IF YOU ARE WONDERING WHAT V2 IS OR YOU'RE HERE BECAUSE OF MISMATCHES AFTER UPDATING COMFY THE FIX IS IN!
UPDATE KJNODES AND COMFY!!!!!
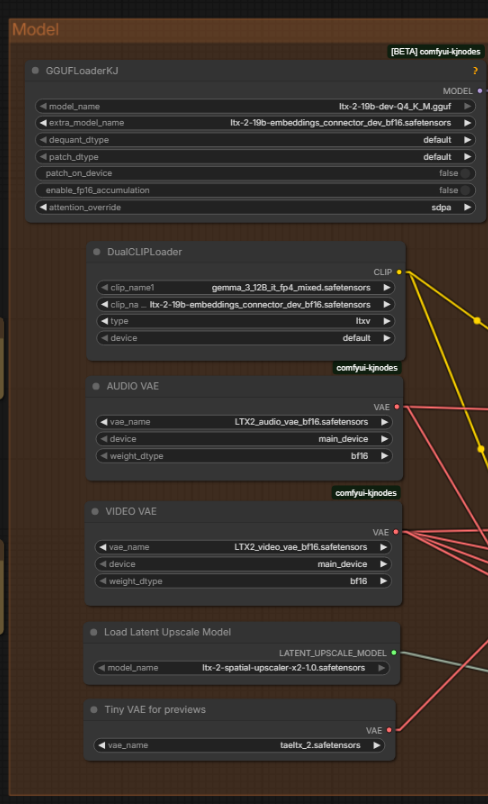
WE NOW PUT THE EMBEDDINGS INTO THE MODEL LOADER AND THE CLIP BUT IT IS ONLY LOADED ONCE! DOES NOT USE MORE MEMORY!
UPDATE KJNODES AND COMFY!!!!!
THIS WAS A NECESSARY CHANGE AFTER COMFY REORGANIZED WHERE THE EMBEDDING MODEL WOULD LOAD INTO. REQUIRED UPDATE!
PLEASE TAKE NOTE OF NEW DEV+LORA COMBO! WE NOW USE FP4 GEMMA TEXT ENCODER!!!! CHECK MODELS!!! WE NOW HAVE PREVIEWS USING TINY VAE!!! CHECK MODELS!!!! CHECK MODELS!!! DID I MENTION TO CHECK ALL YOUR MODELS!!! DO EEEEEEET!
WE ALSO HAVE THE LORAS SETUP CORRECTLY AND THERE ARE SOME FUN ONES OUT ALREADY! NODE IS READY TO GO FOR YOU!
5 TOTAL GGUF 12GB WORKFLOWS!
t2v, i2v, v2v extend, ta2v, ia2v!
Hello everyone! This workflow has come a long way since 1.0 actually. It doesn't seem like it when you first look but, boy this has been a project for me!
Here we have quite a few workflows for LTX-2 using GGUF and running on at least 12GB VRAM and 48GB system ram.
First we have your typical t2v and i2v workflows.
Second we now have two new audio driven workflows! ta2v which is supply a text prompt ONLY and some audio get a neat generated video with your audio! The other is an ia2v where you supply an image and an audio file and it lip-syncs up nicely. I tried to keep everything as simple as possible.
Then the one I like the most v2v extend. Feed ltx2 a few seconds of video, create a prompt to continue the video and watch the magic happen!!
I got done with the workflows, I now need to get all the info out there but I wanted to get these into the wild so everyone can start having fun with them!
I HAVE CREATED TWO ENHANCEMENT NODES FOR THE AUDIO!!
YOU WILL NOTICE 2 NEW NODES TOWARD THE END OF THE WORKFLOW FOR AUDIO ENHANCEMENT. CLICK THE BLUE LINK BELOW FOR MY GITHUB PAGE, INSTALLATION INSTRUCTIONS, AND USEAGE NOTES!
URABEWE-COMFYUI-AUDIOTOOLS
Description
FAQ
Comments (31)
Thanks for the V2 update. Now it's working again, I was wondering what happened.. lol.. I updated my Comfyui yesterday and this morning, I was unable to generate anything, it was showing some mismatch errors. Now, everything is fine.
my workflow seem not to load the connector. how did you solve that
@Rizzlord Try to update ComfyUI KJNodes and ComfyUI. You can still use the version 1 workflow, all you need to do is replace the 'Unet Loader GGUF' node with 'GGUFLoaderKJ' node. There's an option in that new node called 'extra_model_name', choose ltx-2-19b_embeddingd-connector_dev_bf16.safetensors.
@denjay5157 yep! Only difference is the loader node. I went with v2 to distinguish between the two loaders and I should probably archive the others at some point since they are obsolete at this point
can the v2v workflow be used to extend videos or is there a better way? I remember an extend workflow, but maybe it was for wan2.2 ... if you create a video with it, how many seconds are min/max in the input? tia
Great workflows! Thank you for your time efforts,
It would have been nice to have FLF2V workflow too!
audio nodes installation gives me this error - remote: Repository not found.
Same. Ever figure this out?
@beepperson947 never did figure that out but the ltx 2.3 workflows have been out for a while now and don't require those nodes anymore.
https://civitai.com/models/2443867
Thank you for this workflow!!
"Iwantallthethingsv2" works perfectly on my PC. I'm finally able to use the LTX-2, after trying so many other workflows. The results are amazing, and it's friday :)
@Urabewe Have you been able to make a pure v2v workflow? It seems that despite various forms of masking, only audio segments can be replaced entirely, the video remains exactly like the source in the empty latent -> i2vinplace -> mask method. Strength doesn't seem to make a lick of difference.0
Does this workflow not support vertical videos? If add a vertical image to generate an ia2v it fails
not the workflow because that's not how workflows...work... the model is not good at vertical but you can make it work. if it is failing to generate that's something else then.
Are you adjusting the height and width parameters of the "Resize Image" node next to the "Load Image" node? You want to adjust those numbers to the size you want your outcome to be. Changing your input image to another size won't change that because the node resizes your image to whatever dimensions are set in its parameters. For a vertical video you would want a height of 1280 and a width of 720 for example.
I noticed you have text encoder in the GGUFLoader. It will give error if people try to run it like that. I had to select none for it to work.
hey guys, everything downloaded from workflow, got error
CLIPLoader
Error while deserializing header: incomplete metadata, file not fully covered
i looks like problem in gemma_3_12B_it_fp4_mixed.safetensors
but dont know how fix it
seems like a bad download try deleting that and downloading again
Solid workflows. Thanks for putting these together. The image+audio-to-video workflow has gotten daily use from me for the past few weeks.
What does the Solid Mask node leading Set Latent Noise node under the audio group do? Does it apply a mask to the input audio so the generator can blend new audio with it?
I'm still kinda new to ComfyUI and mostly relying on pre-built workflows while I figure out all the nodes for myself.
This workflow uses custom nodes you haven't installed yet.
Installation Required
Install Required Float.
It's installed (or something that claims to be it) but still get this error. Does no good
LTX-2 Text Audio 2 Video GGUF 12GB.json
This workflow uses custom nodes you haven't installed yet.
Installation Required
Install RequiredUnknown
Node ID #164
This workflow uses custom nodes you haven't installed yet.
Installation Required
Install RequiredAudioNormalizeLUFS
Install RequiredAudioEnhancementNode
So it worked once (generated the deadpool example) then it crashed and burned again. So tired of figuring out these problems
@churchofthepoisonmind well this one is simple. I didn't want to switch the node for the float yet due to lots of people using the workflows. You got that one figured out?
Then the audio tools I have a few things I have to do and update the workflow with that. The audio nodes at the end, lufs and Normalize you can delete and it will work just fine. Those are to help the audio sound a little better. Will probably take them out and make a note about them later.
@Urabewe So I muted the audio nodes you mentioned (will try just deleting them, not holding my breath) and got this
edit: Deleting it, same result. Kaboom. Sorry, this is too much to figure out why it isn't working. No logic at all with this
Requested to load LTXAV
0 models unloaded.
loaded partially; 0.00 MB usable, 0.00 MB loaded, 13595.29 MB offloaded, 948.67 MB buffer reserved, lowvram patches: 0
100%|████████████████████████████████████████████████████████████████████████████████████| 8/8 [01:14<00:00, 9.26s/it]
0 models unloaded.
loaded partially; 0.00 MB usable, 0.00 MB loaded, 13595.29 MB offloaded, 948.67 MB buffer reserved, lowvram patches: 0
100%|████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:42<00:00, 14.13s/it]
Requested to load VideoVAE
0 models unloaded.
aimdo: src/model-vbar.c:198:ERROR:Could not reseve Virtual Address space for VBAR
!!! Exception during processing !!! VBAR allocation failed
Traceback (most recent call last):
File "D:\ComfyUI\ComfyUI\execution.py", line 524, in execute
output_data, output_ui, has_subgraph, has_pending_tasks = await get_output_data(prompt_id, unique_id, obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb, v3_data=v3_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\execution.py", line 333, in get_output_data
return_values = await asyncmap_node_over_list(prompt_id, unique_id, obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb, v3_data=v3_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\execution.py", line 307, in asyncmap_node_over_list
await process_inputs(input_dict, i)
File "D:\ComfyUI\ComfyUI\execution.py", line 295, in process_inputs
result = f(**inputs)
File "D:\ComfyUI\ComfyUI\nodes.py", line 348, in decode
images = vae.decode_tiled(samples["samples"], tile_x=tile_size // compression, tile_y=tile_size // compression, overlap=overlap // compression, tile_t=temporal_size, overlap_t=temporal_overlap)
File "D:\ComfyUI\ComfyUI\comfy\sd.py", line 982, in decode_tiled
model_management.load_models_gpu([self.patcher], memory_required=memory_used, force_full_load=self.disable_offload)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\comfy\model_management.py", line 755, in load_models_gpu
loaded_model.model_load(lowvram_model_memory, force_patch_weights=force_patch_weights)
~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\comfy\model_management.py", line 538, in model_load
self.model_use_more_vram(use_more_vram, force_patch_weights=force_patch_weights)
~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\comfy\model_management.py", line 568, in model_use_more_vram
return self.model.partially_load(self.device, extra_memory, force_patch_weights=force_patch_weights)
~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\comfy\model_patcher.py", line 1666, in partially_load
raise e
File "D:\ComfyUI\ComfyUI\comfy\model_patcher.py", line 1663, in partially_load
self.load(device_to, dirty=dirty)
~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\comfy\model_patcher.py", line 1507, in load
vbar = self._vbar_get(create=True)
File "D:\ComfyUI\ComfyUI\comfy\model_patcher.py", line 1455, in vbarget
vbar = comfy_aimdo.model_vbar.ModelVBAR(self.model_size() * 10, self.load_device.index)
File "D:\ComfyUI\python_embeded\Lib\site-packages\comfy_aimdo\model_vbar.py", line 40, in init
raise MemoryError("VBAR allocation failed")
MemoryError: VBAR allocation failed
Prompt executed in 00:14:29
When it rains it pours...
@churchofthepoisonmind oof yeah I'd have to sift through that. But, ltx 2.3 just dropped and I'll be making some workflows for that. Hopefully those will work for you. 2.3 is way better than 2.0
The generated video is blurry and full of pixelation.
WHY?
That's because it's LTX. Give Wan 2.2 a try, it's better.
V2V Error:
Input type (struct c10::BFloat16) and bias type (struct c10::Half) should be the same
I get this error in SamplerCustomAdvanced. I'm using pytorch 2.8.0+cu129 on my RTX3090 if that makes a difference. I did remove the text encoder in GGUFLoader like hid91herring074395 suggested to get past that point but it still stops at SampleCustomAdvanced. Python 3.13.6, latest ComfyUI version 0.16.3-1
10sec 720p on 12gb how long does it takes? with Q4
About 7 minutes. I would recommend grabbing the new ltx 2.3 workflows instead.
https://civitai.com/models/2443867?modelVersionId=2747788
This workflow is great, my only issue is I keep getting some sort of overlay at the end of the render. The Neg prompt has "overlay" in it. But still happening. Any suggestions?
If you're using the ltx2 workflows there are updated ones. This is the older workflows.
I'm testing out the ltx nag node from kijai right now seems to work well with getting those overlays to stop. I'll be updating the ltx 2.3 workflows soon to include previews,a bit better vram use and the nag node more than likely
Right now with the distill and cfg 1 you aren't using the negative at all. NAG will let you use negative prompts with the distull
@Urabewe Thank you for the update. That is good info to know.