Vid2vid Node Suite for ComfyUI
A node suite for ComfyUI that allows you to load image sequence and generate new image sequence with different styles or content.
Refer to Github Repository for installation and usage methods: https://github.com/sylym/comfy_vid2vid
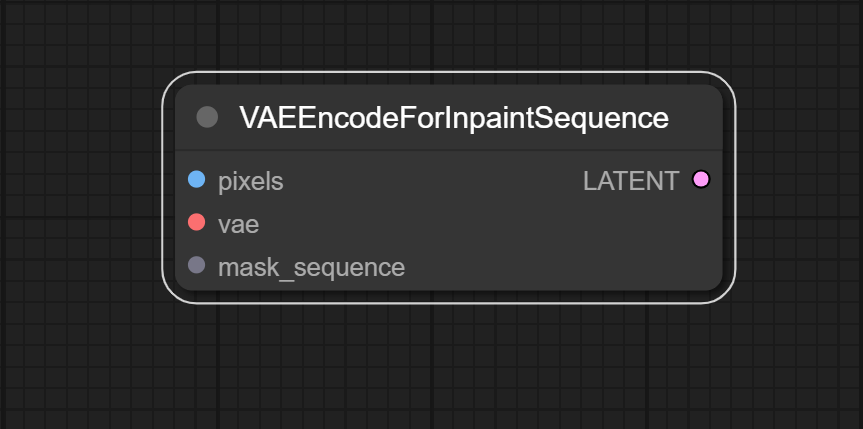
Description
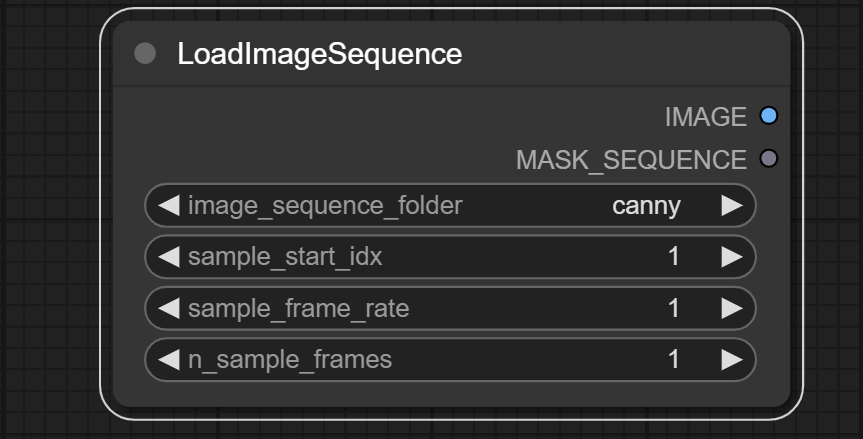
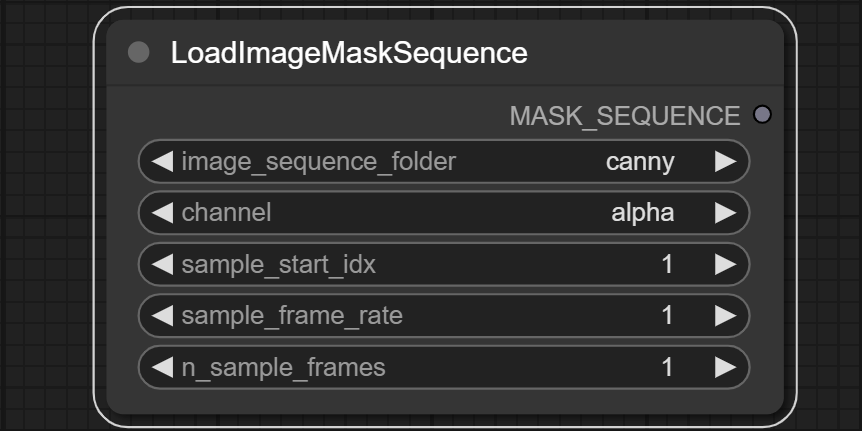
load_image_sequance_node
FAQ
Comments (6)
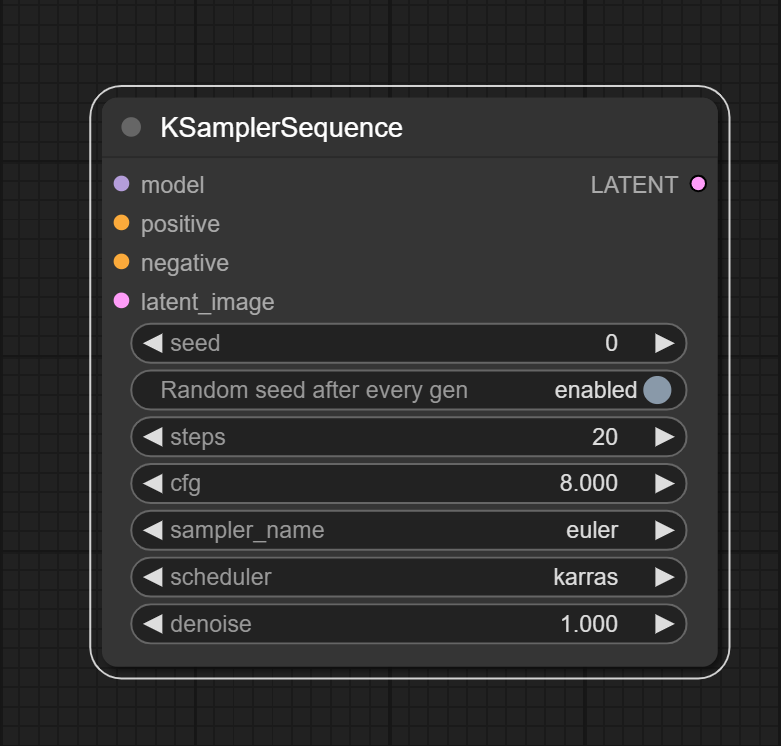
why do we need new ksampler
Because the ksampler in ComfyUI cannot handle mask sequences or accept custom noise inputs.
I tried this node, but was not successful in saving the final image sequence. Need a tutorial.
Do I have to use the same exact models as in the examples? Im getting this: Steps: 0%| | 0/100 [00:00<?, ?it/s]D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")
Traceback (most recent call last):
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 195, in execute
recursive_execute(self.server, prompt, self.outputs, x, extra_data, executed)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 58, in recursive_execute
recursive_execute(server, prompt, outputs, input_unique_id, extra_data, executed)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 58, in recursive_execute
recursive_execute(server, prompt, outputs, input_unique_id, extra_data, executed)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 58, in recursive_execute
recursive_execute(server, prompt, outputs, input_unique_id, extra_data, executed)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 67, in recursive_execute
outputs[unique_id] = getattr(obj, obj.FUNCTION)(**input_data_all)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\__init__.py", line 332, in train_unet
model_train = train(copy.deepcopy(model), noise_scheduler, samples, context[0][0].squeeze(0), device, max_train_steps=steps, seed=seed)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\train_tuneavideo.py", line 185, in train
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\utils\operations.py", line 495, in call
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\amp\autocast_mode.py", line 14, in decorate_autocast
return func(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\tuneavideo\models\unet.py", line 349, in forward
sample, res_samples = downsample_block(
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\tuneavideo\models\unet_blocks.py", line 301, in forward
hidden_states = torch.utils.checkpoint.checkpoint(
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\checkpoint.py", line 249, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\autograd\function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\checkpoint.py", line 107, in forward
outputs = run_function(*args)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\tuneavideo\models\unet_blocks.py", line 294, in custom_forward
return module(*inputs, return_dict=return_dict)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\tuneavideo\models\attention.py", line 111, in forward
hidden_states = block(
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfy_vid2vid\tuneavideo\models\attention.py", line 251, in forward
self.attn2(
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\diffusers\models\attention.py", line 619, in forward
key = self.to_k(encoder_hidden_states)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in callimpl
return forward_call(*args, **kwargs)
File "D:\AI\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling cublasGemmEx( handle, opa, opb, m, n, k, &falpha, a, CUDA_R_16F, lda, b, CUDA_R_16F, ldb, &fbeta, c, CUDA_R_16F, ldc, CUDA_R_32F, CUBLAS_GEMM_DFALT_TENSOR_OP)
ImportError: cannot import name 'model_lora_keys' from 'comfy.sd' and a few other errors
will wait for update
+1