Wan 2.2 14B i2v & t2v Enhanced Motion + 5B Latent Upscaler - Ultimate 6 Steps HD Pipeline
The ONLY workflow you need.
Fixes slow motion, boosts detail with Pusa LoRAs, and features a revolutionary 2-stage upscaler with WanNAG for breathtaking HD videos.
Just load your image and go!
🚀 The Ultimate Wan2.2 Workflow is HERE! Tired of these problems?
Slow, sluggish motion from your Wan2.2 generations?
Low-quality, blurry results when you try to generate faster?
VRAM errors when trying to upscale to HD?
Complex, messy workflows that are hard to manage?
This all-in-one solution fixes it ALL. We've cracked the code on high-speed, high-motion, high-detail generation.
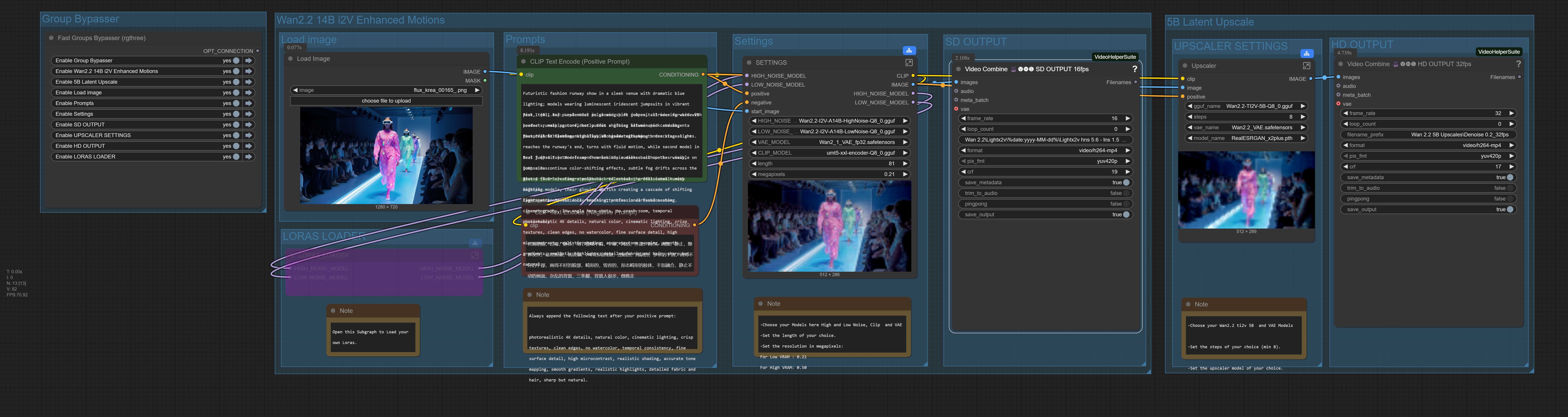
This isn't just another workflow; it's a complete, optimized production pipeline that takes you from a single image to a stunning, smooth, high-definition video with unparalleled ease and efficiency. Everything is automated and packaged in a clean, intuitive interface using subgraphs for a clutter-free experience.
✨ Revolutionary Features & "Magic Sauce" Ingredients:
1. 🎯 AUTOMATED & USER-FRIENDLY
Fully Automatic Scaling: Just plug in your image! The workflow intelligently analyzes and scales it to the perfect resolution (~0.23 Megapixels) for the Wan 14B model, ensuring optimal stability and quality without any manual input.
Clean, Subgraph Architecture: The complex tech is hidden away in organized, collapsible groups ("Settings", "Prompts", "Upscaler"). What you see is a simple, linear flow: Image -> Prompts -> SD Output -> HD Output. It’s powerful, but not complicated.
2. ⚡ ENHANCED MOTION ENGINE (The 14B Core)
This is the heart of the solution. We solve the slow-motion problem with a sophisticated dual-sampler system:
Dual Model Power: Uses both the Wan2.2-I2V-A14B-HighNoise and -LowNoise models in tandem.
Pusa LoRA Quality Anchor: The breakthrough! We inject Pusa V1 LoRAs (
HIGH_resized@ 1.5,LOW_resized@ 1.4) into both models. This allows us to run at an incredibly low 6 steps while preserving the sharp details, contrast, and texture of a high-step generation. No more quality loss for speed!Lightx2v Motion Catalyst: To supercharge motion at low steps, we apply the powerful lightx2v 14B LoRA at different strengths: a massive 5.6 strength on the High-Noise model to establish strong, coherent motion, and a refined 2.0 strength on the Low-Noise model to clean it up. Result: Dynamic motion without the slowness.
3. 🎨 LOW-RAM HD UPsCALING CHAIN (The 5B Power-Up)
This is where your video becomes a masterpiece. A genius 2-stage process that is shockingly light on VRAM:
Stage 1 - RealESRGAN x2: The initial video is first upscaled 2x for a solid foundation.
Stage 2 - Latent Detail Injection: This is the secret weapon. The upscaled frames are refined in the latent space by the Wan2.2-TI2V-5B model.
FastWan LoRA: We use the FastWanFullAttn LoRA to make the 5B model efficient, requiring only 6 steps at a denoise of 0.2.
WanVideoNAG Node: Critically, this stage uses the WanVideoNAG (Nested Adaptive Gradient) technique. This allows us to use a very low CFG (1.0) for natural, non-burned images while maintaining the power of your negative prompt to eliminate artifacts and guide the upscale. It’s the best of both worlds.
Result: You get the incredible detail and coherence of a 5B model pass without the typical massive VRAM cost.
4. 🍿 CINEMATIC FINISHING TOUCHES
RIFE Frame Interpolation: The final step. The upscaled video is interpolated to a silky-smooth 32 FPS, eliminating any minor stutter and delivering a professional, cinematic motion quality.
📊 Technical Summary & Requirements:
Core Tech: Advanced dual KSamplerAdvanced setup, Latent Upscaling, WanNAG, RIFE VFI.
Steps: Only 6 steps for both 14B generation and 5B upscaling.
Output: Two auto-saved videos: Initial SD (640x352@16fps) and Final HD (1280x704@32fps).
Optimization: Includes Patch Sage Attention, Torch FP16 patches, and automatic GPU RAM cleanup for maximum stability.
Required Models (GGUF Format):
14B Models:
Wan2.2-I2V-A14B-HighNoise-Q8_0.gguf&LowNoise-Q8_0.gguf5B Model:
Wan2.2-TI2V-5B-Q8_0.ggufLoRAs: Pusa (High/Low), Lightx2v 14B, FastWan 5B
Text Encoder:
umt5-xxl-encoder-Q8_0.ggufVAE:
Wan2_1_VAE_fp32.safetensorsorpig_wan2_vae_fp32-f16.ggufUpscaler:
RealESRGAN_x2plus.pth
Required Custom Nodes: VideoHelperSuite, Frame-Interpolation, KJNodes, easy-use, gguf, memory_cleanup.
🎬 How to Use (It's Simple!):
DOWNLOAD the workflow and all models (links below).
DRAG & DROP the
.jsonfile into ComfyUI.CLICK on the "Load Image" node to choose your input picture.
EDIT the prompts in the "CLIP Text Encode" nodes. The positive prompt includes detailed motion instructions – make it your own!
QUEUE PROMPT and watch the magic unfold.
That's it! The workflow handles everything else automatically.
🔗 Download Links
Place these in your ComfyUI/models/ directory in the corresponding folders.
Model / LoRA / Component
Wan2.2 14B - High NoiseWan2.2-I2V-A14B-HighNoise-Q8_0.gguf
Wan2.2 14B - Low NoiseWan2.2-I2V-A14B-LowNoise-Q8_0.gguf
Wan2.2 5B - TI2VWan2.2-TI2V-5B-Q8_0.gguf
Pusa V1 LoRA (High)Wan22_PusaV1_lora_HIGH_resized_dynamic_avg_rank_98_bf16.safetensors
Pusa V1 LoRA (Low)Wan22_PusaV1_lora_LOW_resized_dynamic_avg_rank_98_bf16.safetensors
Lightx2v 14B LoRAlightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
FastWan 5B LoRAWan2_2_5B_FastWanFullAttn_lora_rank_128_bf16.safetensors
UMT5-XXL Text Encoderumt5-xxl-encoder-Q8_0.gguf
Wan VAEWan2_1_VAE_fp32.safetensors / pig_wan2_vae_fp32-f16.gguf
RealESRGAN UpscalerRealESRGAN_x2plus.pth
RIFE Modelrife49.pth (Usually bundled with ComfyUI-Frame-Interpolation)
Required Custom Nodes:
ComfyUI-VideoHelperSuite
ComfyUI-Frame-Interpolation
ComfyUI-KJNodes
ComfyUI-easy-use
ComfyUI-gguf (or ComfyUI-GGUF-Integrated)
ComfyUI_memory_cleanup
Transform your ideas into fluid, high-definition reality. Download now and experience the future of Wan2.2 video generation!
Description
Enhanced output quality and increased stability have been achieved.
The Lora loader has been streamlined for easy use.
Additional features have been implemented, providing convenient access.
FAQ
Comments (16)
thank you bro! great work
on v3 Value not in list: upscale_method: '0.21' not in ['nearest-exact', 'bilinear', 'area', 'bicubic', 'lanczos']
can you share your upscale method 0.21?
Hello. I am not sure where to put the loras . Is it possible to have screenshots to help to know where we must put them, and know also where we can add Other LoRA ?
got prompt
Failed to validate prompt for output 141:152:120:
* LoraLoaderModelOnly 141:151:148:
- Value not in list: lora_name: 'wan_loras\Wan2_2_5B_FastWanFullAttn_lora_rank_128_bf16.safetensors' not in (list of length 47)
Output will be ignored
Failed to validate prompt for output 141:151:121:
Output will be ignored
Failed to validate prompt for output 140:
Output will be ignored
Failed to validate prompt for output 141:152:133:
Output will be ignored
Failed to validate prompt for output 141:135:
Output will be ignored
Using pytorch attention in VAE
Using pytorch attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
gguf qtypes: Q8_0 (169), F32 (73)
UPSCALER SETTINGS then MODELS/LORAS select Wan2_2_5B_FastWanFullAttn_lora_rank_128_bf16.safetensors in lora loader node.
The instructions could be better. I'm only guessing where these all go. Also, one of the files in the download links section seems to be pointing to the wrong page. Wan2.2 5B - TI2VWan2.2-TI2V-5B-Q8_0.gguf
@zardozai Thanks, I did end up finding it. But like I said, I really don't know where all these other files go. It is probably obvious to someone who is very familiar with ComfyUI but I am not. I am not able to get this to run.
wheres the T2V?
I am getting SD Output only and the jobs finished. HD output nothing, What could be the problem?
1.5 hours just to run this mess, trying to simplify with graphs actually does the opposite since, you actually have to go there and do the work.
So needlessly packed behind several layers of subgraphs that it can neither be troubleshot nor improved. Changes that could have been made in one place, need to be made in several, with no way to visualize where the problems are. Reliance on many gguf-only nodes makes the core functionality incompatible with existing pipelines.
I've spent 2 hours on this workflow. My video result always results in a garbled mess like this
{kind=link}
incredible motion, upscaler is fantastic, but this really needs sageatn, i added it myself and with triton it went from 24 min to 535 secs for a 103 frame vid. Previous version was my go to workflow for wan 2.2 and this version is even better.
I love this workflow, give amazing genrations and well built.
one questions, why use the wan2.2_5B in the upscaling process ? would any wan model give similar results ? could I use the 14B or is there something special about the 5B that is better for this task ?
Uses less vram and is sufficient for the task, plus it runs quicker than 14b.