

A real UnCLIP with working img2img
clear prompt / add image and click generate ;)








60% of the Time, It Works Every Time
Compatanble with ComfyUI
https://comfyanonymous.github.io/ComfyUI_examples/unclip/


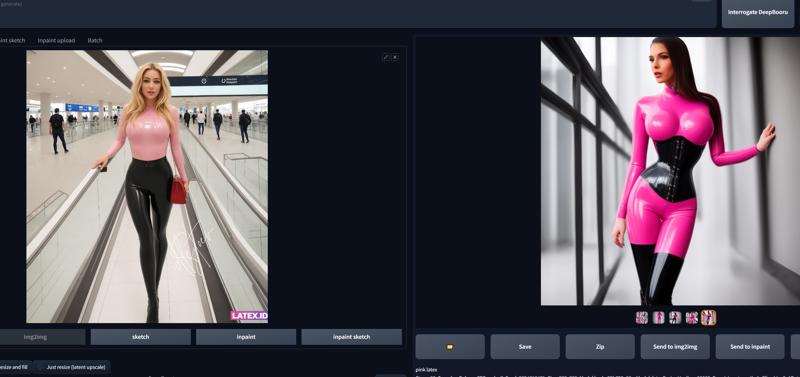
LATEX FUSION by Latex.ID
IT WILL NOT WORK directly!!!
Try with -h inference
https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion
Demo version trained FOR demonstration on a small dataset (sfw) on
https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip
Automatic support:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/8958
Final version in a few days 🤟 🥃
And here is the original result from SD
Text2image is kinda buggy )bad faces etc
THIS IS a preview version.
A 10k trained model is coming soon 🤟 🥃
Description
A proper UnCLIP version with img2img
FAQ
Comments (3)
I wonder if the bad ratings are because people think this is a regular model and don't know how to use unclip?
I tried using an unclip on anime arts and the result was terrible. But I don’t rate it because I still have hope that I can get an acceptable result.
Needs a lot more documentation and experimentation for this specific "Checkpoint" model (which people see as finetuned foundation model), and most adjustments/concepts can be handled through LoRA these days so it will make people slightly confused. There needs to be example used along side anime Checkpoints and LoRAs to be fully understood.
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.