🗡️💀 DaSiWa-WAN 2.2 I2V 14B Lightspeed | FP8 Safetensors💀🗡️
My new flagship model for WAN 2.2 I2V generation - This is the best of the best!
This is a WAN 2.2 Model: You will need one pair of High + Low.
Version overview: https://civarchive.com/articles/23495/dasiwa-model-versions-and-timeline
🔮 Key Features:
🔥 LoRA-Free Generations
Generate high-quality videos without stacking Wan 2.2 LoRAs (unless you want adding spacial styles/concepts).☄️Fast: 4 step generation
Extreme versatile (more build in concepts)
Quality motions (less slowdowns)
🔞 NSFW + SFW:
Enhanced anatomy + poses + framing
Better understanding of sexual concepts
🪄 Better Prompt Responsiveness
🥺👉👈Better understanding of anime/manga style composition
🪡 FP8/FP8+ precision
⚠️ Read "About this version" details for the version you are using for more information!
🚫 Do not use any extra speed-up (low step) LoRAs, this is baked in already
🍒Workflow
Make sure to checkout my easy to use Workflows!
🍄LoRA's
Try first without additional LoRAs!
But: This checkpoint is not meant to replace all LoRAs, it is meant to:
Perform better overall at his own
As easy as possible to use
With LoRAs to be absolutely awesome
⚠️ Read the corresponding announcements.
📢 Make sure to check it out for in-depth information and a complex comparison!
🛠️ Recommended Settings
Steps: 4
CFG: 1
Sampler/Scheduler: Euler/Simple or Euler/linear_quadratic
Resolution up to 720p (native quality).
My go to settings:
0.52 - 0.83 MP
CFG 1
Euler/linear_quadratic
4 steps
16 fps
Sigma Shift: 5
Add other LoRAs with 0.3-1
16 fps, 81 frames ~ 5s
Dependencies
🩻 Known issues
Tell me 🫵🫢
🩺 Fixes & Feedback
If you use LoRAs, try to respect the LoRA training triggers and try some versatile descriptions, most LoRAs will work with 0.3-1.2 (start with 0.3)
Do not mass add LoRAs, just add 1 or 2 (x2 High+Low)
Negative prompting do not work with cfg 1, thats a limitation of speed-ups with cfg 1
Low resolution (e.g. 480p) are only for fast samples and will blur fine details, do a higher resolution if you want clear details
Before posting any questions I suggest reading my guide.
Update your ComfyUI ❗
🪧❗ Test your comfyui-backend with this absolute basic test-workflow before asking about errors.
🖤 Why I Made This
I was tired of using all these massive list of LoRAs, just to get a remotely good result after 10 generations, consuming hours of time.
So I can just make my videos with 1 or 2 concept LoRAs without pushing 6 till 10 LoRAs (Low/High) into a generation.
This checkpoint is also my personal playground.
Closing words
🤩 I want to thank all the fantastic other creators who made super nice LoRAs and concepts to play with! Support that awesome creators by using their LoRAs and post to their gallery and share the meta-data!
⚠️ I made all this with permissions or open-source resources (the time it is incorporated).
I share as much insights as I can without compromising my work. I'm doing this for fun as my hobby and just do not want my hobby to be destroyed.
More details can be obtained in the corresponding announcements!
If you would like to contribute in my awesome (😉) checkpoint or willing to share resources I'll gladly give credit! Just contact me!
✅ All credits / resources are mentioned inside the announcements! - Since different versions may have different resources.
YOU are responsible for outputs as always! If you make ToS violating content and I get aware I WILL report this.
Disclaimer
This models are shared without warranties and with the condition that it is used in a lawful and responsible way. I do not support or take responsibility for illegal, harmful, or harassing uses. By downloading or using it, you accept that you are solely responsible for how it is used.
Custom License Addendum: Distribution Restriction
Notice: Notwithstanding the base license selected for this model, the following restrictive terms apply:
No Redistribution: You are not permitted to host, mirror, or redistribute this model (checkpoint, LoRA, or Safetensors files) on any other platform, website, or service (including but not limited to Hugging Face, Tensor.art, or SeaArt) without explicit written permission from the creator.
Attribution & Source: This model is officially maintained only on Civitai or other platforms where I explicitly own the repository. To ensure users receive the correct version, updates, and safety metadata, please point users to the original URL.
Usage: All other rights regarding the use of the model for image generation remain as per the terms and the restrictions provided per model.
Description
See HIGH description
FAQ
Comments (369)
How can I use this in Forge UI?
On Forge Neo, just add to checkpoints folder
New Features
Support Wan 2.2
txt2img, img2img, txt2vid, img2vid
use Refiner to achieve High Noise / Low Noise switching
enable Refiner in Settings/Refiner
@naomixlove And? A useless glitchy GUI
@qek Glitchy how so?
@naomixlove thanks will try it out
For Info: Latest comfy 0.3.68 (2d ago) may have bug's that effects WAN 2.2 loading and sampling. Leading to extreme long times or OOM or memory bugs. Switch to a earlier version 0.3.67.
Using comfy startoptions "--async-offload --reserve-vram 1" may resolv the problems with 0.3.68
@darksidewalker Thanks for this tip, I didn't face such issues on Comfy 3.68 & frontend 1.32.3, but maybe because I have 2 GFX cards (RTX 3090 24GB & RTX 4080 16GB) which didn't help me feel the issue enough!?, anyways I will keep using the (startup arguments you provided) in the run_nvidia_gpu.bat until further fix or clarifications.
@hazzoom82659 The frontend doesn't matter
Please share base image plus prompt and exact settings. My generations don't look nearly as good as your examples. I don't know if I'm prompting wrong or what.
All sample images include the WF I used with all settings and prompting.
Wan2_1_VAE_bf16.safetensors cannot run :ERROR: VAE is invalid: None If the VAE is from a checkpoint loader node your checkpoint does not contain a valid VAE.
but wan_2.1_vae.safeXXXX can run.
Old GPU that can not run bf16…?
@darksidewalker wan_2.1_vae.safetensors is bf16 too, check Comfy's repo
I assume he did not downloaded the VAE at all
@darksidewalker There is
@qek what do you mean? I do not understand 😄
@darksidewalker They have the VAE, they say
Amazing model. Thank you so much.
I wish there was a version for Wan 2.2 Fun Control also. 👍👍
Thanks anyway.
Thank you! But I don't think there will be a Fun Control. The model is just to niche.
Could you provide a list of the Loras you have merged? That would prevent us from inadvertently using the same ones. Also a T2V version would be very welcome, for use in I2V with VACE, for example. Thank you!
I may not provide a exact list, but I mentioned all possible resources on my announcement. 👍
T2V and VACE won't happen any time soon. Sorry.
Plus I tested with a huge amount of LoRAs, you can freely mix as on my elaboration.
Do you have a prompt formula or have you adapted it from a particular model that I can copy as a reference?
I just write what I think should happen
Or you could read my guide for reference. WAN understands natural language.
This is honestly a pretty powerful model. Literally just write what you think it should do, and most of the time it will interpret it without any problems.
NGL, this is my favorite checkpoint right now by a landslide
Glad you like it, too!
I feel like an idiot buying LureNoir and now I to buy more buzz... Well you definitely know how to make money, cuz I don't think I can wait 8 days for this.
You are not! LureNoir is also fantastic, the new one is just better, I really just tried to hear the feedback and make something even better. I do this as hobby, the buzz and ko-fi tips all are for making that stuff. I'm not gaining money from this directly anyhow. I'm thankful if someone supports me and can have fun with my stuff. Do as you can and like, no forcing 😊
@darksidewalker Lurenoir is fantastic, also your workflow is my new favorite for making all my generations and therefore you are my fav person now on civitai. But I'm struggling here. I would much rather pay for a monthly patreon than buzz with all these transaction fees. Regardless, thank you for pioneering the best w22 models.
@glogtorbinson5284 I see what you mean and the fees would also for me 50% cut. I was also thinking about providing the model on a other way for ppl who tip a ko-fi, but I didn't found a way to do it. The files are large.
@darksidewalker Appreciate you trying. How often do you work on new models?
@glogtorbinson5284 Not that often. It is really time consuming. I just work on it, when I feel there are enough tech to bring a big heap. Small upgrades are not my thing. also I do not want to overwhelm with minor or useless things, that's why I also maintain a illustrious for free atm.
That was also the point of the first 3 totally free, they where ok/good, but not really awesome.
The last one was born because I was not just totally satisfied with everything and there where major upgrades possible, after getting enough feedback.
I have to look that I do also not just burn my money. Civitai would cut 50% buzz, membership would charge >80USD with fees if I would not made it for non-profit atm and computing resources are pricey.
They buzz I earn are all for training/buzzing other creators or such things totally tied to the onsite.
The only way I would get a minor compensation would be ko-fi tips.
@darksidewalker man people like you are so underappreciated on here, you aren't the first one I talked to that is working their ass off on this stuff. I guess we can just hope Civitai's incentives for the top creators can just get better in the future.
@glogtorbinson5284 Kind words! This is also my hobby and I'm also happy if my hobby can inspire or help others to create awesome art. I love that AI stuff and I think it is so great to see all these ppl working on art like that, never possible without AI, creators and so on. I, myself, would never be able to draw a real image like that or make a video scene to scene from scratch... ^^ I love being able to do all that stuff and maybe help others to do it as well :)
Considering your update speed. Please lower the price so that more people can purchase your model. If you set a reasonable price, I believe you can not only make more buzz than now, but also gain more feedback.
Yeah 👍 I lowered already, from 1 to 2 weeks and the next is not planned for anytime soon.
I'll wait now till some significant upgrades are possible. That could be a while 😄
Considering other creators update speeds some times just days to 1 week and my first 3 checkpoints where completely free. I think this was ok. But my time also got more limited, so I'm maybe will definitely not going fast on this. I just feeled to release a fully overhaul. I also wanted to make sure to document more sources and release in complete consens with them. So this is like a 3.0 when the old ones are 1.0 and LureNoir 2.0.
@darksidewalker Great, looking forward to your further upgrade, your models are stunning
Excited to use just a quick question will te outcome be more creative compared to your other models?
I'm constantly running into the same animation sequence even with different seeds.
My question is regarding this:
💠 Zero prompt results capable
This tells me it might get a little more creative on motions?
Maybe just a WAN thing... trying so hard on different results for weeks now :')
Hi! 👋 I did not right get your intention.
For me it is doing what I prompt for, if you want different results you need to prompt for it or alter the outcome with a specialized Lora.
If you do not prompt anything it can be very creative on its own, but that is totally tied to the init image and what the model think could happen there.
I have posted a sample without any prompt with a girl on a rainy day dancing. Looks very dynamic from my point of view 😄
@darksidewalker thank you for the reply!
Sorry for the confusing comment I made, currently I'm using your radiant model since this one listens the best to my prompts in my tests, this one has been very good so far and I love it.
What I mean by creativity is, when I tell for example "Girl is jumping" it always shows the same exact jump no matter the prompt, I actually want something more diverse so when I run it for example 8 times I can pick the best one.
But this might be more a issue with WAN, I tried Grok Imagine as well there the animations are more diverse but I can't run it locally so its not a great alternative. Same with camera movement, it somehow never zooms in out away or w/e I even tried the official prompts from the WAN 2.1 documentations.
I tried with and without recommended Lora's, results are good overal, just not much variety. I saw you have a workflow too, I'll try that one too later, thanks!
If you get mat1 and mat2 shapes error, try that encoder 'https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors', Wan 2.1 VAE and start with 720x720 resolution.
is this for the tired of setting person using?
I can not understand that.😑
I`m meaning this is the most convenient model for lazy guys that we can use it without lots of loras
@yazi6393wy136 yes, this model has loras within it, so there's no need to pile on extra loras. The other great model is the smoothmix one. Both amazing in their own ways.
I Just bought this... do i no longer need the 4 step light loras with this checkpoint?
can anyone share the time by author`s workflow, parameter is 97 length 512*768 in 4090? I need 95s one round and about 66.6s in Wan moe ksampler node, I don`t know is it normal in 4090.
Valid WAN 2.2 frames are 16*n+1 or 24*n+2, e.g. 16*5+1=81 for 5 seconds.
95s would be 1521 frames ... I don't think a normal GPU can do that and wan does not support such length.
I didn't explain it enough. When I make a 5s(97 frame length) video, I need 95 s to generate it, I don`t know is it a normal generation time in 4090
@yazi6393wy136 seems legit. It is fast. With standard wan 2.2 you would need 4-5* amount of time.
It seems like you may not have enough system RAM for a faster generation. I use ~80gb of 128gb total RAM and all of my 4090's VRAM. My generation times at your given settings (97 frames, CFG=1, 512x768, 4 steps) are ~30 seconds per KSampler node and 120 seconds in total.
@AlphaDelta You mean your total is 30s in one Wan Sampler?I have only have 48 GB ram and I wonder the cpu affect the speed? I`m using 5700x
I love your model!
Is there history of changes somewhere? I want to know if there is use case for older versions
In "About this version" and my announcements. There is not really a point in using the older models, except you have a specific/niche use case where they perform much better.
😁 Thank you so much for making these powerful and easy-to-use models & frameworks, I have tried a few before but this one just takes the crown when it comes to i2v and consistency. I really appreciate all your hard work putting into this and am currently waiting for MidnightFlirt to be released :)
I saw that there are some "v2v video extension" workflows out there and was wondering if there are plans to add something similar. I can currently use the last frame to generate another 5-second video, but I am thinking of something more automatic or smoother in the transition between the two videos. I saw that there is a "video combine" feature in your framework, but I am not sure if this is relevant
Again, thank you so much! 😁
A full automatic video chaining would have the problem that you do not have influence on each segment. So I did not made that in my workflow.
If you are searching a v2v checkpoint you would have to look into WAN-Animate.
@darksidewalker Thanks, so what's approach do you recommend? The traditional use the last-frame to generate another video and combine it? Or is there anything else? Thanks!
@eptgames the traditional way, going to use the last frame as next initial image.
I’m currently running into a very similar issue. It’s definitely not the checkpoint’s fault—the checkpoint itself works amazingly well. However, when I try generating multiple clips using the “start–end frame” method and then combine them, the character’s motion becomes discontinuous, even when I use the same seed.
I’m wondering if anyone has suggestions on how to handle this kind of problem. I’m also curious whether v2v or any other workflow could help maintain consistent motion across clips. Thanks in advance!
Hi, I saw you wrote "umt5_xxl_fp8_e4m3fn_scaled" in the description above. But the link you provided doesn't have the "_scaled" in its title. So which one is it and can you also provide a new link? Thank you so much!!
It's ok
@qek I tried it out, turned out, it got the "mat1 and mat2" error, even though I set the resolution to follow the notes in the framework (560x720).
But this one provided on Wan 2.2 ComfyUI docs is working normally: https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
Not sure what the issue is since I'm new into this, but I hope this maybe helps someone.
@eptgames I'll try to download again maybe the source changed, I use the from the beginning
I updated all dependency links, download them and used them. They are all functional.
If this is not working on your side you should consider reinstall a fresh comfyui.
error in ksampler,
WanMoeKSamplerAdvanced
Given groups=1, weight of size [5120, 36, 1, 2, 2], expected input[1, 32, 21, 96, 66] to have 36 channels, but got 32 channels instead
Use the correct VAE and CLIP.
@darksidewalker The vae and clip are the ones from the download provided in the description.
@BreakBrack You ether did not use them or your backend is broken. This error always occurs if you did not use them like a wan 2.2 VAE.a
@darksidewalker @darksidewalker I managed to get it working regarding the files, however the videos are coming out "burned." And if I try to use the workflow that was provided with this template, it gives an error in ksampler.
@BreakBrack I can not imagine what is going wrong on your side. This is not a problem with the checkpoint/model. Something is wrong with your installation.
I would suggest to make a fresh comyui install and download the correct VAE and CLIP.
There are no complicate dependencies.
Maybe drivers, your python or torch version, I can not know that.
@darksidewalker the vae has to be 2.2 or 2.1 from wan
@darksidewalker the vae has to be 2.2 or 2.1 from wan, i'm using 2.1of vae
@BreakBrack 2.1 VAE, 2.2 ist only for the 5B model,... It's really confusing why they made it that way.
@darksidewalker So I'll keep the vae 2.1?
@BreakBrack yes
@darksidewalker I'll try that. I'll be back with updates, but thank you for your support. I really loved the model and wanted to use it.
@BreakBrack How did you fixed it? I have the same issue
I fixed this issue updating my ComfyUI, it was 4 months old and also the WAN Nodes, but of course I did a backup first for any case.
Experiencing the typical wan 2.2 slowdown when doing a 81 i2v then looping back around -1 frame and generating more video, i know you have the lightning lora's built in but the seko 4step loras helped on other models, maybe its just my workflow.
There are 2 flaws with that -1 frame does not work for video chaining, this is a simple method for loops. But not a really good one.
The seko had massive slowdowns, this one is not used here.
@darksidewalker yeah, im still pretty new to really learning all this stuff.
im using your workflow and manually doing the i2v then using first frame last to generate things, and extracting frames from the model to create what i want. im just used to the auto process which - is just flawed at this point.
i have noticed that say i create my i2v with your workflow, then make the first frame the last frame from that - its almost as if it doesnt listen to new prompts/loras. is that metadata causing that? i even tried some loras at 1.5 h/l and specific prompting and it would just ignore it.
appreciate your time
@bloodthinner666649 I did not extensively tested chaining videos with changing loras. It is always very hard to say what impact a lora could have.
There are so many factors to consider.
I fear I can not help much here atm, but I'll have a look in the future.
@darksidewalker yeah no worries
it just seems sometimes it just does not adhere to any lora or prompt and it flat out sometimes ignores it, but it works well at getting frames to pull from to use for other things!
one question, when i use loras with this model it seems to ignore the loras and output looks the same (for nsfw stuff). is there something to tweak to make loras work? they were very consistent with 14b gguf version dasiwa shared.
You may have to try different strength. On my experiments it works very well with loras.
This is a heavily tweaked model, the loras are trained on base WAN 2.2, so you might need other strength as for the basic one. I would suggest starting at 0.4 and maybe going up till 1.2 depending on the lora and that effect.
What would be the ideal configuration for an RTX 3060 12G?
It is not that simple. Depends on your whole system, OS and backend. You have to try.
@darksidewalker I managed to do it; your workflow worked perfectly as soon as it finished downloading the files.
@Sr_RockwellyDesu Hi, how long did it take you to generate 5s videos? I plan to get one on a 3060 too, so I'm wondering about your export time and the resolution you chose too. Thanks!
If you can don't go for a 30xx series. They are not able to do fp8 native. That will gimp your speed and will not good for any other AI fp8 scaled checkpoint.
https://civitai.com/articles/20293/darksidewalkers-wan-22-14b-i2v-usage-guide-definitive-edition
@darksidewalker Thanks for the advice. I saw in your post that the 40 and 50 series can do FP8. My budget is a bit tight to get a 40 with 16GB VRAM, so my choice is between the 3060 12GB and the 4060 8GB. Which one do you recommend? Thank you.
@eptgames A 30xx can do fp8 but not native, what will be slower. If you have to choose more VRAM is always better. 8 GB is just too low for most AI stuff today.
But recommendations are tough, because nobody knows what AI checkpoint will release next time and what operations and math that will need.
I really would not recommend both ether. I would wait for the next release of next year and see if nvida or amd will put more VRAM into the cards ...^^
That said if you want something now, 12 GB VRAM could be better to run some AI at least.
@darksidewalker Thanks for the recommendation! That makes sense with the year wrapping up. I’m still on my old 1070, and it takes me about 45-60 minutes to render a 560x720 5-second video, haha. I’ll likely hold off until next year to check out the new cards, and in the meantime, I’ll save up a bit more for them.
@eptgames 45min with my checkpoint? Or with basic WAN 2.2? That seems really slow.
@darksidewalker Yeah, with your LureNoir checkpoint and your workflow too. Which is actually better than other ones I have tried, I like them a lot. But it seems my hardware is quite old to be fast now. haha
Hi I use 3060 12G with launch options --use-sage-attention --lowvram --reserve-vram 1.0, I also have a ssd setup to be a swapfile, i use native nodes workflow with Q4 gguf no problems in around 480 seconds, Q8 takes a bit longer due to more swapping but its doable. You only ever want to generate 81 frames max which is 5 seconds, because the base model was only ever trained on 5 second clips. And so going over 81 frames just causes it to start looping back.
I resize and pad start images to 720 x 720, its a good balance I find, its not as good as using the full model and resolution but its fine for my needs.
Someone created gguf's of midnightflirt and put them up on hugging face.
@rogerstone442 these quants on HF are trash because they are based of fp8 and degrade the quality, just saying. I have made my own quants with a correct (my fp16 base). They are EA, at the moment for supporting. But you can wait until they are free of course.
@darksidewalker Oh I get it now, well they are still kind of ok lol, i won't bother downloading the Q8 then of that version on huggingface, I'm uk don't tell anyone i use vpn so its not like i could use buzz that easy. But I will figure something out a bit later, I will tip you because this is the best model I've used so far.
Edit I might just try through vpn and unlock it for all if I can work around it I will. Ah I see its a simple 3k buzz no unlock for all, no worries I'll get that sorted for myself then.
I don't think this version name makes any sense. You cannot derive crucial version-related information from it, such as which version is the newest, or the degree of difference between two versions. Furthermore, I spent time trying to understand its meaning, only to conclude that it is completely nonsensical.
Oh boy! You are serious?
My version naming consists of neologisms. Because I do not like v1,2,3,...
They are not numbers for me, they include a feeling for me, they shall express the moments I want to catch while having fun with them. They are passion for me!
You can like it or not. - That's my way to do it.
The critical infos are all there in "About this version" and on my announcements. All easily accessible on the front-page of the model. If you are able to read, you can extract all the infos necessary.
And if you can remotely understand how all the checkpoints are sorted, on >all< other pages, the newest is always the first left one ...
So what is the problem and the >sense< of your post here?
@darksidewalker Yes, I understand what you explaining, the rationale behind using this system and how to recover the information that is lost, but this does NOT change the fundamental truth: your current version naming provides NONE of the crucial data that a version name should contain.
@kisoubourei501 version numbers never inherit crucial data or changelogs ... there is no lost information in not using a version number if timeline and order is correct.
@darksidewalker And this version name even not contains order info.
@darksidewalker I cannot read how you can see all version name in the world nerver inherit curcial data... So you mean python2 == python3, version dificaiton like 3.xx or 2.xx is just no use at all?
I can nerver imagine what in the world will happen if python, or any remarkable project, use a version naming like this...
@kisoubourei501 there are plenty projects that do not inherit numbering.
We are talking about versions of checkpoints, not critical software or programming languages.
Therefore the version numbering here is never filled with critical data. You compare different things here.
Are you not understanding that the release date and timeline order is given and correct with or without using a number as version?
I'll not change it for you, regardless what you think about that, this is not a crucial system component or operating system critical software where release hashes, multi-versioning and inherit dependencies must match other critical components.
It's clear what is newer with order, release date and "About this version" box. Even an emote displays that.
@darksidewalker I like the names kinda cute. I know Android used the dessert naming scheme (in alphabetical order e.g. CupCake Donut Eclair Froyo) making theme easy to remember(and I think MacOS did names of big cats but not alphabetically), it still had version numbering though. This is really a non-issue for me, you're not really targeting specific devices, the latest is the latest.
I'm trying to make clouds in the sky have movement like wafting or any other term, or trees move in the wind.
I had some experiences with plants having wind movement but clouds always stay static for some reason. Am I doing something wrong or is it just not possible?
Here's a example of my complete prompt:
Girl in heavenly scene, fox girl in the sky on a mountain tip.
Girl looking around, her tails waving and swirling motion, tails wave, tails swing, tails swirl, tails swirl in circular rotating motion.
Radial light in the background slowly rotates and shimmers.
Moving clouds and smoke, moving mist, wind in girls hair, swirling clouds, drifting clouds in the sky, never ending smoke wafting at the bottom of the scene, brownian cloud movement in the background, wafting clouds in the background sky, clouds drifting in the skies, clouds drift.
Small shimmering particles in the background fly by.
It does everything except the cloud movement.
I did not really have an answer to that, but I think this is a limitation of WAN AI itself.
I think it matters how prominent these clouds are visible for the model or if it even can see them at all.
I have no experience with clouds. But background, if only a bit blurry, is almost not recognised by WAN at all.
try rephrasing that cloud prompt into actual sentence. the new Wan takes offense if you speak to it like to a machine. also some long 'detailed' prompts would get ignored, so try shorter
FLF2V could help
@qek sorry what is FLF2V?
Thank you all for your replies I'll try longer praises and keep it shorter and give it another few goes
@Setian91 I did some testing, all arbitrary objects in the far background - like clouds - will not consistently be recognised by WAN 2.2, no matter the checkpoint. So do not count on that.
@darksidewalker thanks for the clarification,
I did some more testing and 1 out of 50 attempts had some smoke or cloud movement, so I guess luck would be out best guest haha
Maybe there some creative way in prompting, if I find one I will leave it here!
@Setian91 try describing the scene at the very beginning where you include the clouds (or w/e the model doesn't see/recognize) in the description of the character/subject or when you describe other movement (old house with clouds above it) then use that exact wording later to describe what the clouds in this case, suppose to do. it helps me get some very specific things in, that i'm actually surprised this thing picks up on.
@1tulut7 I'll have another go at it, still haven't been lucky w/e model or Lora I use
But this worked for you?
damn. i posted a few weeks ago when trying the previous version (lurenoir) about issues with color changing mid video, but this midnight version is perfect and seamless. i do wonder if you would be able to disclose what loras have been baked in so i dont have to extensively test what is needed? also would you mind explaining how the prompting responsiveness works? how are the baked in loras triggered without using their prompts? also what do you mean by flirty :D
I explained as much as I can inside my announcement https://civitai.com/articles/22233/upcoming-release-of-dasiwa-wan-22-i2v-midnightflirt
The prompting responsiveness is a product of multiple tech's compiled into the checkpoint with tuned parameters and some python scripts.
You could trigger and amplify the used loras with her corresponding triggers, but because of the creation process the checkpoint understands the overall setting much better and can use the finetunes to some extend without all that.
Here comes some magic, if you use a lora, even one which was used, you can let them really shine! the checkpoint is not meant to make loras useless. It is meant to be easy of use and universal better, even with loras.
So feel free to just experiment! 🧪
Flirty means .. you know ... she will flirt with you! At midnight! ... Don't call me out if she bites you! 😺
I feel like a total noob. i downloaded you workflow and all the files. everything works, but the videos come out very blurry. i use no loras so im not sure what is causing this.
I have those problems too with some models. You can try to check/select/reselect every setting, or try using a lora (some work for me, but most dont xD). And you can try my Workflow, which I modded from the Smooth Original. Just DL one of my latest Videos and drop it in Comfy.
BTW: What you describe is typically for the wrong Sampler and Schedular selection in the KSampler :)
If you did not change the sampler,you may increase the resolution, the resolution I initially set is low for fast tries. Do you have an example what blurry to you mean?
Is there a way to force actor to gag a whole "sausage" without additional lora's by only prompting?
And also how to undress? before funn act, "Take off" is not working correctly for me at least
Ist there any reason you don't want to use a Lora for something?
It can do that, but depends. Undressing is more difficult to achieve, because you have to experiment with promoting.
@darksidewalker A few, for some reason i got errors when i try to change lora weight from 1, since wan is multilanguage model so i prefer to prompting on my native language, and its doesn't work with most loras
really enjoying these checkpoints! MidnightFlirt is prone to adding red devil eyes without invitation. Theyre pretty, but it makes multi-part continuous videos slightly more cumbersome. Lovely results otherwise!
Red devil 👀? Never notices anything like that, do you try to use it as T2V?
@darksidewalker It can happen when the start image has eyes closed and no mention of eye color in prompting. It follows prompting well though and I usually start with open eyes so it's really a non-issue that I found funny :P
Amazing work! I really like your checkpoints! They are much better than the original native one.
I use them for various use cases, for example, I use Radiantcrush for handling less dynamic requirements (And it reacts better with my own trained LORA).
And for NSFW movements, Lurenoir does a perfect job!
Looking forward for your new model!
This is amazing work!~ I get really great results with your models, is there any chance of a GGUF version?
No chance. You can read up on this on my announcement.
@darksidewalker No worries, I didn't see your announcement on this model page, or on your profile, is it elsewhere?
I sadly can't use your model often as it takes a really long time to render vs gguf models. (Running on RTX 4070 12GB Card) your models are a bit to large for my system to be viable.
Is is on my page under "articles" :) You can try my WF this shouldn't be slower as a gguf at all. On my testing it is in fact ~38% faster as gguf q8. With my 4070.
@LindezaBlue Look for unofficial quants
@LindezaBlue really? I never hit 8GB mark on VRAM, is it Comfy-specific issue? I'm running this model fine with Wan2GP, average 190s for 540p 5s 4steps video.
@Styl1sh more than likely a comfyUI related issue, I tried Wan2GP but was limited with quality. I get better results with comfy otherwise I would of stuck with Wan2GP.
fp8 isnt usable on a mac, any chance we can have a fp16 version we can use or GGUF version for us?
thank you very much for your efforts. I wonder, in your video generations, they look very nice. Do you use more steps to achieve that quality? Do you also use like the ultimate sd upscaler to upscale each frame? I'm curious, thanks again!
Hi! I use my Illustrious checkpoint to make my images and my comfyui workflow to generate the videos. The upscaling is done with nodes from whiterabbit. No UltimateSD Upscaler used.
@darksidewalker Thank you, are those in your workflow?
@FlowSpecialist Yes, I use the workflow from me as is. I use the AiO version atm.
@darksidewalker thank you!
I'm following you now since some iterations of this Lora checkpoint(!), to be outright honest. Aand it just strikes me, how you're constantly making progress while rly caring for most important details as in face consistency, which WAN fights with still in 2.2. You also sharing the according workflow means you present an awesome synergic package... thank you for that, Mr.!
I love that it's totally realiable for SFW content too! ❤️
I rly hope to be able to accordingly return the generousity you're presenting here. :)
Hi! Thank you for that kind words. But this is not a LoRA, it is a full checkpoint, don't be confused :)
I hope you have much fun with this tools!
@darksidewalker Gosh, I was fiddling with Loras lately so much, I totally got it mixed up right now, sorry! And yes, I've tried the utterly complex Kijai workflow for longer videos before, but it's a monster to tame plus the approach on the loops there are rough.
Then I found your smooth looping workflow and alongside it tried the checkpoint and it's been amazingly good working on first approach, so you've got a hand for those thingies, Sir. Thank you for investing so much time, effort into creation and ofc documentation !
@Lyara Thank you so much!
That was exactly my motivation. I was so tired of stacking 10-20 loras, fiddling with huge complex workflows burning my time with no good result.
Sometimes I mess things up and produce some bugs hrhrhr ... but I hope everyone can have fun with these tools instead of wasting time. Tools are there to bring joy, not to be more work...
In the end I did invest a big load of time into this, but I got rewards in form of awesome art, nice chats and the feeling to create something awesome with everyone involved, at least for me it was not like work :)
I also felt the need for documentation and a guide, because there is so much false knowledge around and misunderstanding. Even this guide was growing and growing ... 😄
And thank you for your support!
@darksidewalker
Gods, yes totally: Lora-stacking to produce something good plus having the lucky seed to not see the loras acting up against one another! I mean yes, when I started with I2V thingies, I went right away with WAN2.2, because I found 2.1 still a bit experimental for the mere purpose, but ofc the time I went in, it was kinda pioneers territory still for all and there only were a few approaches and specific branchings within the loras, barely a full-house-checkpoint curageously trying to host basic stuff best-possible! That was why I found your approach a great (to me first) AIO - all in one - setup that was barely too good to be true in my experience, haha.
I was even trying to take part in your follower-milestone event, but I've only seen it announced on the last day of the event and I was still testing things, so hopefully I can make it at the 5k mark then !
And no reason to thank little me here, it's the minimum to return. ❤️ Thank you so much for taking some time for the li'l exchange here!
Hope you do take your time and breaks to not spiral out of orbit with releasing awesome stuff in comparably short time! You've got amazing ideas and the skill to not only forge tools to bring them to life but also the attitude to share them, which takes not only courage to do so, nowadays!
Looking forward to our next posting-match! And until theen I do have a date with a recently found Midnightflirt, heeheeh! 😇 Feel like being hugged to the ground, Mr.! Readya soonish! ❤️
@Lyara Really nice chat! The next bounty will come! I'm just not ready yet XD
So have fun flirting! If you like post something to the gallery, every art and idea is always welcome :)
@darksidewalker
Thank you very much, I've had quite some in a selection and didn't dare to upload yet... perfectionism.. you know? 😅 But I will add something worthy in time for sure, thank you!!
Oh wow! Doing some testing and this is super fast...and sexy! Will try some proper generation today!
Don't forget to post some awesome art!
Just did a quick one. Will render a set overnight as well!
@ogbj Don't burn yourself she will be flirty at midnight!~
Would there be any chance of getting an unquantized FP16? I'm running on Apple silicon and sadly the QFP8 has compatibility issues there.
:(
No offence, but doing AI on Apple silicon is like running a car with only 1 wheel. I will not bother to support this mess. You can read up on this on comfyui GPU comparisons or my guide.
@darksidewalker ok ... I just asked. And posts beginning with *No offence" continue with an offence 99% of the time.
@lamohag405 you are feeling offended because apple silicone is trash for AI and apple is not supporting open source development? That's not my fault, but supporting this is not a thing I would burn my free time for.
The GPU comparison is just facts, too.
The thing with that car was just to make the situation clear, not to make you feel bad.
@darksidewalker There is a difference between me feeling offended and a sentence being an offense. You are hallucinating me into me being some apple fanboy that just doesn't nlow better. I do know your arguments - they are all right. I still have an apple silicon machine that I have since 2021 for reasons that do not have anything to do with SD. But I am glad that I can use it for my hobby. I don't give a damn about who builds my next machine but I hope expect that in 2 yrs from now somebody (highly pbly chinese) built a cheap small cube that I can shove under my bed and that beats the crap out of anything we have today.
But currently I kindly am putting to use what I have.
@lamohag405 Nah. I didn't think of you been a fanboy. I'm just not a fan of apples attitude and compatibility, not saying it is yours. But I can not sacrifice my time for something that even the company does not really support and work around that.
There are some reasons I do not made a gguf and a fp16 would not run on any consumer hardware, not to speak of apples hardware.
I know you have that thing and must work with what you have, I just do not want to make the illusion that this will happen or any other AI tool will be good for this.
I'm not completely against gguf or fp16, it just makes no sense for me now to invest time in that.
@darksidewalker absolutely valid points - you have to prioritize and I totally understand that you do that towards what is the norm of what people run.
I am on the odd ball here and can't in any way expect ppl (aside from the apple bubble which does include some pretty good guys indeed) to give any time whatsoever to that architecture - completely valid. But one little upside I do have - I can run a 40GB F16 jibMixQWEN on my ancient M1 max without any problems ... yes - it's slow af (45 min for 25steps at 1492x1920) ... but the results are very good to me and as a hobbyist I can deal with the wait.
But I am aware that this is lightyears away from your interests and what other ppl will do or can do on their hardware.
But thx for the chat. I didn't want to be annoying. :)
Can I use Checkpoint on a 3060 12 VRam?
works perfect in lower res (69frames, 480x848, 16fps) but i'm just doing quick tests. i haven't tried to test the limits.
Just for reference,4070s 12G,896*640,16fps 81frames,BlockSwap 30,cost about 270s
safely did 1024x1024, 69 frames, 16fps. but it took 23 minutes T_T
@civitaisucks777 Yeah because that’s not a valid resolution and will eat all your VRAM + add paging.
@civitaisucks777 It because you have run out of your VRAM,and the Comfyui use your RAM instead,RAM is much much slower than VRAM,then if your RAM is not enough too,it use virtual memory instead,virtual memory is using your SSD or HD which is much slower than RAM,so you can imagine how slow the whole process would be since you may used a memory more than ten times slower than VRAM . So you need BlockSwap to keep it run on VRAM throughout。
@ql_weepingwind036 regarding blockswap:
Here are something related to blockwswap from comfyui itself:
```
If you write a node that is so useless that it breaks ComfyUI it will be featured in this exclusive list
"native" block swap nodes are placebo at best and break the ComfyUI memory management system.
They are also considered harmful because instead of users reporting issues with the built in
memory management they install these stupid nodes and complain even harder. Now it completely
breaks with some of the new ComfyUI memory optimizations so I have made the decision to NOP it
out of all workflows.
```
@darksidewalker V0.3.71? Havent update....I‘m still using 0.3.68 .If comfyui has a new memory management technology to avoid OOM,then the problem @civitaisucks777 encountered may solved by updating comfyui to newest version?
@ql_weepingwind036 I can not tell atm, I used 0.3.70, I may test the new version on tomorrow.
@darksidewalker i wanted to test how far i can push my 3060 with this checkpoint since the image was originally 1024x1024. Is it better to downsize for gen then reupscale even after you've found a good prompt/seed?
i know the low vram (12gb) is going to heavily effect my times at higher res, but i was curious how far it can be pushed cuz this checkpoint is so good these videos are coming out amazing!
what are recommended 1:1 resolutions? cuz i have quite a few of them to gen still
@civitaisucks777 The input image matters but not as much as the video resolution you choose.
WAN can do multiple aspects and resolution as long as they fit in a divisible by 16 and are around or lower as the total pixel count of 960*960, it also can do a standard other resolution but not as optimal.
What I do, with my workflow is, scaling the image on a reasonable input size compatible with the WAN resolution and render the video in a lower resolution and than upscale the images of the video to a higher resolution before assembling.
It can also youse all standard resolutions up to 720p, but if they are not divisible by 16 it will degrade quality a little bit.
This is the most absolutely ridiculously perfect model I ever used. The I2V capability of this model is out of the world in maintain true likeness. Thank you very much for your hard work in bringing this to life!
Thank you for this kind words! Glad you like it! Now go, make some art 😄
Is there a way to make the (anime) subject not talk?
Better prompting or negative prompting.
You baked in the Lightning LoRA which requires CFG of 1.0, meaning negative prompt doesn't work, no? Or do you mean NAG?
Even copying the prompts from the your examples, my subject's mouth still keep opening and closing T-T
@HaomingGaming Yes it needs GFG 1 normally. My workflow supports NAG and it works quite well. Also if your prompt is better it does not start to talk at all even without NAG.
My samples where all made without NAG, and none is talking.
try to avoid the prompt (mouth) or (lip)
this is incredible!
before i glaze too hard tho, i did have issue with movements being way too fast and bouncy in at least 10% of the gens. any way to fix that?
i ran 300 promptless i2v with this checkpoint on a 3060 12gb and the results were amazing! the nsfw bias is real and the scene comprehension blew me away. a few dozen of the 300 were perfect videos with zero prompting. mind blowing.
Wow thank you!
Movement is also tied to FPS and frame count, so if you want slow things down do less fps and/or more frames.
Also prompting for slower motions works fine "slightly...", "slowly..."
from early tests, MF makes the characters twitch and jerk compared to LN with same prompt. I'll have to do more tests, but LN feels better for me so far
@Styl1sh Maybe you using that PainterI2V sampler? - This did many motions too strong with twitching to me. MF is normally much more stable to hallucinations compared to LN.
@darksidewalker I stick with UniPC sampler, tried Euler with no apparent difference too. character prompted to be "sleeping, breathing calmly" (paraphrased) is gyrating her hips or bouncing up and down as if during sex with MF, but behaving as expected with LN. I'm not sure what PainterI2V sampler is, no such option in Wan2GP.
@Styl1sh PainterI2V is a custom nodes used to replace WanITV nodes which is in front of KSampler
I can not reproduce this. I did some fast samples like this: https://civitai.com/images/111026761
All is fine (no negative prompt, just image and super short positive), no absurd movement. Must be your settings somehow.
@darksidewalker damn civit and their video posts, I'll have to wait a few days to see it (just 404's).
it could absolutely be something wan2gp related, it's just odd that LN behaves fine with same params. oh well! at least I have something to fall back to.
and don't get me wrong, I love your checkpoints! easily the best one for my needs, I'll be flooding your galleries for the foreseeable future (I have tons of clips in the upload queue)
@Styl1sh Do not get me wrong, I'm not mad, just elaborating things here. Maybe you have to wait 15min till they analysed the video. I for my part have no unusual movements, not all prompting is always recognised, but that is just WAN XD
I've tried experimenting with the DaSiWa WAN 2.2 I2V 14B Lightspeed workflow and checkpoint for a while. The motion seems to be working, but all of the videos are bright, distorted, and full of artifacting. I'm not exactly sure what I am doing wrong.
Initial Image resolution: 512x512
Steps: 4
Steps to Swap: 2
Start Resolution: 528x768
FPS:16
Did you try to update your comfyui?
You can try my backend test workflow, if that fails your comfy is broken.
I was able to figure it out. I accidentally set the high checkpoint on both the high and low nodes. Once I fixed that, everything started working!
Great work!Compared with other popular models in anime ITV works,this modle do the least changes to the source image‘s art style when you let character do some complex movements.
Thank you! This was tunes especially for that!
@darksidewalker Although sometimes the dynamism of action is still a bit not enough compar to other,but adding LORA or use more detailed prompt can solve the problem in most case.I plan to test a new nodes used for enhance dynamism with this modle too. Anyway,this is a great modle,thanks for all your work and look forward to the next version~
@darksidewalker In addition,after some SFW test,I test some NSFW sence,I found it doesn't work well when you enter prompt such as“take off all of her cloth”,seems like the model can't get the concept of clothing completely,some part of the cloth ofen remain unchanged,such as collar which surrounded by fabric that has near color of skin,parts of cloth behind the character and others,Although other models sometimes has the same problem with collars and other adornment on body,but seems only this modle ofen treats the clothes on back as part of body(maybe tail?)or adornment on head
@ql_weepingwind036 WAN 2.2 is not a vision and reasoning LLM, at this time this is just not possible. What you describe is just luck. You will need detailed prompting for results there.
This model is not biased for tails or such things, so that is no factor.
WAN just can not understand what "all clothes" (mind spelling) means. Also it can not imagine what parts that are. - So pure luck it even gets most of it.
@darksidewalker Although WAN 2.2 is not a vision and reasoning LLM,but ITV model do has to understand what is in uploaded image,otherwise it cannot decide which object is already exists need change from initial state,which object is not exists need to generated from zero.
After check some problem video,I think part of cloth behind char’s body which is not considered as a whole object with other part is because it is be considered as a hair accessory,since the uploaded image can‘t show clearly if the char‘s hair long enough to her back,and prompt neither. So,did this model’s training data contain more anime videos whose character have long hair with accessory than other models.....I guess......?
Anyway,detailed prompt can solve most problem,maybe I should use QWEN3 VL as a support when I‘m lazy to optimizing prompts。
@ql_weepingwind036 You are not wrong, but WAN 2.2 does not have vision. It just understands shapes on which it is trained inside a context it will guess. It compares an given image to situation it can reproduce with its tensors. That's not like real vision. That's why it can "see" a long meetly staff from the "correct" position, but not when it is elsewhere in the image, if not trained for that position. - Hope that makes sense ^.^
It is not exactly trained on long haired anime characters. It is more or less trained on concepts.
One of the best model i found, the best on quality/speed/prompt adherence, great job !
Hey man, great work!!
i would only add that it would be good to have a non lightning version (with the lightningx lora excluded from the checkpoint) for the people that run the full f16 models. can you help with that?
A version without lightning would not be different from this, because it would remain fp8 non the less, just slower, at this point maybe even worse. The composition and fine-tuning is made with that lora's, excluding them could degrade the quality, I would have to make a whole separate testing lab. Full FP16 is not planned atm, full fp16 WAN 2.2 would not even run on most hardware out there.
@darksidewalker Personally, I'm totally fine with the current FP8 version (or a mix with some FP16 blocks). By the way, could you share what strength value you used when merging the Lightning LoRA?
@darksidewalker the issue is, the best results we can get is with the 3 ksampler workflows, i did multiple tests to figure this out. The first ksampler should not contain a lightning model, and its usually with a cfg of 3.5 or more.
@Johndoe1911 I do not think that. I did many 3*Ksampler tests and they where not that good. In fact almost every time worse, just a bit more motion.
@darksidewalker thats strange, its possible that we have different use cases. i create i2v from images of real life characters, and i compared the 3 ksampler and it results with the most most realistic render. granted, i do get excellent results with the 2 ksampler workflows using your wan2.2 checkpoint. in fact, your checkpoint is better than other checkpoints such as "remix" and "smooth mix" when it comes to realistic physics. so really great job! but the 3 ksampler approach still results in better prompt adherence + higher detailed output on frames that were not visible in the original image.
@Johndoe1911 I would have to make a poll, what ppl want, making a other model approach is possible, but the testing and tuning all different approaches would be extreme.
Also it will be slower with this approach. Plus it will add complexity in using it, what was not the purpose of the model.
Please someone make a MidnightFlirt GGUF version either Q8 or Q4 model
Edit: I think I found it on hugging face
You can read up on that on my announcement, but a gguf of this will have major downsides. The unofficial one on HF will also a huge degrade in quality. So I don't recommend.
Also I tested these unofficial builds and they had extreme bad quality below q8 (what also was around 5-10% degraded in quality).
@darksidewalker Thanks for the advice, I haven't really tested the base much bc it takes longer but the wait might be worth?
Ah yes, if there's an official GGUF version, that would be something to make God praise, lol. After all, the graphics cards used worldwide are still mainly those from before the 40 series (refer to the graphics card usage proportion data released by Steam).
@AI_Master_Workflow I know! But I just had not the resources for a full fp16 precision model to process into a gguf. And processing a fp8 by various tricks into a gguf like the unofficial just kills the quality at all.
But ... that said ... I'm on something here ... maybe. mysterious whispering
Does anyone have any specific opinions on a difference of any of these from the others?
MightnightFlirt, LureNoir, RadiantCrush, TeasingKiss, CheekyDream, HotSpring, and SweetSpot
The differences are clearly documented on my announcements and "About this version" as written on the front-page.
@darksidewalker Yes. I'm asking about people's opinions, as clearly stated in my comment. Thank you though. Video models just take so long to do thorough tests with, and when one part is improved, another might be lost, or a new problem might be introduced. I still use older versions of other checkpoints, even though the later versions always say everything is improved by the person who trained them.
Anyway, I just got the latest and am trying it out for now. There's just so much here. Thank you for merging and tweaking these.
@Jellai For me the last two versions have similar quality. The last one have been better for no prompt, I got surprised since it did a exactly what I was looking for when with Lure Noire I couldn't get the result with my own prompt. And last point is fluid, last model is better.
I mostly use this checkpoint to generate anime and east asian style video. I found this is the most perfect checkpoint for my task that I have tried, not "one of":
1. Facial expression control is moderate. Other checkpoints or +lora always performs extremely exaggerated facial expression, that not only changes the atmosphere of original image, but also destroys the face.
2. Motion and movement control is reasonable and moderate, not too intense.
3. Prompt compliance is good. This checkpoint seems will not add any additional movement and facial expression unless you mention in the prompt.
This checkpoint is suitable to the tasks that, 1) you don't want the characters act too intense and do some addtional motion. 2) you want the characters keep consistency to the original image.
Your model is simply stunning. The moment I started using it, I immediately deleted my GGUF files. The updates are also very fast, and I look forward to your new works. However, I still can't afford the early access—it is indeed a bit expensive.
It was measured on the invested time. And it was optional, it will going free and if the tools are better and I can do more without burning private money I would open it for less. Everyone can support or wait, as one likes 😊 I did consider to open it for less in EA, but doing so in between would scam the one who already payed buzz.
Also the next one will not come as fast, so don't worry
is the model good for 10 seconds video? 3-5 second have a good result but when generating 10 sec video appears anomaly on genital part
Did you generate the full 10 seconds in a single run, or did you do it in two passes (using the last frame of the first clip to start the second)?
I do multiple passes and merge them.
@g1263495582 10 second in single run
@darksidewalker second generate with the last frame and combine it in video editor software?
@Lev1123 Instead of an external video editor, you can stitch them directly in Comfy. Check out the Wan2.2 Painter-Longvideo-Generation(Uncensored/NSFW) - v1.0 | Wan Video Workflows | Civitai. or synystersocks/ComfyUI-SocksLatentPatcher(in example workflows). For a simple join, you can use the Merge image node (from ComfyUI-VideoHelperSuite) and skip the first frame of the second video like THIS.
{kind=link}
If the movement feels slow, try using the PainterI2V node to boost the motion. Stitching clips for longer videos may result in minor color shifts. Keep in mind that Wan2.2 has a hard limit of 7 seconds (16 fps), with a native duration of 5 seconds.
@darksidewalker Also, for PainterI2V, I find that a motion_amplitude around 1.05-1.1 works well for me.
Absolutely fantastic!
However, even when I specify "pussy juice", "saliva" or "streaming tears" in the prompt with "2d anime", cum still flows out of the pussy, mouth or eyes.
Do you prompt natural language or tag-based? Because tag-based won't be understand properly by WAN 2.2. Also "pussy juice" might not be a known thing.
I did about 9 samples like this (https://civitai.com/posts/24607726) with different styles. In 3d, in 2.5d and 2d. No cum for tears. 🤔
@darksidewalker
Thank you so much for your guidance.
I'll document the results of my tests here. I hope this proves helpful.
I'm using the “Wan 2.2 14B Image to Video” template in Comfy-UI.
My prompt was: “Anime style scene of a girl. Her vagina starts dripping transparent fluid.” (Incidentally, even though this is the only element specified, white liquid sometimes flows from her mouth as well).
After several attempts, I found that if the “Start Image” already contained transparent tears, the prompt “The girl is crying with translucent streaming tears dropping from her eyes, chin, and face.” produced the expected video. The “Start Image” is a close-up image of the face.
When the “Start Image” contained no tears at all, the same prompt resulted in tears that were mostly opaque white (though slightly or partially transparent in places). Changing ‘translucent’ to “transparent” produced tears that were partially transparent and partially unnaturally blue (with blue reflections despite no blue surroundings).
For “Her vagina is dripping transparent fluid,” even if transparent fluid was already present, it often became opaque white fluid. Sometimes it remained transparent. The “Start Image” is a full-body image of a single girl depicted in a sexual context.
When tears were specified in the prompt simultaneously, or when only the tear prompt was specified, the tears also turned white, even if transparent tears were already present.
Must admit, this one is very close to a SoA product. Amazing motion and prompt following without any additional loras. It alone does now what i could not get with different loras and previous version.
With enough RAM and swap it is possible.
I read about wan2gp, what's also possible with some quality loss, maybe?
可以嘗試限制COMFYUI的VRAM用量,例如使用Set Reserved VRAM(GB) ⚙️節點,別讓他使用到共用記憶體,通常都可以,否則速度會非常慢。或許可以嘗試我的工作流?我希望他有作用。
I want to thank you for listening to me and releasing the FastFidelity C-I2V workflow.
Fantastic model. By far the best model for animated/anime artistic thematic videos. this and Ratatoskr are peak model design
A powerful model, number one, its greatness needs no further explanation!
Pairing this with Illustrious images is perfect
I used your workflow for Swarm (I strongly dislike comfy) and all the renders look very pixelated (different resolutions, e.g., 768x1136). I don't use any LoRA—I took your workflow for SwarmUI, my render from IL, and that's it. What should I do?
Is the workflow for Swarm already outdated and not working well? If so, is there an option to create a newer one for Swarm? Plus, if I wanted to use your latest workflow in ComfyUI (in Swarm), would it work the same as if I downloaded Comfy separately?
Last time I tested the Swarmui preset it was working, but swarm is extremely limited when it comes to video generation, although it is superior for image gen.
But I do not use swarm for video, I switch into the comfy backend with my workflows for video.
I would just to use the comfy workflows inside the backend, this is totally valid
its a great model overall but for some reason, BJs are almost impossible to get right, even with the right loras. the movements are too shallow on those attempts and we barely get any action. Any tips?
Other than that, it's the best checkpoint I've used so far, it really maintains the details well
I would suggest using LureNoir over MidnightFlirt, the latter seems to be a lot more obstinate when it comes to anything that doesn't involve thrusting, and that includes BJ's for some reason, even the type that would use thrusting.
@TeeKay interesting, I'll give it a shot, thanks!
I need high and low noice models in the same time?
both models are needed for generation
@Chessie951 nooooo
@Rating_Agent yeeeeeeeeeah, but not at the same time
@qek wdym? i downloaded high version only
@Rating_Agent won't work, you need both
@Rating_Agent Low is to refine
where to get the low noise version?
@Rating_Agent the high model is for motion and low model is for details, sounds like you're gonna need a wan2.2 workflow
@draism229 Next "model version"
Has anyone ever come across a character constantly bouncing\randomly moving\shaking? I've tried literally everything I can think of, nothing helps (including negative prompt)
Did you accidental added a lora that causes this? This never happened to me O.o
@darksidewalker No, I haven't used them at all yet... Do you have a discord or something where I could send you an example of the settings and what comes out?
@darksidewalker I reduced the total number of steps to 2 and got much less unnecessary movements :)
@seawolf338 Does 2 steps work? Didn't tried that before. I also have a discord, it is on my page.
PSA: The cause was the EX version, with the painterI2V sampler (experimental)
I have the issue too
@realfixtion227 Than do not use the painter node
@darksidewalker I dislike Painter, the creator could at least merge all the nodes instead of making 7 repos
I'm curious will there eventually be a model thats made for 12gb cards? I guess a 5b model?
No, WAN 2.2 5B will not be made, the model is just not good enough.
@darksidewalker 1.3B is somewhat usable, but 5B outputs total trash, especially when I need i2v, neither 1.3B is great, the 14B model is better
I use the Cheeky model with my 4080 12gb card just fine. I use Wan2gp to run the model in Pinokio
I will be happy if you can add a understanding of thighjob and shoejob to the new i2v model
That's maybe too specific to match with other things I guess. But I'll put it on the list :)
Is there a reason not just to use a lora for that?
@darksidewalker thank you for considering this. because I have tried many loras and all of them are focus on insertion. the final output always becomes girl bouncing (cowgirl position), but not rubbing.
Well I tried some things and it basically understands such things. So atm I see no need to further refine this. Did not even used a lora.
I'm super new to img-to-video, and basically everything about it is confusing to me, including the "easy to use" workflow by the creator, so I had to make my own with the help of Gemini. I have an output, and it is like, legible, but it has this awful noise on it that I see a lot with regular image gen when the step count is low. Gemini can't figure it out, so I wish to rely on y'all. What am I doing wrong, please? Here's some links (obvious nsfw warning):
{kind=link}
{kind=link}
If you are completely new, I suggest reading this: https://civitai.com/articles/20293/darksidewalkers-wan-22-14b-i2v-usage-guide-definitive-edition
The thing is, if my (really) easy workflow is already confusing you, you may look up some basic tutorials for comfy.
In case you used the C-AiO, maybe start with the just C-I2V, it is just the complete basic thing. On the workflow page there is a clean description what the workflows are doing.
Bro it is possible to implement better clothes undressing control in next versions?
The words are censored, I can not read what you trying to say.
I don't think so. WAN itself is just capable of that what you now have, it would need spacial training or a lora to implement on that. And just for some nuances of undressing it is much work.
@darksidewalker well thats true
I am too tired until I found your. Great work!
I have problem with va.gi.na, it is always has a ball. How can I prevent it? I tried many prompt but if there is character alone then it show without problem, but if there is a man goes in, we have funatari girl
You can't use it like T2V, if you are trying that.
@darksidewalker Thanks for the reply, I don’t use T2V, only I2V, and I don’t understand that part. I can make someone enter the scene, but it doesn’t work that way. What should I do if I can’t use it?
Entering complex things into the scene, especially NSFW stuff that are not already inside the image is not a strong feature of I2V wan 2.2, that's more a thing with T2V, but there you can not really define the look and feel like I2V.
@darksidewalker Thanks
Where do you see further potential and what improvements can we expect in the future?
Why asking?
Just out of curiosity
Well. We will see, there are things planned, but I'm not ready to spoiler yet
I’m looking forward to seeing what you have planned :D
@darksidewalker you have my axe.
@eoa42 I'll use this tools of power!
Hello, I am running a rather primitive workflow due to not understanding how comfy UI works and how to download anything. It appears to work alright, but what is the standard negative prompt that you use? Everything I try results in very bouncy characters. Thanks!
Negative do not work without NAG because of CFG1.
For more WAN 2.2 understanding, try this: https://civitai.com/articles/20293/darksidewalkers-wan-22-14b-i2v-usage-guide-definitive-edition
wich lightX you merged in? could we have the exact formula? thanks
Already documented in "About this version" and the announcements as much as I will share
Really good Model. How ever I cant achieve the same prompt adherence as you have in your example. When I enter
"She is spreading her vagina with her fingers, slightly moving her fingers around her vagina, female masturbation."
And the starting Image is a girl with spreaded legs, she will only rub upon her vag up and downwards. How many tries did it take for you do achieve that?
1 try, for real.
Many problems arise with sage-attn, mem-caching addons or alternate samplers. I just used the standards. No sage, no mem-cache, euler+simple.
@darksidewalker
Ah okay did not know that.
It was so painful to setup sageattn but I will try without it
@haenlesn937 Yes it is. You could make a copy of your comfy and set a new one, if in doubt.
I tried a lot of times; i think the model can`t make close vagina spread , if you want to have it , you need to use a image withvagina spreading
After using this models several days,I have a problem cannot solve.
When I input a picture with a girl whose genital is covered by cloth and let the model generate a video which the girl‘s genital is uncovered at last,then there is usually a strip with the same color of labia attached to the vagina and hanging,especially anime character in a front view. But using same input and prompt with other ITV model I recently used is all okay.
I used some prompt in NAG but the situation get worse,I think maybe use lora can solve the problem,but using Lora usually borke the model’s great performance in keep consistency of character.
Confused.....Is there anyway to solve this problem using some prompt only?
I actually have the same problem, a flesh-colored protrusion comes out of the vagina, sometimes longer than other times. It even jiggles. It's almost like a penis.
The model is not trained or optimised to do undressing related stuff. As this might work to some extend, because WAN 2.2 basically can understand anatomy, it is not intended.
Undressing/nudifying related LoRAs/concepts with real individuals are not allowed from civitai. (See ToS) So I can not provide implementation here.
This model has some kind of problem with the letter "r." It's been through 10 generations now, and it constantly skips the letter "r" in the text I prompts for generation. Increasing the CFG doesn't help.
Nothing I can do about that. Text is not a strong point of I2V WAN 2.2, also it is just fp8 precision that's not the best base for text. That's also stated on my announcement for this checkpoint.
@darksidewalker Yeah, I get it. It's just that your model preview videos with text turn out pretty good.
@MrDxrk Yeah, with multiple tries and refined prompting till success.^^
Man, I saw your announcement of the new model. I just want to say, I use your models(for images and videos gens). My PC is not very powerful, I use swap for generation, but I will squeeze the maximum out of my PC to create high-quality content on your Q8 model. I love your work.
Thank you! You cloud try a lower quant later like q6 or q5, they produce really good results too! Maybe that's just faster and can achieve your goal too!
Awesome job with this, was holding off till the slow-mo issue was fixed and it’s so much better now. Thanks for the workflow too!
Thank you! Now create some awesome art! smirk
Sorry about noob question, but I get an error:
# ComfyUI Error Report
## Error Details
- Node ID: 425
- Node Type: ModelSamplingSD3
- Exception Type: AttributeError
- Exception Message: 'NoneType' object has no attribute 'clone'
Node ID:425 has only value "shift 5.00". I dont even pretend to understand your flow, any ideas what is the problem?
Search using AI mode and solve it yourself.
If you see errors related to PyTorch or similar in the ComfyUI startup log, copy and paste that section and let's go through it step by step.
※ Trying to fix everything at once may cause errors due to inconsistencies.
So, I'm using authors workflow, have updated everything.
[DEPRECATION WARNING] Detected import of deprecated legacy API: /scripts/ui.js. This is likely caused by a custom node extension using outdated APIs. Please update your extensions or contact the extension author for an updated version.
Considering that the author seems to know his/hers stuff, could the workflow really be faulty?
You did not select a model, the node is empty.
Just the best of the best ! thank you for sharing this masterclass !
Wait till you use my new "TastySin" ... it is even better :)
Hello, this works amazing. Just one issue. When working i2v and having the woman pull up skirt or pull down pants the vagina it shows always has a large piece of skin hanging out of it, like it wants to create a penis. Any idea how to change this. Most of the loras I have found really degrade the quality of this great model.
The model is not trained or optimised to do undressing related stuff. As this might work to some extend, because WAN 2.2 basically can understand anatomy, it is not intended.
Undressing/nudifying related LoRAs/concepts with real individuals are not allowed from civitai. (See ToS) So I can not provide implementation here.
So MidnightFlirt is the best model?
"TastySin" is at this time. https://civitai.com/models/2190659
FLF2V support?
Either FLF2V or FMLF2V is fine.
No
@qek No? It is FLF2V capable, even my workflow supports this with no issues.
Will be there a FP16 Safetensors version? Trying to convert Float8_e4m3fn to the MPS backend but it does not have support for that dtype.
My gguf version "TastySin" is based on fp16 safetensors. MidnightFlirt will not receive an fp16 version.
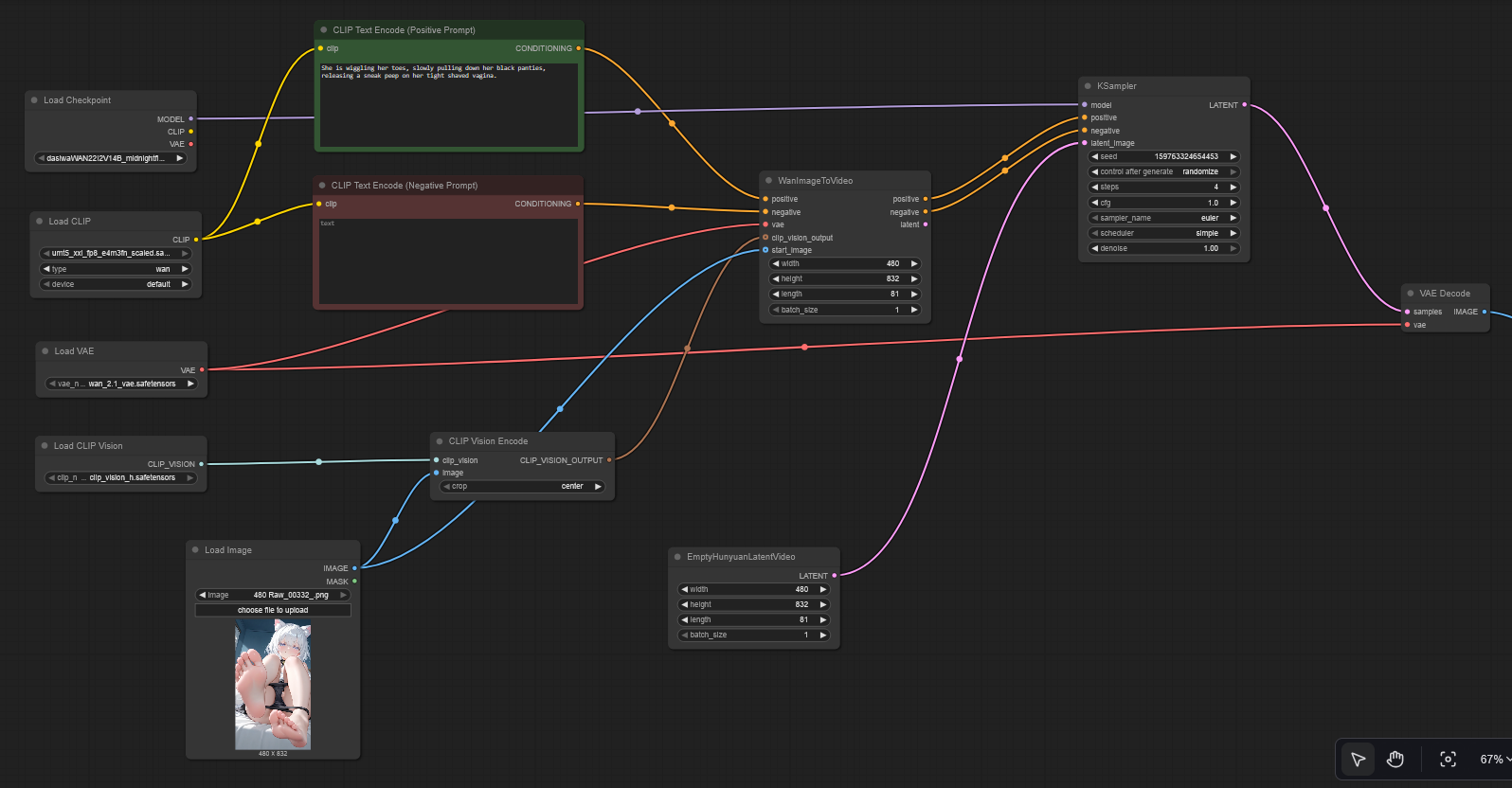
Hi! Thanks for posting this. I have a question, as I'm a complete beginner: why does the recommended workflow show two SafeTensors (low and high) when it only has one? There doesn't seem to be an option to use it individually. Any help would be greatly appreciated. Thanks in advance.
You can not use WAN 2.2 with one checkpoint.
As you are completely new to this I would recommend you reading my guide https://civitai.com/articles/20293/darksidewalkers-wan-22-14b-i2v-usage-guide-definitive-edition
@darksidewalker ♥Thank you for your prompt reply♥. I wanted to give you some feedback as a beginner: I followed your advice and read the guide carefully (thank you so much for your dedication in creating it). I had read it before writing this message and learned several things, but honestly, it didn't help me resolve the specific confusion about having only one Safetensors file (the FP8 Lightspeed) while the workflow insists on two separate inputs (High and Low). The guide didn't seem to cover this specific 'single file' scenario clearly for the FP8 version.
The solution that worked for me was to remove the specific 'High' and 'Low' load nodes. I replaced them with a single standard 'Load Diffusion Model' node, loaded the file there, and connected it to the rest of the workflow. It works, although I haven't tested whether the quality is the same as in the examples.
@blurgreen Well, mate. You did not solve the problem, you killed the whole purpose of WAN 2.2.🤔
You may have not read the guide properly. You need both high+low checkpoint and use them both, WAN 2.2 is MoE with 2 checkpoints. There is no single file scenario with WAN 2.2.
@darksidewalker That's exactly what I thought, and what the guide says, so I still don't understand why there's only one download available on this website and not two. Is there any way to split it into two? I've never been very bright, and I'm sorry to waste your time, but I really can't find any answers online or with AI that help me solve this or at least understand what I should do. Thanks again for your reply.
@blurgreen Oh, I see you did not see that there are a high and a low version to download. Well, its right under the headline "MidnightFlirt High v7" and "MidnightFlirt Low v7", you just download both.
@darksidewalker Damn, I've made a terrible fool of myself. Sorry for the trouble and thank you very much. 😳
@blurgreen No problem, I did not realised what your problem was ether XD
Could someone please tell me how to prevent characters from keeping their eyes closed too much in 2D animation?
Even though I give them distinctive eyes like “empty eyes” or “ringed eyes” in the starting image, they end up keeping their eyes closed the entire time.
Thanks.
You add a brief description of the eyes and what they make for a facial expression.
Even when specifying a prompt like “She does not close her eyes” it did not function.
negative forms do not work good on positive prompts. Maybe something like "She is looking with open eyes to..."
There are so many videos, none are clothing her eyes, I do not know what the problem should be.
hello am trying to use the v6 high model and getting different actions and characters than what am prompting for img2vid, am using a forge neo
example when i prompt for a girl, ill get a girl at the beginning but she turns into a man or a goblin
can i get some help
This is not a Test-To-Video model. This is Image-To-Video, you have to use a initial image and stick to your image input. Also you need high+low.
@darksidewalker but I am using image-to-video
Did you use lora at high noise?
@g1263495582 nope just the model.
i found the issue in forge if you load the low model first the issue happens, i loaded the high 1st its fixed now thx
Hi DaSiWa. Sorry for asking a stupid question but what is advantage of using your GGUF model instead of this? Found that video generation time on your test results are somehow much longer on Q8.
Hi!
1# The differences are all documented on the front-page and the announcement (my articles), no way I write all this here.
2# The notation of the times were not equal, so I corrected that, they are not significant faster/slower.
3# Safetensors is always a bit faster than gguf, gguf has other advantages
4# The base used for gguf has fp16 and here is "only" fp8, so the comparison is a bit lacking
How did you compare the times when generating?
@darksidewalker I haven't tried GGUF version yet, this question only arised after checking your test result (which were tested in your local env; 16gb vram, 64gb memory). Will carefully read your guidance and notices, thank you!
Amazing model and workflow, one weird problem: several prompts that don't involve any penetration frequently result in pelvic thrusting in the air throughout the video, any idea what could be causing it? No LoRAs active and happens with many varied prompts of differing lengths and level of detail in the description of action.
Post your prompt
Here is a recent example:
[start prompt]
she's having a casual phone conversation while sitting on a chair against a green wall. a naked man's lower half enters the frame from the right, his (large, long, straight dick:3) out and in front of her face. (she looks up at him but does not touch him and continues her conversation:5). then, (the man starts stroking his dick rapidly with his hand only while standing completely still:5). the girl maintains eye contact with him and keeps talking on the phone.
masturbation
[end prompt]
The start/end prompt tags above are not in the actual prompt, they are just in this comment for clarity. The resulting video almost follows the prompt perfectly, but even with me giving weight to "standing completely still", the man in this case is humping the air while masturbating.
@ungabungajunga humour me and try changing "out and in" to just "is in" so it reads "his (large, long, straight dick:3) is in front of her face". wan is likely grabbing "out and in" and assuming 'oh we know what you mean THERE' when.. that's not what you meant. Just a guess though.
@mmrift466 I see what you're getting at, makes sense, but unfortunately I ended up with effectively the same result. The image I'm using is a stock photo, wonder if that has anything to do with it, but that's a wild guess. I'll keep playing with the CFG and step count to see if that makes a difference. Some LORAs make an impact so that might be the solution for these cases.
@ungabungajunga try altering the 'shift' values as well, i find that sometimes higher shift values result in cyclical motion, including gyration/thrusting
@sixpt55 Interesting, I've never touched the shift (default is 5 for the included workflow), so I'll try that and report back when I get a chance.
Prompt output verification failed: missing required input: frame_rateVHS_VideoCombine:- missing required input: frame_rate. What does this mean when generating?
I don't know why you post this to the checkpoint, but this is for sure a problem inside the workflow you are using or missing dependencies inside the workflow.
it's because you didn't specified any framerate numbers to your final video output in vhs video combine..... juste type 16 or 24 in it (put 16).
Details
Files
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
Mirrors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLow.safetensors
dasiwaWAN22I2V14B_midnightflirtLow.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLow.safetensors
dasiwaWAN22I2V14B_midnightflirtLow.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
dasiwaWAN22I2V14B_midnightflirtLow.safetensors
dasiwaWAN22I2V14B_midnightflirtLow.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
DasiwaWAN22I2V14BLightspeed_midnightflirtLowV7.safetensors
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.