Even though it's called a "Starter Suite", it's not just for learning the basics—you can use it in many different ways depending on you. The reason this workflow package is as large as 500MB is because it includes six sample videos in a fully reproducible form. For installation and usage instructions, everything is explained in detail in the YouTube walkthrough below, so please check that first.
Due to compatibility issues between Node 2.0 and the rgthree nodes, I've removed rgthree from my workflow. It was only being used for seed generation, so it doesn't affect anything, but the workflow embedded in the sample videos still includes rgthree. If you want to try the samples, I recommend using the workflow.png file instead of dragging and dropping the video to open the workflow.
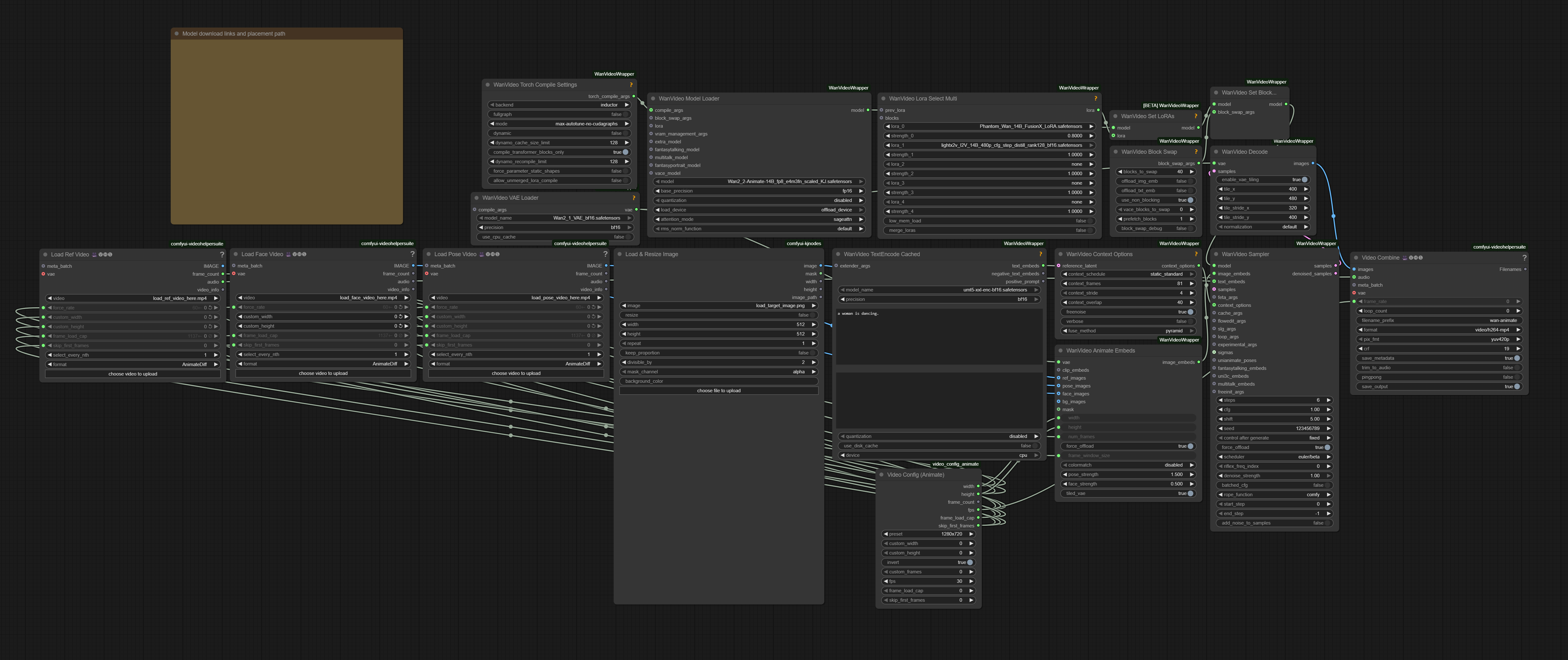
Here, I'll add some notes on things you should adjust depending on what you want to generate, points that were not covered in the video.
[WanVideoSampler: steps]
Adjust the values based on the complexity of the motion. Setting a high number of steps for simple motions with very little movement is just a waste of time.
6: This is the baseline value. Try using it first.
8: Select this when the character's movement is extremely fast, involves rotation, or moves significantly forward, backward, or sideways.
https://www.youtube.com/shorts/V3b8lLm9wF0 Example of extremely fast movement.
https://www.youtube.com/shorts/J8gyHmYRHlE Example of a character spinning repeatedly.
10: Select this for extremely difficult generation tasks, such as drawing the character's back view while keeping the outfit consistent even though it is not shown in the input image. Even then, the results will still depend on luck...
https://www.youtube.com/shorts/l2vxSoJSV3o The part where the back view continues for four seconds is extremely difficult, almost like a nightmare.
[WanVideo Context Options: context_overlap]
Increasing this value makes the motion flow more smoothly and reduces background warping, but it also increases the generation time.
[WanVideo Decode]
In my workflow, videos at a resolution of 720×1280 are decoded by splitting them into 8 tiles. Using more tiles reduces the load, but it also increases decoding time, so ideally you should adjust the settings to match the resolution you plan to generate. If you want a rough suggestion for values that fit your environment, you can ask ChatGPT to calculate them. If you're not sure what to use, the default node settings (tilex: 272, tiley: 272, stridex: 144, stridey: 128) should work fine.
[Lora: FusionX]
As a side effect of its very strong stabilization, it tends to generate similar-looking faces. This becomes especially noticeable in close-ups or smiling shots, so lowering the value or not using it at all can be an option. There are many types of speed LoRAs, so if you find good options or combinations, please let me know.
Thanks to all the model, node, and LoRA creators, and to the community and followers who give me motivation and inspiration.
Description
Initial release. Includes the generation workflow, the pose estimation workflow, and six sample videos.
FAQ
Comments (32)
please provide links to the onnx files needed for motion capture workflow! musch appreciated! great workflow!
I’m glad to see that it’s working well for you now.
lol yeah just looked for the onnx files on huggingface. Great workflow nice and clean/easy to tweak
@CharlesBarruls Hello, I see you've tested this workflow extensively. Have you tried any filters to improve the video quality? For greater realism?
@drak0n ive just adjusted the weights of the fusionx lora and the face and motion adherence. best advice would be starting with high fidelity source images and animation captures (videos you sample the motion from) best of luck. This is an excellent workflow imo.
@CharlesBarruls I also like this workflow, but I can't stabilize the background. That's the big problem. Otherwise, the workflow is one of the best I've used. But when, for example, a wall socket appears and then disappears, or a lamp appears and then disappears, it's not quite right. The other workflows I tested don't have this problem. I'm still looking for ways to reduce these inconsistencies. At the moment, I can't really find any.
@drak0n forgot to mention i also use the florence model captioner that provides the prompt a caption of the input image to reduce inconsistencies.
@CharlesBarruls Interesting approach. It may reduce some inconsistencies, but they are still there. This is strange. I would understand if it happened in general, but it seems to be specific to this workflow. While the other "animate" workflows have problems with the movement and consistency of the person's face, it seems that here they are solved, but another problem has arisen with the background.
@drak0n if you can please send me a .json of the workflow that is producing the inconsistent character motion but the stable background to compare.
@drak0n Have you tried dpm++_sde? Compared to eular/beta, it converges noise faster, so it’s effective for stabilizing the background. In that case, try setting the step count to 4.
is there any way to use it in 3060 please help its need very high ram nearly 60 gb
60gb? How long is your video ?
It may help to use a lightweight GGUF model to reduce memory pressure when offloaded.
https://huggingface.co/QuantStack/Wan2.2-Animate-14B-GGUF/tree/main
Can you create the workflow in Seaart? You can make videos for free using Comfy UI there.
Do you NEED 100GB of ram or does that just improve the efficiency?
Another question: I have an rtx 5080, but the generation cancels because I run out of memory. I followed the video 1-1, so I have no idea why. Might you have any ideas?
It doesn’t improve the efficiency. It just allows you to create longer videos. If you’re running into OOM crashes, instead of generating the full length, you could try testing with around 150 frames first. You can set the partial generation length using frame_load_cap in the VideoConfig (Animate) node. It’s also important to test under lighter conditions, such as lowering the resolution.
@UncleHooru lol son of a bitch I totally reinstalled comfyui cause I thought I fucked up myshit
Given groups=1, weight of size [5120, 36, 1, 2, 2], expected input[1, 68, 21, 80, 45] to have 36 channels, but got 68 channels instead
Please help)
I feel like I’ve seen this error during image generation before. Trying FP16 versions of the text encoder or VAE might help, or updating ComfyUI could also fix it?
I used fp16 bf16 fp32 vae, unfortunately it didn't help
@Vlad74477447 I had that error when I started using comfyui too. I think that happens when you mix vae, umt and diffusion model/checkpoint types. Since I use all of the same type I never got that error again. For example umt (text encoder) fp8 diffusion model fp8 and vae for fp8 (though not sure about vae, because many vaes are broken anyway, for example I have always to use vae wan21, even for wan22. Because vae wan22 never works in comfy ui for me.)
@bluenightlagoon thanks friend
Please can you help me understand what this error means: "Exception ignored in: <function ProactorBasePipeTransport._del__ at 0x000001DE0617C7C0>
Traceback (most recent call last):
File "asyncio\proactor_events.py", line 116, in del
File "asyncio\proactor_events.py", line 80, in repr
File "asyncio\windows_utils.py", line 102, in fileno
ValueError: I/O operation on closed pipe". Thank you in advance.
It seems to be a message that appears after the process ends, especially when an OOM error occurred just before it.
This workflow is so powerful, thank you!!!
Truly appreciate you sharing this! Do you have a workflow that you use to create your great initial images?
hi can you help me where to install the videoconfiganimate custom nodes
i cant find it
it should be in the zip file with the workflows, its a python file
Shouldnt the example files and workflow do fine with a 5090? I keep getting CUDA OOM issues
你好,经过我的尝试,请把wanvideo model loader里的attention mode 改为sdpa 。断开Torch Compile节点。wan....textencode...节点的device改为gpu。wanvideo block swap第一行参数40改为10(仅针对5090的优化)请试一试!
Hello, after my attempts, please change the attention mode in the wanvideo model loader to sdpa. Disconnect the Torch Compile node. Change the device of the wan....textencode... node to gpu. Change the first parameter of wanvideo block swap from 40 to 10 (optimization only for 5090). Please try it!
Hi, I really like this workflow! Would it be possible to make a version that replaces the character in the reference video with the one from the reference image? Most of the ones I've found are awful at handling more than 16fps and are really short by default without a lot of extensions