












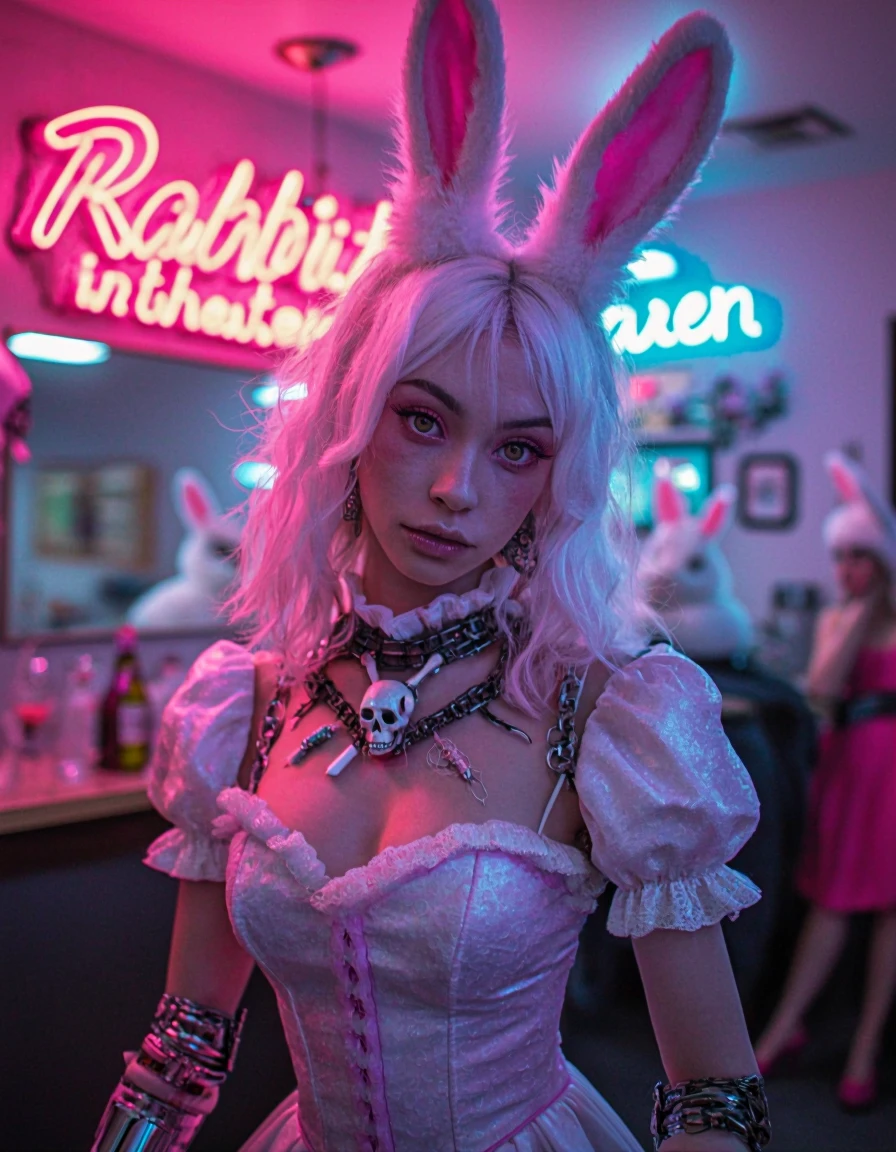





This finetune aims to improve reliability in realistic/photo-based styles while preserving Chroma’s broad concept knowledge. The v1.3 flash version has the rank-256 lora (from here) baked in. bf16 and fp8 available --->. GGUFs on HuggingFace.
Prompting: Simple prompts describing what you want to see in natural language works well (example1, example2). Chroma prompts work well. Examples of captioning style used in training: woman sitting, waterfall, wolf, woman in dessert. Negative prompts don't work at CFG one, but above one negative prompts can be important.
Example settings (not necessarily optimal) using Comfy's default Chroma workflow:
Base: Steps:: ~30-40. CFG: ~3.5 (best settings depend on steps/CFG/sampler, etc.).
Flash (lora rank-128 or 256): Steps: 15-17. CFG 1. (Depends on lora rank, sampler, etc.)
Sampler: Examples use res_2m, dpmpp_sde, or exp_heun_2_x0_sde. Others are also good.
Scheduler: I like bong_tangent | beta & beta57 and others are also good
Support:
Have too much money? Want to support further training? https://ko-fi.com/dawncreates
Training Details
The model was trained locally, using Chroma-HD as the base. Each epoch included images at 3–5 different resolutions, though only a subset of the dataset was used per epoch. Except for the extra resolutions, OneTrainer's default config for 24gb Chroma finetuning was used. The dataset consists almost exclusively of SFW-images of people and landscapes, so to retain Chroma-HD's original conceptual understanding, several layers were merged back at various ratios. All the juice, compositions, subjects, and concepts come from Chroma itself, my model just nudges it towards realism. Honestly, this version is a showcase of how good Chroma is. So get to work on Chroma finetuners - it has so much potential!
All images were captioned using JoyCaption: https://github.com/fpgaminer/joycaption
The model was trained using OneTrainer: https://github.com/Nerogar/OneTrainer
Description
The flash version of v1. With rank128 of this baked in: https://civitai.com/models/2032955?modelVersionId=2301203
FAQ
Comments (25)
If possible, please also provide a GGUF version (without Flash).
It should be possible. I will try to get it done as soon as possible, but it might be a few days (I'm a bit busy).
@dawncreates Thank you for considering it.
@fantaseed I've added a few quants on HuggingFace
@dawncreates Thank you. I will study how to use Chroma.
This is a great checkpoint. Thank you so much.
Thanks! Honestly, I think Chroma is the real magic here. I think I've found a nice finetuning process, but all the things this model can do comes from Chroma - not my dataset. Excited to see what other finetunes we'll see from Chroma! If I find the right open datasets I might try to replicate this process with other styles.
"medium sized collection of openly licensed images". what does that even mean? what is a medium sized amount? why not just write the actual dataset numbers?
Well, it's not that straightforward for two reasons. 1. This is actually a merge of two different finetuning experiments that use slightly different but overlapping datasets. 2. I don't know how many - or exactly which - images were actually used in the training. Only a small sub-set of images are picked randomly for each resolution/epoch. I outlined it a bit in this reddit comment.
I can find and list the total number of images in the datasets, but that won't tell us how many images were actually used in the training.
Really good job with this checkpoint!!! respect
Thanks. But I want to repeat what I've said elsewhere (mostly so other finetuners can see it), this finetune should NOT be this good. It really is base Chroma doing all the heavy lifting. I can't wait to to see what an actually good finetune of Chroma can do.
@dawncreates regardless I'm liking the results better than the standalone Chroma I do find this one to be very slow though on my rig especially with your recommended settings but the results seem to be worth it. Take the pat on the back hehe ;)
@StecFX I'll accept the pat :-) I imagine it is possible to get good results at lower steps with a different ranked lora. But steps/CFG/Sampler/Lora-rank seem to be very finicky to get right, so it requires a bit of experimenting. I've also done very limited experimenting without a flash-lora (I'm very time constrained) - so don't take my non-flash settings as gospel. If you find a setting that works at lower CFG it should help speed things up.
I had my usual problems with Chroma with this one until I did something by accident. CFG 3.5 looked burnt to me, but 3.0 gave me blockiness. Then I tried a linked GGUF from Huggingface, thinking it had a flash LoRA built in, leading to a mushy, grainy, old decaying photo style - interesting but not too realistic. Finally, in desperation I tried the GGUF with flash settings, no flash LoRA, but with Danrisi's Lenovo Ultrareal LoRA. Still kinda grainy, still a little mushy, can probably be improved, but I'm getting better pictures than I've gotten with any other Chroma.
This sounds strange. The ggufs and the normal models work much the same in my tests. If you get burned out images with CFG 3.5 the issue could be the prompt or some other setting. What happens if you adjust the negative prompt to something like the one used here?
I like it so far but seems to produce a loot of grain effect and characters loras somehow does not work well
I agree. there will be an update to his model that reduces artifacts/grain in a few days (not sure when). Training is still in progress, but it's already a big improvement in terms of reducing grain and clearer details/backgrounds.
Haven't done much testing with loras. Style loras trained on Chroma seem to work well, but I guess it makes sense that character loras - that need more precision - are less accurate if trained on Chroma.
what's your joycaption prompt?
I was looking for it but I think I've accidentally overwritten the prompt I used originally, sorry. I am currently doing a new finetune test-run with new captions. The hope for that run is to create a clear separation between both amateur-professional and stage/posed-candid photos, so the prompt is focused on that. The captions look good to my eyes, but lets see what happens with training... For that run I am using this prompt with a high maximum tokens setting:
"Write a long and highly detailed description for this photo. ALWAYS begin with the type of photo (e.g. “professional analogue landscape photography”, “amateur street photography”, “professional slice of life photo”, “documentary style photo”, “amateur landscape photo”, “professional landscape photo”, etc.). ALWAYS mention if the photo is a candid photo or a staged or posed photo. Continue with the main subject and medium. When describing the rest of the photo, focus on concrete details like color, shape, texture, and spatial relationships. Show how elements interact. Describe people's age, body and features. Specify the depth of field and whether the background is in focus or blurred. Include information about lighting. Include information about camera angle. If it is a photo you MUST include information about what camera was likely used and details such as aperture, shutter speed, ISO, etc. Mention whether the image depicts an extreme close-up, close-up, medium close-up, medium shot, cowboy shot, medium wide shot, wide shot, or extreme wide shot. Explicitly specify the vantage height (eye-level, low-angle worm’s-eye, bird’s-eye, drone, rooftop, etc.). Never mention what's absent, resolution, or unobservable details. Vary your sentence structure and keep the description concise, without starting with “This image is…” or similar phrasing. Do NOT use polite euphemisms—lean into blunt, casual phrasing."
This was my intro to Chroma. It's blowing my mind though. Best for nsfw realism that I've found. The creativity is amazing. I initially had some issues with artifacts and blur but after some tinkering and adding loras I've hit a sweet spot. I 100% recommend giving this model and Chroma a serious go. Thank you!
Thanks - yeah, Chroma is great. There will be an update to his model that reduces artifacts in a few days (not sure when). Training is still in progress, but I did some tests yesterday and it's a big improvement in terms of clarity.
So what loras do you use?
This is a really nice finetune of Chroma. Flash is especially good.
The only criticism is it seems to inject a lot of noise in where it's not needed. Any tips for that?
Edit: Nevermind, I saw the comment from a few days ago that it will be fixed in a newer version.
Bit delayed because of life, but hopefully I can update it soon.
Updated.