



Update: By request and popular demand, now available in a PonyXL Variant.
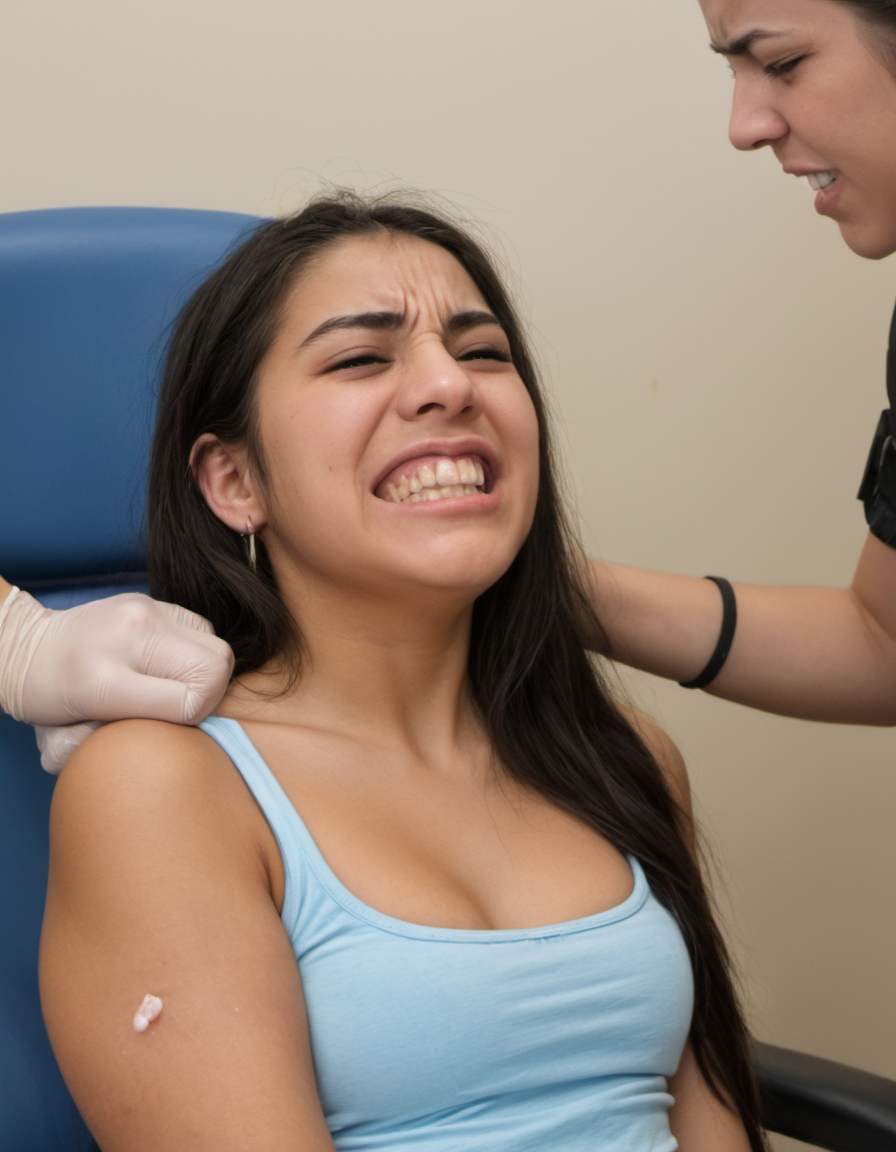
Adaptation of my SD15 grimacing LoRA to XL. First attempt at migrating the facial expression series, would love feedback on how well it works comparatively.
Pony Info:
Works really, really well with Hyper, but might need a little more tuning down on "realism" models. In particular you should be careful with embeddings or LoRA's which enhance the "photo" nature of the generations, since together they oversaturate pretty easily. It can be helpful to use adjacent words like clenched, or wincing, rather than the trigger word.
Normal animated pony models can mostly already make this expression, but this LoRA can help preserve it in scenes where there's a lot else going on. Using adjacent words (rather than the trigger) can help mitigate influence on style.
Starter Realistic Pony Prompt
photo of <subject>, clenching
Vanilla SDXL Info:
Starter Prompt
<subject>, with a pained grimace
Warning that I never cleaned up this dataset, so the images are a little horny by default unless you prompt them otherwise.
Description
FAQ
Comments (6)
The sample images are hilarious! See you're making a shift to XL!
Thanks! Definitely giving it a shot. The base model is very impressive, and after giving it a shot for some professional assets (SD15 really is super useless without LoRA's...), I realized it's now trainable with text encoder locally at 12gb.
How's your experience been? I'm still pretty mixed, honestly. Text encoding and prompting is much better, and when it works it works really well, but it has still felt really hard to "aim," and it doesn't feel like it does any better at, like, "generalizing," just better at encoding one more level. People also just seem notably worse at tuning meta parameters for it, probably just because the iteration loop is ~10x as long.
@thegipper LoRAs train exceedingly well on SDXL - the trouble for me is how long it takes on my 3060. I used runpod and vast.ai, but stopped since it was a cost, and I do this for fun.
@Desi_Cafe Yeah, it's a lot of time. I'm also on a 3060 and taking 1-3 hours to see if a tweak to a model made a difference is a real slog. Between that and 40 seconds to generate individual images to evaluate, it has kind of felt like a chore (lightning is really great, but it's tricky for training because there isn't much parity between the lightning and non-lightning versions of a model).
I've been hoping that one of the models I train will end up working so, so much better than SD15 that I'll see the magic and I'll feel worth it, but I haven't quite experienced that thus far.
I could only use 100 characters in my tip so let me elaborate. Great job. Couldn't get this expression no matter what and it's super useful in comic book images. Straining, pain, stuff like that. Unfortunately none of the models are good at bottom teeth which makes sense. Hundreds of millions of smiles in the base training I'm sure but those normally just show top teeth.
Glad to hear it's helpful! The bottom teeth situation is so funny to me. It was the original reason I started training expressions in 1.5 and it was surprising to me how much XL ended up with the exact same limitation.
Please do share anything you'd be comfortable with in the gallery or a review, I find it super helpful.