kitbash that to work with PonyFlow if you wanted to (though whether that's easier than Comfy is up to you). Or wait for official Forge Neo support if this model gets popular enough.
Получился отличный генератор расчленёнки, спасибо, жду пони v8. Главное не сдаваться.
One 0.5 pass i2i makes decent results. Like its a base model, cope. it looks like its trying for its life and isn't really that bad once you get a good prompt going. There's not many major deformations; it's just a crap ton of smaller artifacts and overall sd15 look. But will it ever be close to V6? Illustrious.. noob? It could be.. but no. simply because the level of entry for training is just too high. even prompting basically requires an LLM to write a page of filler. How is anyone supposed to caption that accurately enough?
I'm kinda confused on how this even happened. Is this intentionally bad just so you can f off and cut your losses? cuz even then, i dont get it
So either all of us here are dumb and don't know how to use this model because there's not one picture posted here that's better than Pony v6 (and if that's the case why didn't they post a guide on how to use it correctly?) or they wanted to stop it here. Why release the model at all? Maybe because they had to. Either way, I don't see this getting good. Maybe it can get better with some tweaking but certainly not better than v6 or Illustrious.
@Slowmoe bc they invested too much into a model that's dead on release so now they release this half-assed model and slap 'base' in its name so that some fool might salvage it with a fine tune
I've never seen so much whining and complaining over a free resource before. Be better, and remember the human.
Treating community champions like AstraliteHeart/PurpleSmartAI so poorly is a great way to ensure that we're forced to suckle at the teat of cloud compute (*cough* subscriptions) for the rest of our lives. If you can't even be supportive, then what do you have to offer them? What would make them want to work on this stuff anymore, let alone release the weights to the public?
While v7 may not be strong out of the gates, it has already been stated that it's being worked on, and surely they learned a lot from their efforts on training it.
The community was ready to support. The community was waiting and asking for a new version (v7). When the community found out what v7 was going to be based on, they literally shouted unanimously, "Stop, don't do it! Don't try to rape a corpse, it's already cold!", but no - literally the worst and most miserable of the possible options for v7 was chosen.
They didn't care about the opinion. But the community is big - it wiped itself. But this is no longer the champion of the community. This is a team that does whatever it wants - something that only they themselves need and no one else (and possibly a very narrow group of like-minded people).
So if they do something that nobody asked for, that nobody wanted, that nobody needs even for free (and even if they pay extra!) - why should the community be happy about it? It's like rejoicing and thanking a drug addict in California for taking another dose - nobody but him needed it, everyone would be happy if he didn't, but it's free for us, right?
@desm0nt
This is a team that does whatever it wants
Always did!
@desm0nt well well well, "not thanking" and "throwing insult/bullying", has very distinct terms, i can't see why such simple concept is very difficult to grasp, your analogy is very moronic, how could you compare a drug addict with some creator, since you're the one addicted by generating some gooning shit, the analogy is better with ai generated porn addict vs drug addict mentality, i hope you run the models locally, or it only makes the analogy better since you spending money to buy buzz only to generating freaking P*RN, LOL. I mean gooning is fine but at least be a nice and kind gooner, would be better rather than annoying gooner.
AuraFlow hmm. I am a superfan of V6, Flux is bad compared against it. And i am intrigued by version number 7. Lets check it out!
My experience so far is that getting half decent hands is annoy if they aren't doing something specific.
Eyes seem to do alright if I just describe them in the caption (tags responsiveness is pretty low), but I have yet to figure out an approach for hands. "Highly detailed hands with all five fingers" kinda worked for a simple pose, but only one hand came out particularly well.
wtf is wrong with people!??! do you not understand you are NOT paying for anything? why are you sh!tting on this? seriously. I'm legit confused what world y'all live in that you think you are entitled to complain about something that is FREE for you.
Because you saw Auraflow was a dead end, I saw it was a dead end, everyone else saw it was a dead end yet somehow PurpleSmart didn't, irony of that name is not lost either.
Loads of people commented about Auraflow being a poor choice of base model. It's literally a dead model that hasn't been updated in over a year and has no one using it so there's no lora's either. But instead of cutting their losses and choosing a popular model that runs good like Illustrious, they pressed on and ended up with something that has much higher requirements for an inferior quality.
i get you but just because someothing is free doesn't mean its immune to criticism, we waited so long for it
We do pay for it, we pay for it with the money we spend on power in order to run the model. Or we pay to rent GPU's. Sadly this Pony V7 model is simply not producing image worth using or keeping. I mean even there own workflow is not setup to save the image, only to preview them, so even they know most of the stuff this model spits out is not worth saving. I gave it a real good go tonight and the best i can get the model to produce is not worth wasting power on.
@Artidev i think this community is filled with brainrot gooners that can't even distinguish between insulting/bullying and criticizing
@BlueToothSpeaker to be fair it's sill considered as "free model" at least technically, since you here only pay for the generation service.
@BlueToothSpeaker yeah if you paying to run on civitai... sure. that gets kickback to the owner.... I guesss complain away. but that's not the majority of folks. most folks download and run on their local hw... company gets no $ from that.
I think people's expectations were a bit too high, as usual. The model is actually quite good, but it's very prompt-dependent - and in my personal experience, it's especially sensitive to the 'Style Cluster'.
I hope Astralite writes a guide on how to use it; I think that would make things much clearer for everyone.
Overall, I'm very happy with the results. Thank you, Astralite. The work you did with the styles is excellent
lmao have fun wasting compute with fine tunes because slapping "base" in the model name doesn't magically salvage it
truly the sunk cost fallacy of all time
sdxl remains the goon king
@EBIX sdxl too was crap at the beginning, better wait for the finetunes ^^
@Tetsuoo are you sure about that?
@EBIX Yes, even the base model (SDXL 1.0) is enough good to render decent images. Try yourself and compare with SD 1 or 2
This model unironically made me enjoy using an SD 1.5 model again because while it also gave me anatomical horrors, at least I eventually got something good after three attempts.
It took around fifteen gens locally before I got something that didn't look like it came out of crAIyon. And the result was still a blobbed mess. V7 is very sensitive to how it handles prompts, and even when working through the guide, I still shouldn't be getting results that makes base V6 with no loras look like it can challenge base Illustrious on Civit's generator.
I should NOT need to write a Flux-esque schizoprompt essay to get the bare minimum results man. :(
Oh, and for anyone planning to use it locally—it is SLOW. Like, waiting for a Chroma/Flux gen slow. Except you're waiting a minute or two for horrors right at your mental comprehension.
I like how far we've come with this tech, where a minute is now considered slow. lol.
XD, You've moved this model from "Pony V7" to "AuraFlow" model category.
because it based on AuraFlow🤦♀️
@Pixelycia I see you aren't enough sane not to insult yourself, bye-bye
@2P2 you embarrassed yourself, and then you shamefully delete comments, who is more sane - me or you?
You are all insane. Getting mad about stuff like this is insane.
With this model will be repeated the same story than Pony V6 XL: Nobody will try to make a LoRA based in this model focused in adding coherent text to images.
Nope, Pony V6 XL was posted when SD 1 was the king for countless users, and the base model was usable and competent. v7 was posted after Chroma1 HD and NetaYume, and the new base doesn't look very promising
The variation within one style cluster can be too much, and different seeds give completely different styles - for example, style_cluster_221 seems to be about 3D? But not really? How were the styles grouped? Where is the full guide?
yep, that what was written inside model's card
> score_X, style_cluster_x, source_X - warning: V7 prompting may be inconsistent, please see the article as we are working on V7.1 to address this.
@Pixelycia Which article? The apology bullshit one doesn't even have any list of clusters or any exact guidelines on prompting.
It's clear that the order of tags or vague explanations are not enough. Styles vary even within one cluster, it's literally cannot be reproduced - different seeds give different style on the same prompt.
@dobomex761604 first of all I didn't say anything about any article, I'm just pointing out that this is known issue, but you stubbornly repeat the same thing that was stated right above on this page
and if you really not only generate porn images all the time you probably should known that the order is a recomendation but not a strict rule
@Pixelycia Sorry if I made it sound towards you - I didn't mean it. I'm just frustrated that the same mistake is repeated again: Pony v6 didn't have the full list of tags too (at least not officially). However, v6 is easier to get good results from, while v7 practically requires cluster tags to work.
Really not seeing anything in the gallery that's higher quality than illustrious models can do. though many that are far worse.
Really should have made it Illustrious based instead of going with a base model that has very high requirements to use at any decent speed and requires comfyui to use.
I mean, you literally used a dead model base. No one is training anything and making models or lora's for Auraflow. There's literally only 9 things on this entire site for it including this. Auraflow itself hasn't been updated in over a year. This is like releasing a 1000 ways to cook a chicken cookbook except chickens went extinct halfway through writing it and you decided to finish it anyways instead of cutting losses and writing 1000 ways to cook a duck.
At least if you trained with Illustrious, there's already be loads of Lora's and stuff already made that could be used and many checkpoints that could be merged with V7 for new models.
Oh it gets better, a lot of images get removed from the gallery. Since i got banned from the gallery, only like 20 new images appeared since in those 24 hours. It's way worse than what you actually see in the gallery,because they keep hiding images.
Imagine how badly they'd butcher Illustrious just to remove the artist tags.
@EbenezerDanglewood Style clusters are better if you don't wanna use artistic style, don't wanna biased toward them, or not allowed to use them
@2P2 I think it's a cute concept that has clearly not been executed well.
Despite the odds, I've managed to create an advanced workflow that produces high-quality outputs: https://civitai.com/models/2075661/pony-v7-advanced-workflow
What do you mean about high quality? Bad eyes on portait, with upscaler and refiner? And write in human language, whats in it.
@dequariuszamir725 there are huge amount of artist that do art in different style. What is "bad", what is "good"? If you prompt properly it return "good" results, you just become too soft using slop models where "1girl" prompt is enough to get a visually appeal image, but they just limited to one art style, pony v7 on other hand return huge amount of decent arstyles on different taste
@Pixelycia I agree about styles, but that doesnt justify bad teeth:)
{kind=link}
@dequariuszamir725 this is the "RAW" base-model! Do you remember the basemodel Pony V6??? I was even shittier ;) Soon (I hope) there will be some nice LORAs ...
@dequariuszamir725 it all depends on prompt and WF - yes I can generate ugly shit using this model too, nevertheless - it is just a raw V7, soon v7.1 will fix some issues ;)
@Pixelycia agree 120%
@0l1v1aR0551 I dont know, how many poeple want to bother with auraflow. It never was a good model, T5 makes better adherence, but thats not enough to replace xl.
@dequariuszamir725 I do agree with you on that :(
Does this work in automatic1111?
It will never work because Automatic1111 has been retired for some reason
there is a 10 unofficial days old patch on github for reforge. And it didn't wotk for me, unfortunately, even after checking all the settings changed manually. MAybe because it is for auraflow 0.3, not exactly for pony v7.
People still use it? It's been dead for a while
@AoiAi And Forge RIP too, and reForge 2 rests in peace
The person working on Forge UI Neo fork said they might consider making support for it after the model is able to generate images better than 2 years ago. Here's hoping.
Initial support is here, better support will be added later. https://github.com/maybleMyers/chromaforge/tree/p7
pony 7 was just released to complete the meme of 67.
The previous meme was Pony Diffusion v6.9
Hi! I downloaded the model and am looking forward to what I can do with it. However, it gives me an error where it says it has requires a specific CLIP file to work? It won't run ion either comfy or swarm because of it
I believe for the clip you need to go here https://huggingface.co/purplesmartai/pony-v7-base/tree/main/text_encoder and get the either model.safetensors or model.fp16.safetensors.
You can see an example ComfyUI workflow if you download one of the images here (you probably want the simple one at first) https://huggingface.co/purplesmartai/pony-v7-base/tree/main/workflows and then drag the image into ComfyUI.
A word of warning, this model is pretty difficult to prompt. It tends to require long prompts to get good results. See here for some advice on how to prompt it: https://civitai.com/articles/21107/captioning-and-prompting-primer-for-v7
And download the Flux AE
Is it possible to use onsite? For some reason it keeps putting dreamshaper when I try to use it...
This is a feature, not a bug. No, I have no idea, it's the same for me. However, I can tell you that it would be a shame to use your Buzz to create something onsite anyway!
🔴 Without comment, it is now available for download and the necessary style clusters are still missing!
🔴 The license is changed to Apache 2.0 without comment!
🔴 The base model name is changed to Auraflow without comment!
🔴 The model is excluded from onsite generation without comment?
🔴 Only a hater would think of questioning this presentation!
I think releasing the checkpoints live broke something on Civit's side, I asked them to inveterate.
@PurpleSmartAI Okay, that's why I phrased it as a question. Thanks for clarifying.
@_Varos_ the Pony license is hilarious
After testing V7, to consider it as new finetuning model, i see, in compare to models like PonyV6 or Illustrious, that V7 is still in the process of learning characters and concepts, including NSFW ones. PonyV6 and Illustrious already handle those elements with more consistency, stability and in detail. I think the community also often uses the term “finetune” to describe models that have become stable in style and output through LoRA-style merges. Making a model more stable and “beautiful” is different from adding actual new knowledge. V7 still lacks a fully stable understanding of many characters and concepts and this can only be improved through further full training. Considering how unstable everything currently is in V7, I doubt, that the style clusters are doing a good job either.
This model is simply not ready in its current state and needs more training. It is, at its base, inferior to PonyV6 or Illustrious in terms of stable knowledge. Everywhere I look, it still seems to be in mid-training, showing the same characteristics I’ve seen many times when training 1.5, SDXL, or the body horrors in convertion of base SDXL to a tag based model. Dataset wise, it seems to lack the data of characters of this year.
AuraFlow is more advanced compared to SDXL, but it can’t perform miracles if it’s undertrained. At the same time, it’s also not actual anymore, like it doesn’t use the newer 16-channel VAE. This model is unfinished and is already behind the best technologically. I know how costly training is and it hurts to see so much effort goes into a project that probably won’t get much use. The AI community can be harsh, if something works great, it gets praised, but if it shows flaws, people will quickly turn against it.
Conclusion for me: I wait, if it gets better, also because i'm not the one getting the funds to do the work to finish a product...
"The AI community can be harsh, if something works great, it gets praised, but if it shows flaws, people will quickly turn against it". This shows how toxic this community has became, and the most hilarious thing is, they literally use it for gooning (at least 90% of them, which is the majority of image generation i've seen), like how can this community be so toxic when they don't even have "noble goals" in the 1st place anyway, i mean, gooning is fine, but become toxic because of it....just unbelievable. I wish the community filled with level headed person like you, but toxic ungrateful MF's seems to always have a bigger populations on every communities.
@N3kor0 The community is made up of a huge number of people.
A few members of their community who enjoy trolling and evoking negative emotions from the victim will inevitably write a negative comment. And these negative comments are the first to be noticed.
You probably don't realize the enormous toxic pressure placed on celebrities, especially music artists, even though they seem to have millions of fans.
And these "toxic comments" aren't always untrue - in fact, negative reviews are much more meaningful. We, ordinary users, don't have to download a bad model and waste time on it because negative comments and images have warned us and described everything. And thankfully, they've saved us time and spared us the unnecessary stress of researching a model that's not yet ready. And the emotionality of the comment simply draws the user's attention to the details of the model, so they'll read a lot of facts and comments about the model, not just the negative ones. This is normal - after all, if, for example, a sausage manufacturer accidentally poisons you with their low-quality sausage, and you write a negative, emotional comment on the product page, you'll save many people from poisoning, as they'll research the company behind it, be more wary, and refrain from buying it for a while. The manufacturer will also change production to improve safety after negative reviews.
In general, with neural networks, as with any other technology, people go with the best, most convenient, and simplest technology. The problem with Pony V7 is that it's no longer based on Stable Diffusion, and it's already lagging far behind other models technologically. That's why people are upset - they waited almost two years for a new model, listened to Pony's creator's promises, paid him money on Discord for information and access to early generation examples, invested - and in the end, the model turned out worse than a simple fine-tuning of SDXL over two years ago.
It was exactly the same with SD3, when the creators promised a high-quality model, but instead released a terrible one, horribly censored, heavily compressed, and intentionally trained on bad data - all for the sake of preventing the community from "using the models ethically inappropriately." This undermined the entire reputation of Stable Diffusion, so all we're left with is SDXL, which is only surviving thanks to the best recent fine-tuning, until a more flexible, smaller, and more stable version of the model is found.
@miapipai LOL, let's not brings sausage analogy, is not that even close, since when sausage is used for gooning, and if you see the gallery you're understand why it's mostly a bad review, since very little use it to create a complex image composition, rather than t*ts and b**bs, and how can people telling a bad review since they're not properly using the product, and i can tell you this model is fine, just need minor fixing about prompt inconsistency, even better in some specific visual than flux or chroma, yeaah you seems enjoy toxicity and bullying like everyone else except in happens to you for no reason LOL. And what they're promised? a very good and fast model for gooners? bcs i have almost no problem at all using this model.
@N3kor0 I don't understand why you're reacting so strongly to literally 10 meme images from this model's gallery. Every new model on Civitai has dozens of similar meme images. And right now, literally 95-98% of the images in the Pony V7 gallery are people's attempts to create erotica on various topics.
The sausage example is just as applicable. If 10 perverts use sausage for something other than food, then the sausage manufacturer doesn't really care what these perverts do with it. But they will be attentive and sensitive to feedback about the product's quality.
Similarly, the author of Pony doesn't care about these 10 meme-y images. He only cares about the critics' comments, where they explain why the neural network model is flawed and difficult to work with.
Yes, perhaps Pony V7 will shine through fine-tuning and become a NEW standard and base in the world of erotic neural networks. Overall, that's what I expect, as do many Pony fans.
But the base Pony V7 model is definitely not like the Pony V6, which could work well without any fine-tuning. This is also why people who previously used Pony have mixed feelings about the Pony V7 – they also expected the Pony V7 to work out of the box. They didn't expect the Pony to perform and be released in the same way as the Stable Diffusion. That's all.
Note: I think most people don’t really pay attention to the "hater" posts from so-called gooners, but rather to comments like mine that have received many upvotes.
In my testing, I focused mainly on what AstraliteHeart said to have trained into the model: anime, cartoon, furry, and pony datasets. I also used his workflow and this guide: https://civitai.com/articles/21107/captioning-and-prompting-primer-for-v7
From what I’ve seen, the model’s knowledge on even characters with over 11k images on Danbooru is weak, still show hallucinated or missing details. Which is, in my opinion, disappointing, given that illustrious, noob, and even ponyV6 have no issues at all, accurately depicting those same characters in detail. Its the same for some concepts and if you want some niche themes, ponyV6 can do it, while V7 can not. Maybe its a flaw of AuraFlow, maybe not, but thats what i see.
@miapipai yes i think every model need fine-tuning to be better in specific area, but for base model i v7 already beat v6 in general purpose.
@Ikena every models hallucinate, so wdym? even flux sometimes hallucinate a lot, and MMDiT models usually quite sensitive to sampler/scheduler and prompts.
No issues at all? LOL, idk about you, but for me generating general SFW images with illustrious and pony v6 has so many limitations and hallucinating even more, it's just faster and so many loras that help fix that problem.
@N3kor0 I talked about the generel knowledge of actively trained in concepts/characters into the model. Not about limitatations and overall hallucination
imo Euler/Simple is completely incorrect. Images come out distorted. Almost all The Res4Lyfe samplers as simple work , especially deis_3m. Definitely need some sense made of "style_cluster###" it has the most affect on the image but has no sensible meaning to what clusters do what.
For auraflow, is there by chance a dmd lora equivalent that would work for Ponyv7? Apologies if I'm asking a dumb question.
Actually the adherence is great. Im browsing the gallery and it tries to generate everything, whats in the prompt.
Most of prompting are incoherent mess in every style(tag, chatgpt novel, natural language), but only questionable thing is the look of the output.
Definitely undertrained waiting for finetunes, which maybe wont happen.
What clip text encode are y'all using for this? Mapping Ponyv7 to TE doesn't seem to work and using Auraflow's built in TE produces bad results
Use the fp16 text encoder and VAE https://huggingface.co/purplesmartai/pony-v7-base/tree/main/text_encoder
drop the cover image onto your comfyUI. Make sure it is updated to get all the nodes you need Otherwise it will say "missing node".
The character knowledge seems rather lacking. [edit] On more testing, some of it might just be the scoring system being odd. Using the old PDXLv6 "score_9, score_8_up, score_7_up, score_6_up" instead of the recommended "score_9" seems to help, but it's still not great. [\edit]
I'm struggling to get a character that has ~2700 images on Danbooru (Azur Lane's Enterprise, whose been around for over 8 years now). It seems to be worse at higher resolutions. The resolution the example workflow comes with didn't even get the hair and eye color even in the ballpark and has a more semi-realistic/2.5D style. Dropping back to 832 x 1216 gets closer and gives a style closer to the Pony v6 default style (no style clusters prompted), but at that resolution why bother with AuraFlow instead of just retraining SDXL with a more modern text encoder?
For comparison, newer version of WAI-Illustrious and NoobAI vP1 can do characters decently down to somewhere about 100 images on Danbooru.
they probably barely trained danbooru and mixed a lot of things.
on site generation not working
It has an incorrect model type and a wrong license
It says "This checkpoint type (AuraFlow) is unavailable in the generator, but can still be featured."
@qek Says for me "A checkpoint is required to make a generation request"
@qek A few days ago I noticed that the category changed from PonyV7 to AuraFlow.
@QMCO21 It seems the devs don't wanna fix this: Pony v7 has an incorrect model type and the license is Apache 2.0. The generator doesn't support other AuraFlow models, it needs another clip encoder, Pony v7 was trained with a custom text encoder
On-site generation for V7 is back! @QMCO21 @qek
Umm...
KSampler
mat1 and mat2 shapes cannot be multiplied (154x768 and 2048x3072)
This is using a example comfyui work flow... What in the f...
That error is typically due to different models being used, or loras of the wrong model. Using sdxl vae on a flux base model, or 1.5 lora on sdxl model, for instance. Id check that first, especially for gguf model which also needs the right text encoder.
I believe pony v7 has its own of those text encoder and vae on the huggingface page.
Load clip type: qwen_image
Another promising SD1.5 finetune... Oh wait.
Maybe 2 more weeks? 😂
We definitely need to wait two weeks to see more funny comments about how bad this model is. I'm sure they'll be hilarious. And i hope they won't be locked or deleted in the near future.
@TroubleDarkness 1 comment got blocked, some ugly images have been hidden by AstraliteHeart
@2P2 Well, one comment isn’t a big deal. It was probably just the mods trying to stop the flood or hate, something like that. I’m not sure about the hidden images, when I filtered them out, there weren’t any at all. And honestly, there’s no reason to hide bad generations, because there aren’t any good ones anyway. 99% of the images look like SD 1.5 outputs and nothing else. That’s what happens when someone (not that I have any idea who it could be) uses tons of AI slop for training, and even promises to use more in the future. Anyway, at least, people are not blind.
At the time of writing, Pony v7 does not include a CLIP or VAE within its file. This means users cannot run local generations with just the model alone—they’ll need to manually download compatible CLIP and VAE files. If the model does embed its own CLIP and VAE, they’re not being detected by ComfyUI, at least in my setup. Hopefully, PurpleSmartAI will address this issue sooner or later.
No, works as intended
This is done for Aurora, so it won't work with forge/automatic without aurora extension and 25GB dictionary for aurora
@johnnywolf21 Aurora?
@2P2 *Auraflow
to be honest it's pretty harsh reading the comments, since the model itself used for gooning purposes, like most of its existence, and now the creator being bullied, like how people can be this toxic over AI generated images? FR? they're the one who hyping themselves over an AI model, and now blaming someone else for that, i wonder if this AI model really affecting their daily life, or it must be something very important to them, that push them to be this toxic.
If you write “toxic” one more time a good waifu fairy will visit you tonight.
I don't erp
@rainkola toxicity
@N3kor0 cutesy
@N3kor0 I find this backlash kinda adequate. V6 was something completely new and outstanding. It's is not only for gooning, I used v6 for both SFW and NSFW.
V7 was largely delayed, dramatically overhyped. People addressed their concern regarding AuraFlow choice over Flux multiple times. And this model, even being base model, with all controversial decisions is a step back. Several days after files are published - exactly 0 Lora's. Check what people submit. Some of the pictures are cute, but it is no comparison even with Illustrous.
Look at chroma. It is also base, it is just started, it has tiny amount of Lora's, but difference is dramatic. And it can be used instead of v7.
@hildezart726 i would disagree with illustrious, it's a good model tho, but it can't go further than booru tags to create complex image compositions/concept, without help from loras, block loaders if multiple loras were abused, face detailer, but yeah agree with chroma, even it's came out of nowhere, and no one overhyping it, still has mixed reviews about that, but yeah it's a decent one. On the other hand pony is not that bad, i have decent results on local generation, idk visual style like "chromatic aberration" is better on ponyv7 than in chroma, the only problem is to find sweet spot for sampler/scheduler combo, still experimenting on it.
@N3kor0 as far as I can see Chroma has 100% positive reviews :)
I follow what you mean, of course illustrous is limited by sd xl. But AuraFlow... damn, I still cannot comprehend it.
As I said, there are decent results, but, for example, I cannot use it in a way I used V6. whole clusters shit... It is just a management mistake. Previously you had to tag "disney" fe, not you should "cluster_123". How the fuck I memorize 2000 clusters? And why even should I? And they are assembled subjectively. It will not be pure "disney", it would be something that might remind disney, or might not
@hildezart726 Not exactly, chroma is still far slower than flux schnell, and of course ponyv7 is much faster than chroma like almost twice (5-6 minutes with q4 chroma), i know quantized models can have slower generation, but still it's not so practical to use with my current hardware, even when it's gave me fantastic results. Regarding to style cluster, i could see why people dislikes it, but for me it's better concept rather than biased heavily towards specific style, it's like generative roulette of styles, and they're still trying to address the issues with prompt inconsistent. In illustrious artist style tag, it's quite hard to control, sometimes i just use lora because easier to control, ponyxl also has similar treatment about style tags, and is much frustrating to use since it was singular and numbered, like i have almost 6000 images catalogue of style index, if you're talking about memorization.
I think the reason is because you need to wait very long for a single image that you get worse result than pony v6 that get you better result in few seconds. I needed to wait over 2 min with rtx 3060, 16gb ram running a gguf Q8. if you have a gtx gpu I pray for you.
@Dewal76 yeah i can do 2-3 minutes with fewer step + flash lora, but didn't like the result, 5-6 minutes is for 30++ steps, and 3060 offers 4gb vram than my ol' 2060 super and can turn tides on storing larger quantized models, also supported with sageattention+triton which doesn't support rtx20 series, but it can't be much faster than 6-7s/it since 3060 are not outperform 2060s that much, i feels rtx20 is already hit the wall with current MMDiT models, feels like running sdxl with 4gb vram.
@hildezart726 Auraflow was a good choice. IT's one of the most underappreciated models. PixArtSigma also underapreciated. Such great creativity and good clip models for better understanding. Flux a non starter because of the license. Also flux needs more vram so a lot of people didn't want it. The quants just kill ultimate quality. Nothings perfect. If you know better go make one and see how that goes.
@EricRollei21 that is just false. I generate both on my laptop with 3060ti 8gb with both Flux and Chroma Q8 16fp and have, imo outstanding results. Of course full model is better, but it's enough for me.
If AuraFlow is so good, why it is underrated?
If there are license problems, how Chroma exists?
> If you know better go make one and see how that goes.
Just applause. Standard take for any case. I did not say I know better then pony author, I say that there are management decisions made, with which people disagree. People may like or not. If you do something, present it publicly and especially take money for it - be prepared for critics.
@hildezart726 Auraflow was definitely appreciated - I made some incredible images with it that I didn't get from flux because Auraflow does artistic stuff better natively and has really good understanding for prompting. I believe mostly Auraflow didn't get traction because all the other new models coming out after and also most people don't know how or don't want to write a long detailed prompt.
@EricRollei21 would you care to share those results? I might agree that you might have some, but highly disagree that you can get same from Flux
@hildezart726 ponyv7 was announced like mid last year, at the same time sd 3.0 has quite controversial license, before they fix with with sd 3.5, but that was too late, and flux released like on august last year, so the only choice was auraflow, and i believe they don't have future sight to predict flux model, or why they wouldn't just wait for "better" base model, since as a user idk about fine-tuning businesses, meanwhile chroma was trained like in march this year, i could be wrong, but there's a 1 year gap between ponyv7 and chroma, and idk about "taking money"? i assume is about buzz? if that so, i would disagree, since the model is free to download, and of course generation service is not free for people without machine to run the model locally.
What i've seen so far is not a critics, it's just cheap bullying for something mainly used for NSFW, just look at the gallery...they claim ponyv6 is better, i mean generating p*rn cartoon doesn't really need advanced model or that much creativity anyway, since only few push this model to create something complex, and i can tell ponyv7 outclassed v6 in general purpose.
@hildezart726 sure with the right lora flux can make a lot of images, but without it flux has a hard time with making art. PixArt Sigma and Auraflow and SDXL were better for art out of the box. Flux is better maybe with realistic stuff, but not at all perfect without the finetuning. I stopped posting images and models here on civitai for the most part. If you are curious about auraflow do try it yourself. I can't spoon feed every one on the internet and I already know how it will go - I'll go to the trouble to find and post some images and feckless trolls will come out and I'll waste even more time. It's like politics now - no one has an open mind and already have formed opinions and can't see the truth in front of them. If you sincerely have interest - go try auraflow and also pixart sigma but either use a prompt expander or spend time to write detailed prompts because this is where those models shine.
@EricRollei21 actually I now tend to agree with your point. AuraFlow has pretty good results, which I missed. And I would agree that it's good for "2d", and Flux is good in realism. But so far I can't see that in V7. Of course most of the people click "make tiddies". I agree and I will try it myself locally.
@N3kor0 man, you are actually strange. This is internet, people anonymously write shit about each other. There are a lots of garbage, but there are plenty of valid critic points. And in your timeline you have logical issues. If Flux appeared after AuraFlow, then Chroma had less time to release, isn't it? Taking money is about their small website.
Summing up: AuraFlow better for images, therefore better for V7. But I can't get over this cluster_123 shit, I just can't. And it is model agnostic, it's just a decision. I don't mention hands because they might be better on samplers which are simply not there on civitAI.
@hildezart726 yeah bullying seems fun and games till it happens to you for no reason. Man idk why, it could be dataset management, different timeline schedule, or anything, like i said idk much about fine-tuning business. Donation is fine man, in the end nobody forced to pay anything, i downloaded and used it for free. Btw there's a cluster index if you're confused, and for me it doesn't matter, nobody remembers named artist tags anyway, so in the end either with names or numbers, you still has to remember it or look back into the catalog.
@N3kor0 @EricRollei21 Yeah, I honestly tried. From good things - I was able to load full model, which is truly good. From time perspective, works same slow as any Flux model out there. On my laptop 12s per step. 6-7 mins on a picture.
Hands are somewhat better with deis_2m + beta57, but still having some issues.
Still fucked up by clusters. I checked the docs, did not find any index, so used some number from examples. Without it, like a classic v6 without style - burned out something. Wanted to try something comic-book, well, even by the author's docs mixture of styles is somewhat impossible because of T5.
Could you please give a link to style clusters index?
@hildezart726 I think the best part about choosing aura for base isn't the trained weights starting off from( though aura does naturally lend better to the kind of images people use pony v6 for than some super realistic base) but instead is the clip choice. People can then use more tokens and a broader vocab to more accurately prompt for what they want. I threw really long prompts at it and was amazed.
Agree that v7 has a long way to go. You can read the v7 training article Fictional posted here on Civitai about how they ran into issues training and ended up with the style clusters. It's a good explanation and also interesting to read from a tech point. I think the sharksampler or clownsharksampler produces better results, but still it's not perfect. Hands and faces need fixing. Not sure about sampler/scheduler settings for best results. I used res2 and bong tangent but did not play with those. Instead try prompting with more detail about the face (shape, eyes, expression, mouth etc) and the position of the hands (open closed fingers, holding somthing, gestures, etc) and that seems to help.
As far as the style clusters - I did find several sites where people had run generations of the same prompt with all the 2000 combinations, but really looking through all those is tedious and I'm not that invested into pony 7 to really study them, and I'm betting you are in a similar boat. I have not seen a comprehensive list with descriptions.
I have just download the Chroma radiance ckpt (it's the one which skips the vae and works in pixel space) and am really interested to see where that goes.
@EricRollei21 regarding clusters - found this exactly. I have no will to look through 2000 images to get what is needed this exact time.
It took me somewhat like a whole day to create a workflow for V7 using clown sampler, with hires fix, hands fix, face fix and so on. Results a way better there with exponential/res_2s + beta57 without clusters. Hands and faces are more or less fine if you use custom sampler in combination with clown sampler. But I cannot say that I got result which I expected. Will upload it later, when I adjust prompt and make few other attempts.
Funnily, I applied knowledge from pony v7 research onto Chroma and results became way better already there.
@EricRollei21 Nah, I give up for now. This is the best I got https://civitai.com/images/108478256
Generation is unstable - each seed gives absolutely different style. Faces are smudged.
@hildezart726 yeah, I didn't play with it for very long. But I hope some will make some fine tunes for it.
@EricRollei21 but have to say, that prompt understanding seem to be indeed better for art in AuraFlow.
And just for example results with the same prompt on Chroma:
art: https://civitai.com/images/108483493
photo: https://civitai.com/images/108490174
both are just first generation
@hildezart726 thanks, tried to find better sampler/scheduler combo, some said clownksampler work the best.
It's a spirituality thing. Waiting for Pony v7 and other tools are like long virtual pilgrimages. There is an obligation to at least do a decent job, AuraFlow v0.4 was not even a thing to soften the blow. At least Pony and Chroma are allies to soften things up since the former can't take the risk, and are also replacing proper nouns with clusters. BUT if Pony v8 is Qwen-Image based with Lighting LoRA, it pretty much solves a lot of problems (e.g. base model lienceses) sans red tape (e.g. replacing proper nouns).
Seems someone had enough buzz and gave 69k yellow buzz on this page, so they appear on this (Pony v7) page, lol
Turns out, a lot of the issues of the model can be resolved by using a better/tweaked workflow. Kygur (on the model's Discord server) posted the one used for https://civitai.com/images/107895843 - results are still not amazing compared to high-end models, but are more than usable and stable unlike relying on the Simple template given out with the model, or relying on random results.
The model's capacity to follow exact instructions is actually shockingly good.
WTF are these "chairs"? Sorry man, this is not "usable" in the end of 2025.
@somedoby The right pony has weird eyes, the eyelashes are different, smth with the right eyebrow, the mug melts... in 2 words: AI slop
@qek @somedoby I made it with only 20 to the reccommended 30+ steps.
I also used a lower resolution than recommended. So these are some reason why the details are more off.
Anyways, you try to get any ill/noob model to get these interactions between specific characters.
Where exactly this one is wearing that, and exactly that one is doing this.
V7 seems to be great at this kind of prompt adherence where others fail.
This one: https://civitai.com/images/107895371?postId=23914375
- is same seed/settings with 30 steps instead of 20, and higher resolution. And you can immediately see less faults.
@nogo it looks blurry
@qek Blurriness is due to lower CFG, I may need higher to avoid it, but with higher CFG the colours/lighting tend to become burnt.
I'm still experimenting with the settings distribution between CFG and tokenizer padding to alleviate these issues
@somedoby @qek The floating cup, and bad chairs can also be attributed to the fact that I forgot to mention them properly.
I forgot that I had "mug" among the last tags. I didnt mention a table, or anyone holding a cup or cup on table in natural langauge.
Partly the chairs are fucked because I wrote "sitting in a coffee shop", I didn't mention chairs.
Mentioning the objects you expect to appear helps a lot in this model.
I'm not saying the model is amazing, but once you have a good base prompt and settings, you can expect sometimes good results with way better understanding of the prompt than any ill/noob based model.
Yes, adherence is great in a sense, it draws everything, whats in the prompt. The coherence, style and output is questionable quality though. Nat language seems best. Short sentences and be coherent, what you want.
@nogo If you inpaint and upscale, it will look better
@qek no shit
the absolute state of slop is crazy rn
runs fine - but getting this error with the simple workflow - Error running sage attention: Unsupported head_dim: 256, using pytorch attention instead.
I can disable sage attention... but I use it for WAN. It's coming from the clip custom one provided... any suggestions?
nvm got answer... thanks! it's known and expected with sage attention.... have to disable it if don't want the errors
I'm having an issue getting this to work.
Which Text Encoder and Vae are we using?
The vae is here, and the text encoder, both from the official upload
Does it work with Forge or do I need to ComfyUI this? I have both, but I didn't want to claim it doesn't work without seeing first. Thank you for the replay feelow creator.
Looks very good! Thank you for all that work! Amazing start! I'm using OliviaRossi's workflow. I I see a call out for photo realistic style and anime . Curious what other style references there are if any?
His workflows are trash
@qek What? A typical comment from a Zero user. Zero models, Zero images. You have nothing posted nothing to share so your opinion counts Zero.
THIS COMMENT IS A SOCIAL POLL. ANSWER IN THE COMMENTS.
People who think V7 is a bad model. Do you realize that this is just a base model, serving as a future foundation for other models? I'm not insisting that anyone will develop this foundation into something more, but the very fact that many don't understand what a base model means is alarming and concerning. It's not the same as the Flux model. Remember the results we got using V6 and ask yourself how the current situation differs from the past.
In fact, if you use an alternative workflow, the results are quite good.
I sincerely look forward to the moment when people with the resources and capabilities will take up the development of this model.
I believe we should be grateful to the model's author for providing the community with a theoretically excellent opportunity to produce high-quality models where anyone can write prompts using natural language. I can no longer physically write my prompts using the schizophrenic method of using tags and concepts for SDXL models.
I tried v6 for the first time on 2024/02/06, quoting my note "Didn't like it enough because it sucks at realism". The base model wasn't so bad, I was able to get some sloppy, but pretty images, not realistic, of course. I continued to use SD 1, note that I was a noob, had a skill issue. I had v6 anyway and I saw someone making cool realistic images with it, I tried to replicate them, downloaded some loras. The outputs were ok, but not perfect (some anatomical anomalies, but easy to inpaint). Pony Diffusion v6 works better with style loras. I tried my best anyway. Stopped using SD 1 on 2024/04/19 because I found a very cool merge of v6, I really liked it.
What about v7? Not surprising, hard to use, slow, have to use quants, its outputs look like they were made with SD 1. I mean that v6 wasn't treated like we have been treating v7, trust me :)
Here's why the comment is verbose and focuses on v6. It is what you wanted
People's dissatisfaction is completely understandable. This model is called V7, not something else. Accordingly, it is supposed to be an improvement over V6. The basic V6 produced very good results when it came to generating images with ponies, and V7 does even worse than that. Take a look at this image https://civitai.com/images/107835594. It's an absolute nightmare in terms of anatomy, even though the person used a very detailed description.
Here is an example of an image from V6, created in the Discord bot https://tantabus.ai/images/12477.
So which one has better quality?
@foxlover7796 You can compare your images made with EasyFluff v10, Pony v6, Illustrious XL, and Pony v7 (if you tried it yourself). Your first published image (made with EasyFluff v10) looks better than all that Pony v7 slop. And yes, I remember you :)
@foxlover7796 Regarding my image https://civitai.com/images/107835594
The anatomy is honestly not bad. Could be a lot worse. It mostly makes sense.
I also used lower steps and resolution than recommended, because I like the quicker gen speed.
21 to the 30+ reccomended steps, and below 1000 to the reccommended 1250-1560px size.
Also you can't just pick a very specific image to compare with which you don't know which model was used, which loras, if it was upscaled and img2img, inpainted. That's just clearly biased
Besides, v7 seems to be much better at prompt adherence than when it comes to other models.
Getting an image where x character wears this, and y character wears that, and x character is doing that to y character etc..
That stuff is not really possible in any ill/noob checkpoint. The best you can get is to name two characters and add "hugging". But specifying who is hugging who etc. that doesnt work.
In this regard v7 is above the others.
It would clearly be superior with the same amount of time for fine tunes. Some of the commenters here have so little experience and are just bringing hate for no reason. It took quite a while for any of the base models to become good through all the fine tunes. Of course most of the whiners aren't going to be doing any of that or even building workflows. They just express the worst part of the internet. Wanting sh1t for free, nothings good enough including them but they just don't know it.
The question is whether or not anyone will spend the compute to fine-tune this, when there are so many other models available. When V6 was released, there weren't many options. That's no longer the case.
@EbenezerDanglewood The cost to fine-tune an SDLX based model is also significantly, significantly cheaper, less time intensive, and easier.
@EbenezerDanglewood Fair question, but why is it that so many new lora and ckpt are still being released for pony? It's primarily because it excels at porn but also because it's got a small vram requirement. SD35, pixart sigma, aura, highdream all got the short end but somehow pony kept getting the usage. Wan2.2 makes great images, Hunyuan 2.1 also and I just got some great images from Hunyuan 3 (but a bit too much wait) so hard to say if Pony v7 will be too little too late or not. One thing that sucked about pony v6 is prompt adherence for more complex things so let's see if 7 is better.
@EricRollei21 Eagerly awaiting your V7 fine-tune. While you are at it you can also implement Lora training support to all the popular trainers.
Jokes asides - we no longer live in a world where Pony is the only good base model. If I had a choice of fine-tuning V7 or another model I would choose Chroma instead.
But the bigger issue is the fact that trainers don't have support for Pony V7. The only tool that has it right now is SimpleTuner but its maintained by bghira who is a bad actor.
From my experience so far with v7, it takes more work to get good results and can be wildly inconsistent at times. However, it understands prompts a lot better. With V6 if I described to it multiple characters separately and specifically, it was a miracle to have it actually generate the specific characters together without giving the wrong features to the wrong characters, like the right hair color, but swapped hair styles, swapped facial features or clothing elements etc. v7 Can understand prompts of higher complexity, and while it takes some work to get it to composite the scene the way you are imaging it, it consistently gets a lot of the elements correctly, even if it doesn't compose a scene that makes sense perspective wise between each character, or if it screws up proportions and anatomy etc.
It feels like v7 just needs more time training its dataset or something. As well as some more supporting documentation about special tags it uses. "Style_Cluster_####" Is probably the most annoying tag to fight with without spending hours doing tests to figure out what style cluster looks like what, what it's strengths and weaknesses are etc.
Overall I like the new model. It has a lot of potential. And I'm sure some well equipped peoples will make finetuned models based on this to focus things up.
@randomredmage People have already documented the style clusters u can find zip files on the discord with examples of every cluster
@tosermepls What's that expression? "Beggars can't be choosers." Mostly my comments here are in response to all the ungratefuls who post hate when someone spent a ton of time and money working on something they are giving away for free. I stopped uploading my models here on Civitai mostly because of Civitai policies but also because so many people expect to get the good stuff for free and never even say thank you. But yeah, why fine tune V7 when Fictional already wrote v7.1 is coming soon and then even said v8 is in the works. And as you said there are several other good models. Personally I'm looking at Wan2.2 for image and movie generation and also Qwen. Not really Chroma right now, but I am following Loadstone to see if he gets the vae less pixel based version working which would be amazing.
@qek it seems either you're not properly using this model or simply just generating nsfw, if you did, i can agree that generating nsfw doesn't really needs to write an essay level prompts anyway, it's not that rewarding for the troubles, tags is the best for that, and all the latest MMDiT models are slow, so?
@nogo I have downloaded one such archive of style cluster examples. It's nice to see, and it has given a fairly ok general view of some of the style clusters. The models general inconsistencies cause some issues. v7.1 hopfully soon to get that in order.
But it doesn't change the issue with the tag itself. It's a minor gripe honestly. The archive I downloaded has helped a lot, I just feel like I need to make a few prompts, and go through the styles for myself and build out a stylesheet that shows the same prompt in the different styles. As seeing wildly different prompts displayed in different styles doesn't feel as representative to me as it would if it was the same prompt in different styles. using the same seeds. if that makes sense.
@randomredmage There are zips with every cluster in same seed and prompt. You probably found the wrong one.
@nogo Welp, yea if there are ones organized liket hat then yea, I definately got the wrong one lol.
@randomredmage Here, this one was just made https://filebrowser.glimglam.org/share/NhyT-_Pp
@foxlover7796
You can achieve better results with ClownsharKSampler.
(it is slower compared to the Ksampler)
https://civitai.com/images/108323845
https://civitai.com/images/107672647
https://civitai.com/images/107779755
https://civitai.com/images/107803296
(more on the profile page)
Base Pony V6 / base NoobAI works much faster to get garbage result. Pony V7 works much slower and output the same garbage result like it was on outdated SDXL. Also, if you put more effort on base Chroma HD instead, you will get decent result much faster than with Pony V7 and it can output decent result without any advanced workflow based on ClownsharKSampler that make generation even slower.
@YetAnotherAIuser It's really sad that when he was choosing the base model for the seventh version, there wasn't a decent option. I think he should have waited a couple more months for other models to appear.
This should be called anything but the Pony V7 Base. It's an insult to the memory of the Pony V6.
I did some semi-scientific experimentation to compare gguf fp8 and safetensors fp16 after I had an instance where gguf gave noticeably better hands than safetensors. I ran 16 images with the same prompt and same seeds between the versions. Resolution was 832 x 1216. I'm using this lower resolution so I can have a few spare GB of VRAM and for speed. A few things I've noticed:
- Safetensors fp16 is slightly faster on my 4060 16GB, about 3.04 sec/it vs gguf's ~3.2 sec/it
- Neither gguf fp8 or safetensors fp16 seems to be better at hands, at least not enough to notice in 16 images, but sometimes one will give a good result when the other doesn't. Usually they're both pretty bad at hands compared to current SDXL checkpoints.
- Sometimes the model just ignores the character I asked for (AL Enterprise) and produced an Asian-ish woman in a semi-realistic style. Potentially bleed over from cosplay?
- I found the base denoise of 1.0 in the recommended and "improved" workflows to be too high, the image doesn't seem to ever converge. Adding a few steps can significantly change the image without improving the quality. I prefer generating at 0.95 denoise then "refining" at 0.55 (like you'd do for high res fix, but without upscaling) to work decently.
- Euler_ancestral works pretty well, but I like generating with a dpm sampler (currently dpmpp_2m_sde) and refining with euler_ancestral.
- Style clusters may also impact the hand quality, needs more testing, but that's a lot of GPU time at ~160 sec/image.
Not sure if this model will ever displace Illustrious/Noob, I just enjoyed fiddling with a new model.
Bro, you could try using an advanced workflow with cascade generation. The images will be of higher quality, but at the cost of being three times slower.
bro pony v6 itself is very bad too. just try using pony v6 base. it is just base model. chill out. checkpoints based on pony v7 will be great like cyberrealistic pony, prefect v5 pony etc
No, V7 works worse than V6 out of the box
>> checkpoints based on pony v7
What checkpoints? Nobody trained a single lora for this model.
@somedoby What does that mean? Isn't it possible to do that? I mean, the model is new. Isn't that why it doesn't have LoRa?
@pixiv000001714 This model is new but it is based on old and dead auraflow architecture. This arch is not supported in popular apps like trainers etc. And even if support will be added training of this model will be very expensive and resource heavy unlike SDXL. That is the reason why AuraFlow was abandoned in the first place. Even generating images locally with this model is too slow for most people.
"pony v7 will be great like cyberrealistic pony, prefect v5" like a step back lol
Online gen still isn't back.....
Due to its wrong "base model" (must be Pony v7)
@qek It's not wrong. Pony v7 is based on AuraFlow
@nogo It is wrong! The original AuraFlow model needs another text encoder, the civitai generator supports Pony v7, but not other AuraFlow models
Try Pony V7 Base on the civitai create page to get an error
On-site generation for V7 is back! @qek @Tedroman
The quality of images generated by Pony V7 can vary significantly. For high-quality results, use a detailed prompt with the style_cluster tag. It is also highly recommended to use ClownsharKSampler.
Useful links:
- Model
- GGUF
- Encoder
- VAE
- Simple Workflow
{kind=link}
Thanks for the model! The feedback’s are pretty harsh — expectations were sky-high after V6’s success. It must’ve taken an enormous amount of work to get such a result with a model that’s still relatively little-used and with less widely shared general knowledge around it, which, technically speaking, must have made it quite a challenge to work with.
Personally, I’m having a bit of trouble getting outputs I really like, so I need to figure out how to balance quality and precision across the different style clusters. Can’t wait to see how things evolve with Pony Diffusion 7.x and 8, as well as with the merges.
and it only took him two weee,,,,
@zekses xD Yes, but it's okay, he/they took the time he/they needed. Now I get pretty great results in photorealism, but rendering is quite slow, even with my RTX 5090. Around 100 to 120 seconds for a 1280x1024 image.
Diffusion v8 will be based on Qwen-Image to dodge whatever red tape is on FLUX. HYPE.
@TomLucidor qwen is very great, I'm waiting too.
ight y'all, let me know when it's possible to train loras for this model on Windows (since SimpleTuner seems to be linux only)
@qek THANK YOU!! Now I gotta find a way to run it with ZLUDA cuz my stupid ahh bought a AMD card 😭
@CappyAdams Note that I don't use that trainer
@qek understandable, it looks complex XD
SimpleTuner has experimental windows support via WSL afaik - https://github.com/bghira/SimpleTuner/blob/main/documentation/DOCKER.md
Edit: Nvm, seems to be CUDA only in this case
@Fuhrriel I'll take a look at that. also, ZLUDA is basically CUDA for AMD and with the correct modification, almost any software can be used with ZLUDA (I'm pretty sure)
Windows Subsystem for Linux (WSL)
People still use windows in 2025?
@chrislgolden130 most people don't care what OS they use, as long as it can do what they want or need it to do, i dual boot for the best of both worlds (compatibility and freedom)
This model is interesting in several ways. It preserves details better and maintains greater character consistency overall. Its understanding of natural language brings it closer to Flux, rather than offering a fundamentally new experience for anime-style generation.
However, its biggest drawback is the generation speed. With comparable parameters for resolution, sampler, scheduler, and CFG, it runs about 2.5 times slower than Flux. In some workflows, the difference between SDXL and Pony7 is even more dramatic — it can be 7 times slower (as seen in a basic workflow from the official repository https://huggingface.co/purplesmartai/pony-v7-base/tree/main/workflows) or even up to 20 times slower (like in this advanced CivitAI workflow https://civitai.com/models/2075661/pony-v7-advanced-workflow?modelVersionId=2360891).
Because of this, we’ll likely have to wait for optimized checkpoints, DMD-like LoRA equivalents, or other performance patches before it becomes practical for everyday use.
@qek How it is, in comparison with "Illustrious" ?
@settima_ai Even worse than SD 1
@settima_ai In terms of quality, Pony7 is currently closer to NoobAI base model, although in terms of the number of tokens counted, it's closer to Flux. Imo.
@ripemist14286 No, more like it's closer to Neta Lumina
Lightning BF4. We will need that
Discovered "pony v7" just today: how about LORA compatibility?
Needs new loras, there are currently 3 on site.
@J1B So, is NOT compatible with standard Pony???
Very bad... SD is becoming real Babilon....
@settima_ai Its is a completely different architecture based on AuraFlow a 6.8 billion parameter model, it was never going to be compatible with existing LoRAs, that would be like breading a cat and a dog.
@J1B *5 on the site
@qek Ok, I understand... but so why calling it "Pony"?
@settima_ai It's called Pony V7 for the same reason that Pony V6 is called Pony V6....
And the same reason that Pony V5 was called Pony V5.....
@nogo Pony Diffusion V6*
@settima_ai It was supposed to be called Pony Diffusion v7, but it's Pony V7 now. Pony Diffusion used to focus on MLP, but the creator decided to expand the dataset. It seems Astralite added photorealistic content this time, it wasn't done (or not intended) for v6. And the creator is a brony 🐴
@qek We are all bronies. I've been using it since the early days of v1
@nogo Not everyone is, and it's good that Pony hasn't been limited to MLP and SFW, v1 was limited to such things
I hope that sageattention will be supported soon... I'm no longer used to waiting a long time :-D
Will this work with forge?
@Bandi_Alter Who uses SD WEBUI in 2025?
@Bandi_Alter Don't know, my best guess is you have sage installed or something else with forge, I heard that kinda stuff doesn't work with aurora / v7. Best to check / ask over on the purple smart discord for help.
@qek I also use Forge and I’m very happy with it.
@qek Thanks for the contribution -- very helpful.
@qek Not everyone is autistic enough to wire up everything manually in Comfy.
I think the lesson for everyone to take here is:
If it isn't broken for you, don't try to fix it.
Make use out of what you have.
Ironically what I've learned over the course of time, especially with Illustrious models is that "new model" doesn't always mean better model, but infact most of the time touches being a "different model". Nova Animal v3 is my best example, perfect balance of realism and digital art, whilst every version after is hyperrealism and niji style.
Recently I cam back to Pony, Confettimerge, and tried out Prefect.
The original Pony however, despite it being a little rusty in comparison to the other two with the better U-Nets , still it has an amazing amount of charm that comes with a vast amount of community resources.
This comes after a time at scoffing at Pony gens when you see them all because "oh that's old".
In reality, a good wielder of Ponyv6 (or any Pony based model), doesn't generate in a manner that exposes the model infrastructure.
It also doesn't murder your GPU and put your PC in cardiac arrest like Illustrious models do.
Overall, it kind of reminds me of the SD1.4 NMKD days...
I know I kinda when off on a tangent. But another thing I suggest people do is delve back into regular SDXL models as well with DMD2... seriously better results than FLUX.
I'd say the one edge FLUX still has over all other models is its ability to write text and add product placement, but that's literally it.
I believe a day will come where all of these models run at a compact size of 4gb VRAM, despite quality or any of the other required resources considered now. 🦄
Not sure the thought process the author had when they picked the platform to use:
"Hmm, let me pick the most outdated, obscure diffusion model I can... Arua... arira... auraw... whatever, I'll take it!"
well they had it coming, no wonder the community is currently pretty harsh against pony7, base model or not, who cares? i dont and most of us dont. they went silent and took two years to train next model, and by the way for those who saying that to forgive pony v7 cause it is just a base model? bro illustrious 2.0 and illustrious -xl are base model, but people trained better refined model. I think it is better to say that pony v7 is a bad model trained on aurora or whatever name it is. if anyone could run a 30GB of library to run Pony v7 then i bet they will definitely go for better choice than pony v7 if they have such local compute power. i think pony v6 was the last and good thing we will ever get from purplesmartai
结束咧!已经结束咧!
I appreciate the hard work that went into making Pony 7. It's not giving me that oomph that Pony 6 or Illustrious/NAI gives me. It's great that it uses an LLM for better understanding, but the results aren't an upgrade.
Good lord it looks like crap! .. Is that all below from people forcing old and new against its will?, or is this the process of cavemen stumbling into a unused monolith. I want to say its hate, but even the good stuff looks more "" *soulless and unobtained compared to what's currently popular. ""
Oooh its got an *ad for a app.
That explains everything now.. :\
TLDR
Overly ambitious don't broke what ain't fixed nothing burger..
2 years for this? at least it's got trained data from a 15 years old dead fandom, I suppose.
if you want a model that makes you wanting to bash your head on a pinched nail on a wall, with sentenced captioning mixed tags, at least use netayume lumina, at least it doesn't look like dogshee
this runs like shit
the prompting experience is horrible, spoon feeding every detail to the model feels unrewarding when the result is mediocre, my theory is that too much literal descriptions in their training data made the model unimaginative, like an art student who only learned to draw from example
Jeez it's that terrible huh . . I'll add this too a list of never using it.
The only thing I like about this model is the consistent color generation. Like generating characters with my national school uniform for example. The rest? Just some turmoil
ILXL still reign for prompt adherence. The thing that I don't like the most about ILXL, it's constantly updated with new versions in relatively short time
Im really saddened to see such an amazing project go down in flames. Pony V6 was amazing and while it lacked artist styles.
It taught many of us how to make our own lora's based on various artist. Youre amazing project got so many people involved in SDXL.
You guys practically put SDXL on the map and I'd go as far as to say you paved the road for Illustrious to come about. But V7 is really awful.
I have no idea what the goal was here, but it seems more about making money based on how the extreme artist censorship and style fiasco exist for some reason. Not to mention this whole "fictional" bullshit who knows whatever the hell that is. Theres no telling what the future may hold for V7, but it doesnt look good right now.
This model is ahhh, predictable to anyone who followed its development.
Can't wait to see who will try to fine-tune this, good luck /s
@PurpleSmartAI, I want to use this model here to train a LoRA, When will be possible use Pony V7 for LoRA training in this site?
Oh good lord almighty what did you guys do...?! This is one of the absolute worst base models I've ever seen! Complete horse poopoo ironically enough... for a model literally called PONY it can't even get mlp characters right! Doesn't even know them for that matter... gosh what a waste... normally I'd say just wait for some people to fine tune the base model into much more quality adjacents but this base model doesn't even fucking know fictional characters without needing a lora! Who'd use this?! And why??
What is Zony v8? A Z image fine-tune? https://huggingface.co/purplesmartai/zony-v8-256px-exp-de-distilled
I see the vision
Does it work on Stable Diffusion Forge? because it tells me it doesn't recognize the type of model
why nobody use this?
Quite possibly the biggest wasted effort in this website's history. Such a shame...
silveroxides removed silveroxides/pony-v7-base-fp8_scaled-and-GGUF :/
so it is been more two months since model was open for lora training and tuning. I keep coming here once every couple of day, to check if something changed. Guess the king is dead, long live the king.
It is a shame indeed. Chroma is good, but a bit too heavy for the most people, Z-image is good, but prompt adherence, chinese bias and censorship. Guess we are stuck for a while with illustrous.
Does it work in Webui ? I tried and got some damaged images .....
R.I.Pony, you'll not be missed.
Astralite decided to rush again, I see their new project Zony 8, I hope it's just a test and won't be a poor base in the future
Naaah, I was waiting for V7 here for a long time without porting my loras to Illust or Noob AI.
What a dissappointment, hope this will be better during time, now it is complete unusable.
last time there was a vae recommendation. What should I use?
Bro didn’t actually push out a new model, they just took an old one, downgraded it, then republished it. Not only that, they slapped an advertisement at the top before going into any details about what’s new. What a sellout.
This is what happens when you don't give a fuck anymore and your priorities become money over quality.
What on God's green Earth is "style cluster"? How many are there, what do they do, why isn't this explained?
The actual surprise here is that people were genuinely hyped for this especially after the whole roadmap and spec/requirements were released. I knew this was not going to go well at least a year and a half ago, but wow.
V6 was already filled with awful ideas so this was like the easiest prediction but in retrospect you could tell it was carried by SDXL and its more larger dataset(despite the e621 debuff). Also whatever "dominance" it had was immediately usurped by better SDXL models released mere months later.
Anyways this is actual proof that money and dataset alone doesn't result in a good model.
Even the creator admits that the model is bad, look!
🤮 "this is a combination of outdated VAE and insufficient training"
🤮 "This model does not support text generation and has degraded text generation capabilities compared to base AuraFlow"
🤮 "Artists' names have been removed and source data has been filtered based on our Opt-in/Opt-out program"
🤮 "Any inappropriate explicit content has been filtered out"
🤮 "Special tags have much weaker performance compared to V6"
🤮 "help shape our future" 🙄
v6 is better and yet older...
Is Pony v7 a variant of SDXL and will some SDXL loras work with it like they do for Pony v6? And, for that matter, will Pony v6 loras work with Pony v7?
Reviews: "Very Positive"
Seems legit.
Is SimpleTuner the only tool available to train Pony V7 loras?, I want to receive replies from anyone who made at least one Pony V7 based lora.
I'm asking this because SimpleTuner is being problematic for me to install and configure.
🦄 Pony 7 LoRA's
You can talk a lot, but after a while, the number of LoRAs a model has really shows how interesting and good a model actually is. I took a look at this once at Pony 7 and found out something interesting!
Since its release, there have only been 18 LoRAs for Pony 7 on this website.
12 of a total of 15 accounts had not created anything else before, which clearly suggests, given the date on which these accounts were created, that these LoRAs exist solely for the purpose of promoting Pony 7. So most likely, these accounts were created specifically to make it look like different people were actually interested in it! In other words, it's fake and a scam of the community.
Account - date of creation - total number of loras
aDwarfNamedUrist - 2022-12-10 - 1
ayeSOMA - 2023-06-16 - 1
bootylicker - 2025-11-19 - 1
christophherman - 2026-02-09 - 8
Fuhrriel - 2025-08-04 - 3
inkdass - 2025-03-14 - 1
Mistermango23 - 2025-08-14 - 19
monikaloopez99712 - 2025-11-28 - 1
prestasero519765 - 2024-07-23 - 1
Reakaakasky - 2024-06-22 - 20
sithlordspawn666 - 2025-12-30 - 1
sergioduran - 2025-01-23 - 1
soysilvialuz645 - 2026-02-11 - 2
tomasantonysales234 - 2025-01-07 - 1
wolveriene144894 - 2026-01-08 - 2
Is there really any more proof needed that Pony 6 was only used to squeeze as much money out of us as possible with a Pony 7 version that was already known to be extremely poor in advance?
Where is the promised 7.1?
We can hardly wait!
Looks like oversaturated hot garbage trained on sd1.5 renders. Hard pass.
still NO finetunes to make it actually usable compared to Illustrious
If the model is less superior to its ancestor, then it's gonna be harder to finetune
@elevendr true, plus its not based on SDXL, but some obscure model. they should make a v7.5 based on Z image turbo if they want a similar community engagement as v6 got, but at this point it may not even be worth it
After all the testing, I still don't understand this whole timewaste of a checkpoint.
It's an example of scope creep, perfection being the enemy of good enough and a consumer base that expects too much from a relatively new product.
my own 2 cents is total confusion. It apparently doesn't work with stable diffusion and finally it's not a waste of time if you didn't invest any into it. It's a waste of SOMEONE'S time (and money and effort) but as long as it's not yours then it's a free lesson learned.