



















bigASP 🐍 v2.0
A photorealistic SDXL finetuned from base SDXL on over 6 MILLION high quality photos for 40 million training samples. Every photo was captioned using JoyCaption and tagged using JoyTag. This imbues bigASP 🐍 with the ability to understand a wide range of prompts and concepts, from short and simple to long and detailed, while generating high quality photographic results.
This is now the second version of bigASP 🐍. I'm excited to see how the community uses this model and to learn its strengths and weaknesses. Please share your gens and feedback!
Features
Both Natural Language and Tag based prompting: Version 2 now understands not only booru-style tags, but also natural language prompts, or any combination of the two!
SFW and NSFW: This version of bigASP 🐍 includes 2M SFW images and 4M NSFW images. Dress to impress? Or undress to impress? You decide.
Diversity: bigASP 🐍 is trained on an intentionally diverse dataset, so that it can handle generating all the colors of our beautiful species, in all shapes and sizes. Goodbye same-face!
Aspect ratio bucketing: Widescreen, square, portrait, bigASP 🐍 is ready to take it all.
High quality training data: Most of the training data consists of high quality, professional grade photos with resolutions well beyond SDXL's native resolution, all downloaded in their original quality with no additional compression. bigASP 🐍 won't miss a single pixel.
Large prompt support: Trained with support for up to 225 tokens in the prompt. It is BIG asp, after all.
(Optional) Aesthetic/quality score: Like version 1, this model understands quality scores to help improve generations, e.g. add
score_7_up, to the start of your prompt to guide the quality of generations. More details below.
What's New (Version 2)
Added natural language prompting, greatly expanding the ability to control the model, resolve a lot of complaints about v1, and lots, lots more concepts can now be understood by the model.
Over 3X more images. 6.7M images in version 2 versus 1.5M in version 1.
SFW support. I added 2M SFW images to the dataset, both so bigASP can be more useful as well as expanding its range of understanding. In my testing so far, bigASP is excellent at nature photography.
Longer training. Version 1 felt a bit undertrained. Version 2 was trained for 40M samples versus 30M in version 1. This seems to have tighten up the model quite a bit.
Score tags are now optional! They were randomly dropped during training, so the model will work just fine even when they aren't specified.
Updated quality model. I updated the model used to score the images, both to improve it slightly and to handle the new range of data. In my experience the range of "good" images is now much broader, starting from score_5. So you can be much more relaxed in what scores you prompt for and hopefully get even more variety in outputs than before.
More male focused data. It may come as a surprise to many, but nearly 50% of the world population is male! Kinda weird to have them so underrepresented in our models! Version 2 has added a good chunk more images focused on the male form. There's more work to be done here, but it's better than v1.
Recommended Settings
Sampler: DPM++ 2M SDE or DPM++ 3M SDE
Schedule: Kerras or Exponential. ⚠️ WARNING ⚠️ Normal schedule will cause garbage outputs.
Steps: 40
CFG: 2.0 or 3.0
Perturbed Attention Guidance (available in at least ComfyUI), can help sometimes so I recommend giving it a try. It is especially helpful for faces and more complex scenes. However it can easily overcook an image, so turn down CFG when using PAG.
⚠️ WARNING ⚠️ If you're coming from Version 1, this version has much lower recommended CFG settings.
Supported resolutions (with image count for reference):
832x1216: 2229287
1216x832: 2179902
832x1152: 762149
1152x896: 430643
896x1152: 198820
1344x768: 185089
768x1344: 145989
1024x1024: 102374
1152x832: 70110
1280x768: 58728
768x1280: 42345
896x1088: 40613
1344x704: 31708
704x1344: 31163
704x1472: 27365
960x1088: 26303
1088x896: 24592
1472x704: 17991
960x1024: 17886
1088x960: 17229
1536x640: 16485
1024x960: 15745
704x1408: 14188
1408x704: 12204
1600x640: 4835
1728x576: 4718
1664x576: 2999
640x1536: 1827
640x1600: 635
576x1664: 456
576x1728: 335Prompting
bigASP 🐍, as of version 2, was trained to support both detailed natural language prompts and booru-tag prompting. That means all of these kinds of prompting styles work:
A photograph of a cute puppy running through a field of flowers with the sun shining brightly in the background. Captured with depth of field to enhance the focus on the subject.Photo of a cute puppy, running through a field of flowers, bright sun in background, depth of fieldphoto (medium), cute puppy, running, field of flowers, bright sun, sun in background, depth_of_fieldIf you've used bigASP v1 in the past, all of those tags should still work! But now you can add natural language to help describe what you want in more words than just tags.
If you need some ideas for how to write prompts that bigASP understands well, try running some of your favorite images through JoyCaption: https://huggingface.co/spaces/fancyfeast/joy-caption-alpha-two bigASP v2 was trained using JoyCaption (Alpha Two) to generate short, medium, long, etc descriptive captions, so any of those JoyCaption settings will work well to help you out.
I also recommend checking out the metadata for any of the images in the gallery to get some ideas. I always upload my images with the ComfyUI workflow when possible.
Finally, scoring. bigASP 🐍 v2, like v1 and inspired by the incredible work of PonyDiffusion, was trained with "score tags". This means it understands things like score_8_up, which specify the quality of the image you want generated. All images in bigASP's dataset were scored from 0 to 9, with 0 completely excluded from training, and 9 being the best of the best. So when you write something like score_7_up at the beginning of your prompt, you're telling bigASP "I want an image that's at least a quality of 7."
Unlike v1, this version of bigASP does not require specifying a score tag in your prompt. If you don't, bigASP is free to generate across its wide range of qualities, so expect both good and bad! But I highly recommend putting a score tag of some kind at the beginning of your prompt, to help guide the model. I usually just use score_7_up, which guides towards generally good quality, while still giving bigASP some freedom. If you want only the best, score_9. If you want more variety, score_5_up. Hopefully that makes sense! You can specify multiple score tags if you want, but one is usually enough. And you can put lower scores in the negative to see if that helps. Something like score_1, score_2, score_3.
NOTE: If you use a score tag, it must be at the beginning of the prompt.
NOTE: If you want booru style tags in your prompt, don't forget that some tags use parenthesis, for example photo (medium). And many UI's use parenthesis for prompt weighting! So don't forget to escape the parenthesis if you're using something like ComfyUI or Auto1111, i.e. photo \(medium\).
Example prompts
SFW, chill sunset over a calm lake with a distant mountain range, soft clouds, and a lone sailboat.score_7_up, Photo of a woman with blonde hair, red lipstick, and a black necklace, sitting on a bed, masturbating, watermarkscore_8, A vibrant photo of a tropical beach scene, taken on a bright sunny day. The foreground features a wooden railing and lush green grass, with a large, twisted palm tree in the center-right. The background showcases a sandy beach with turquoise waters and a clear blue sky. The palm tree has long, spiky leaves that contrast with the smooth, curved trunk. The overall scene is peaceful and inviting, with a sense of warmth and relaxation.score_8_up, A captivating and surreal photograph of a cafe with neon lights shining down on a handsome man standing behind the counter. The man is wearing an apron and smiling warmly at the camera. The lighting is warm and glowing, with soft shadows adding depth and detail to the man. Highly detailed skin textures, muscular, cup of coffee, medium wide shot, taken with a Canon EOS.score_7_up, photo \(medium\), 1girl, spread legs, small breasts, puffy nipples, cumshot, shockedscore_7_up, photo (medium), long hair, standing, thighhighs, reddit, 1girl, r/asstastic, kitchen, dark skinscore_8_up, photo \(medium\), black shirt, pussy, long hair, spread legs, thighhighs, miniskirt, outsidePhoto of a blue 1960s Mercedes-Benz car, close-up, headlight, chrome accents, Arabic text on license plate, low qualityPrompting (Advanced)
Like version 1, this version of bigASP understands all of the tags that JoyTag uses. Some might find it useful to reference this list of tags seen during v2's training, including the number of times that tag occurs: https://gist.github.com/fpgaminer/0243de0d232a90dcae5e2f47d844f9bb
Of course, version 2 now understands more natural prompting, thanks to JoyCaption. That means there's a gold mine of new concepts that this version of bigASP 🐍 understands. Many people found the tag list from v1 to be helpful in exploring the model's capabilities. For natural language, a similar approach is to do "n-gram" analysis on the corpus of captions the model saw during training. Basically, this finds common combinations of "words". Here's that list, including the number of times each fragment of text occurs: https://gist.github.com/fpgaminer/26f4da885cc61bede13b3779b81ba300
The first column of the n-gram list is the number of "words" considered, from 1 up to 7. The second column is the text. The third column is the number of times that particular combination of words was seen (which might be higher than the number of images, since they can occur multiple times in a single caption). Note that "noun chunks" are counted as a single word in this analysis. Examples: "her right side", "his body", "water droplets". All of those are considered a single "word", since they represent a consolidated concept. So don't be surprised if the list above has "tattoo on her right side" listed as being 3 words. Also note that some punctuation might be missing from the extracted text fragments, due to the way the text was processed for this analysis.
Various sources can be mentioned, such as reddit, flickr, unsplash, instagram, etc. As well as specific subreddits (similar to v1).
Tags such as NSFW, SFW, and Suggestive, can help guide the content of the generations.
For the most part, bigASP 🐍 will not generate watermarks unless one is specifically mentioned. The trigger word is, coincidentally, watermark. Adding watermark to negatives might help avoid them even more, though in my testing they're quite rare for most prompts.
bigASP 🐍 can generate text that you specify using language like The person is holding a sign with the text "Happy Halloween" on it. You can prompt for text in various ways, but definitely put the text you want to appear on the image in quotes. That said, this is SDXL, so except to have to hammer a lot of gens to get good text. And the more complex the image, the less well SDXL will do with text. But it's a neat parlor trick for this old girl!
Some camera makes and models, as well as focal length, aperture, etc are understood by the model. Their effects are unknown. You can use a tag like DSLR to more generally guide the model towards "professional" photos, but beware that it will also tend to put a camera in the photo...
As mentioned in the list of features, bigASP 🐍 was trained with long prompt support. It was trained using the technique that NovelAI invented and documented graciously, and is the same technique that most generation UIs use when your prompt exceeds CLIP's maximum of 75 tokens. There's a good mix of caption lengths in the dataset, so any length from a few tokens up to 225 tokens should work well. With the usual caveats of this technique.
Limitations
No offset noise: Sorry, maybe next version.
No anime: This is a photo model through and through. Perhaps in a future version anime will be included to expand the model's concepts.
Faces/hands/feet: You know the deal.
VAE issues: SDXL's VAE sucks. We all know it. But nowhere is it more apparent than in photos. And because bigASP generates such high levels of detail, it really exposes the weaknesses of the VAE. Not much I can do about that.
No miracles: This is SDXL, so expect the usual. 1:24 ratio of good to meh gens, a good amount of body horror, etc. Some prompts will work well for no reason. Some will produce nightmares no matter how you tweak the prompt. Multiple characters is better in this version of bigASP compared to v1, but is still rough. Such is the way of these older architectures. I think bigASP is more or less at the limit of what can be done here now.
Training Details (Version 2)
All the nitty gritty of getting version 2 trained are documented here: https://civarchive.com/articles/8423
Training Details (Version 1)
Details on how the big SDXL finetunes were trained is scarce to say the least. So, I'm sharing all my details here to help the community.
bigASP was trained on about 1,440,000 photos, all with resolutions larger than their respective aspect ratio bucket. Each image is about 1MB on disk, making the database about 1TB per million images.
Every image goes through: the quality model to rate it from 0 to 9; JoyTag to tag it; OWLv2 with the prompt "a watermark" to detect watermarks in the images. I found OWLv2 to perform better than even a finetuned vision model, and it has the added benefit of providing bounding boxes for the watermarks. Accuracy is about 92%. While it wasn't done for this version, it's possible in the future that the bounding boxes could be used to do "loss masking" during training, which basically hides the watermarks from SD. For now, if a watermark is detect, a "watermark" tag is included in the training prompt.
Images with a score of 0 are dropped entirely. I did a lot of work specifically training the scoring model to put certain images down in this score bracket. You'd be surprised at how much junk comes through in datasets, and even a hint of them and really throw off training. Thumbnails, video preview images, ads, etc.
bigASP uses the same aspect ratios buckets that SDXL's paper defines. All images are bucketed into the bucket they best fit in while not being smaller than any dimension of that bucket when scaled down. So after scaling, images get randomly cropped. The original resolution and crop data is recorded alongside the VAE encoded image on disk for conditioning SDXL, and finally the latent is gzipped. I found gzip to provide a nice 30% space savings. This reduces the training dataset down to about 100GB per million images.
Training was done using a custom training script based off the diffusers library. I used a custom training script so that I could fully understand all the inner mechanics and implement any tweaks I wanted. Plus I had my training scripts from SD1.5 training, so it wasn't a huge leap. The downside is that a lot of time had to be spent debugging subtle issues that cropped up after several bugged runs. Those are all expensive mistakes. But, for me, mistakes are the cost of learning.
I think the training prompts are really important to the performance of the final model in actual usage. The custom Dataset class is responsible for doing a lot of heavy lifting when it comes to generating the training prompts. People prompt with everything from short prompts to long prompts, to prompts with all kinds of commas, underscores, typos, etc.
I pulled a large sample of AI images that included prompts to analyze the statistics of typical user prompts. The distribution of prompts followed a mostly normal distribution, with a mean of 32 tags and a std of 19.8. So my Dataset class reflects this. For every training sample, it picks a random integer in this distribution to determine how many tags it should use for this training sample. It shuffles the tags on the image and then truncates them to that number.
This means that during training the model sees everything from just "1girl" to a huge 224 token prompt! And thus, hopefully, learns to fill in the details for the user.
Certain tags, like watermark, are given priority and always included if present, so the model learns those tags strongly.
The tag alias list from danbooru is used to randomly mutate tags to synonyms so that bigASP understands all the different ways people might refer to a concept. Hopefully.
And, of course, the score tags. Just like Pony XL, bigASP encodes the score of a training sample as a range of tags of the form "score_X" and "score_X_up". However, to avoid the issues Pony XL ran into, only a random number of score tags are included in the training prompt. That way the model doesn't require "score_8, score_7, score_6," etc in the prompt to work correctly. It's already used to just a single, or a couple score tags being present.
10% of the time the prompt is dropped completely, being set to an empty string. UCG, you know the deal. N.B.!!! I noticed in Stability's training scripts, and even HuggingFace's scripts, that instead of setting the prompt to an empty string, they set it to "zero" in the embedded space. This is different from how SD1.5 was trained. And it's different from how most of the SD front-ends do inference on SD. My theory is that it can actually be a big problem if SDXL is trained with "zero" dropping instead of empty prompt dropping. That means that during inference, if you use an empty prompt, you're telling the model to move away not from the "average image", but away from only images that happened to have no caption during training. That doesn't sound right. So for bigASP I opt to train with empty prompt dropping.
Additionally, Stability's training scripts include dropping of SDXL's other conditionings: original_size, crop, and target_size. I didn't see this behavior present in kohyaa's scripts, so I didn't use it. I'm not entirely sure what benefit it would provide.
I made sure that during training, the model gets a variety of batched prompt lengths. What I mean is, the prompts themselves for each training sample are certainly different lengths, but they all have to be padded to the longest example in a batch. So it's important to ensure that the model still sees a variety of lengths even after batching, otherwise it might overfit and only work on a specific range of prompt lengths. A quick Python Notebook to scan the training batches helped to verify a good distribution: 25% of batches were 225 tokens, 66% were 150, and 9% were 75 tokens. Though in future runs I might try to balance this more.
The rest of the training process is fairly standard. I found min-snr loss to work best in my experiments. Pure fp16 training did not work for me, so I had to resort to mixed precision with the model in fp32. Since the latents are already encoded, the VAE doesn't need to be loaded, saving precious memory. For generating sample images during training, I use a separate machine which grabs the saved checkpoints and generates the sample images. Again, that saves memory and compute on the training machine.
The final run uses an effective batch size of 2048, no EMA, no offset noise, PyTorch's AMP with just float16 (not bfloat16), 1e-4 learning rate, AdamW, min-snr loss, 0.1 weight decay, cosine annealing with linear warmup for 100,000 training samples, 10% UCG rate, text encoder 1 training is enabled, text encoded 2 is kept frozen, min_snr_gamma=5, PyTorch GradScaler with an initial scaling of 65k, 0.9 beta1, 0.999 beta2, 1e-8 eps. Everything is initialized from SDXL 1.0.
A validation dataset of 2048 images is used. Validation is performed every 50,000 samples to ensure that the model is not overfitting and to help guide hyperparameter selection. To help compare runs with different loss functions, validation is always performed with the basic loss function, even if training is using e.g. min-snr. And a checkpoint is saved every 500,000 samples. I find that it's really only helpful to look at sample images every million steps, so that process is run on every other checkpoint.
A stable training loss is also logged (I use Wandb to monitor my runs). Stable training loss is calculated at the same time as validation loss (one after the other). It's basically like a validation pass, except instead of using the validation dataset, it uses the first 2048 images from the training dataset, and uses a fixed seed. This provides a, well, stable training loss. SD's training loss is incredibly noisy, so this metric provides a much better gauge of how training loss is progressing.
The batch size I use is quite large compared to the few values I've seen online for finetuning runs. But it's informed by my experience with training other models. Large batch size wins in the long run, but is worse in the short run, so its efficacy can be challenging to measure on small scale benchmarks. Hopefully it was a win here. Full runs on SDXL are far too expensive for much experimentation here. But one immediate benefit of a large batch size is that iteration speed is faster, since optimization and gradient sync happens less frequently.
Training was done on an 8xH100 sxm5 machine rented in the cloud. On this machine, iteration speed is about 70 images/s. That means the whole run took about 5 solid days of computing. A staggering number for a hobbyist like me. Please send hugs. I hurt.
Training being done in the cloud was a big motivator for the use of precomputed latents. Takes me about an hour to get the data over to the machine to begin training. Theoretically the code could be set up to start training immediately, as the training data is streamed in for the first pass. It takes even the 8xH100 four hours to work through a million images, so data can be streamed faster than it's training. That way the machine isn't sitting idle burning money.
One disadvantage of precomputed latents is, of course, the lack of regularization from varying the latents between epochs. The model still sees a very large variety of prompts between epochs, but it won't see different crops of images or variations in VAE sampling. In future runs what I might do is have my local GPUs re-encoding the latents constantly and streaming those updated latents to the cloud machine. That way the latents change every few epochs. I didn't detect any overfitting on this run, so it might not be a big deal either way.
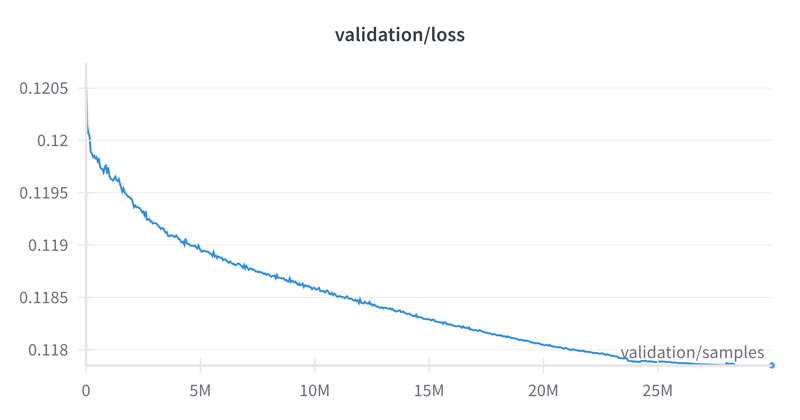
Finally, the loss curve. I noticed a rather large variance in the validation loss between different datasets, so it'll be hard for others to compare, but for what it's worth:
Description
FAQ
Comments (185)
fantastic model for realistic upscaling pony stuff and img2img, and probably more. shows a lot of promise when prompting, it understands a lot of concepts and styles other photoreal models really struggle with. Great work.
Thanks!
Good stuff
Here because I saw your thread on Reddit about how you fine tuned the model. Civitai is bad at letting users know of new models and honestly I wish they'd promote "trained' models over the over-abundance of merged ones. Can't wait to give this a whirl - thanks a lot!!
Your post about the trainning methods is a rlly interesting and valuable, thank you so much for share it and made it so detailed c:
Great model. I noticed a good understanding of prompts, it generates what is requested. Among the minor issues, I can highlight a strong dependence on the order of tags. If they are not specified in the correct order, the model will still catch the main idea, but the quality will drop significantly, resulting in broken eyes, mouth, and hands almost always. When attempting to generate complex scenes with multiple characters, it sometimes draws characters in an anime style, albeit broken, which is amusing since there was nothing about anime in the prompt. During the tests, I realized that this is also related to the incorrect order of tags. If you rearrange them properly, things get much better.
EDIT: just WOW. It can compete with Pony in terms of NSFW, which is an incredible result. It can do exactly the same thing, and in some aspects, it's even better. However, the instability of faces and hands ruins everything. I read in the limitations you described that you can't perform miracles, but it seems to me that this level of noise can be fixed, because right now, 9 out of 10 images have serious issues with this.
Thank you for taking the time to work with this model and give feedback. Feedback is so, so valuable and will help me improve! I'll see what I can do about the tag ordering. If you find any great examples of broken vs. not broken, please hit me up on discord delworth#1310
maybe i'm doing it wrong but all the models were distorted, had ugly faces, messed up mouths, had odd patchworked blurred areas.
I'm not having much luck with this model compared with mixed "real" pony models. Everything is super noisy, garbeled, and a mess.
There's a number of good looking examples here in the gallery, but they completely lack any meta data. It would help the community if folks weren't stingy with their generations and reveal the secret sauce to getting this model to work.
Also unfortunate that this model yet again requires "score" tags.
All metadata should be included in the images I posted for the "model" gallery, or whatever it's called, so hopefully that is a good starting point.
I tried your meta data example images and 8/10 renders it's a complete noisy mess. Occasionally a consistent well composed output is produced, but nothing like the example images that lack meta data in the gallery here.
@psspsspsspssspss Are you using karras schedule? I get a noisy mess if I use normal schedule, but karras works fine.
Try to use Perturbed-Attention-Guidance, it usually mitigates those problems for me.
I know you put a lot of money and effort into this model but for the life of me I can't get it to work. Even copying your prompts and settings my output looks so much worse. And for some reason it's incompatible with Kohya Hires.fix and only outputs a garbled mess. All my favorite prompts that work fine on every other photorealistic model fail miserably on this one.
Thank you for giving it a try. Let's see what's going wrong. What UI are you using to generate images? Auto, Comfy, Civit, etc.
@nutbutter Automatic1111
I did a fresh install of Automatic1111 and tested the model there. Here's a screenshot that shows all the settings, version numbers, model hash, etc so you can compare and see if anything is amiss: https://i.imgur.com/oOI3usr.jpeg I hope that helps!
{kind=link}
This model is INSANE in terms of variatons and "real" realism (non-model-plastic-looks without explicit prompting). I don't even use any score_x tags, because they limit model's creativity (imo). And most simple \ basic img2img workflow (using Align Your Steps + Perturbed Attention Guidance) with like 0.9+ denoise and some dumb short prompt already gives crazy good results. Can't wait to play and experiment with it more
HUGE THANK YOU for your work.
This model is really impressive in terms of output quality. It produces that real photo look instead of a photoshopped, heavily filtered photography style that most other "realistic" models have.
For anyone that would like to experiment: try to merge this model with another realistic model such as RealVisXL_V4 (merge UNET only, use CLIP from the other model). I've been testing with a merge ratio of 50/50 up to 80/20. In my observations the overall composition slightly improves without using tag based prompting.
What are you using to control the merging of the unet vs. clip?
@diffusiondudes You can do this in ComfyUI with the "ModelMergeSimple" node
@tshwwnbl Thanks, didn't know about that node!
The problem with this model is - you have to say score up whatever to make it do anything. The lower it goes, the worse the image looks as the default image resembles a picasso, and it doesn't follow the prompts.
Where as a score of 9 will give you a person that is posing for the camera, and it didn't follow the prompt. A girl walking in the mall, shouldn't be a girl in a chair sitting.
Likewise it doesn't really handle anything else and due to the score system, you have to add the score per each prompt making it hard to test for anything else.
So can you update this so we don't need a score? Show the best, and we can ask for the worse?
This is genuinely the most capable model on this site right now. Using JoyTag and quality scores was a very smart move and the output turned out to be excellent. I'm really looking forward to further updates to this, it has some huge potential. Civitai really needs some work on the discoverability of new releases, because this one should be blowing up.
That's... wow. This is the real breakthrough. Big time. First real p*rn model, if you know what I mean. Only one drawback. It doesn't know celebrities well, compared to SDXL.
Worst thing I have ever seen, sorry dude to tell that, but something must have gotten very wrong. I'm sure you manage to produce some hot images on a very small path of prompting. but it does not work at all for normal simple prompts coming from a simple mind. All I got was crap. I'm still impressed by the work you spend and all the time. But the result does not show this at all.
If you say so, then give examples of what you used, why, how, what prompt, what you expected, and what you got. Otherwise, your information right now does not provide any understanding of where the problem is and how it could be fixed.
Thank you for taking the time to try this new model. I'm sorry it did not work well for you! Based on your feedback, feedback from others, and my own testing, it looks like there is a soft bug in this version of the model. I have updated the model description to help. The model's quality tends to drop severely if prompted with natural language or any words outside of its vocabulary. The model description now includes the list of nearly 6000 words it understands. It is also important to note that this model was trained strictly on photos, so its performance on other prompted mediums like "oil painting" and "digital art" will be much worse. Future versions will work to correct the prompting bug, and I hope to integrate more mediums into the training. Thank you again, and I hope this helps.
@GromForever I get your point, I did add images to the samples below, they come with all the meta so it was already there when you added your comment ;)
@nutbutter You welcome. If youre interested you can PM me and I can show you something that could help testing your models in the future, so that you don't get hit by surprise. I will not use your space here for promotion to keep it just your place.
This is by far, and i mean by far the best SDXL nsfw model out there. Nothing come close to it interms of realism and NSFW combined. Not a single SDXL model out there can do this right now without merging with some kind of pony base and lose out some degree of realism, they all have the same issue when you start adding nsfw prompts on top of a refined base imagine BUT this one dosen't it was trained from scratch for it instead of merging over a a dozen times. The problem with people can't get this model to work is they are using Forge or Fooocus with chatgpt on top with a bunch of pre-define settings and then try to throw in Turbo/LCM. If you go back to A1111 or comfy with a really detailed workflow and prompt it with natural language first, then throw in a bunch of tags for style and details afterward you will get some insane highly realistic NSFW output. The other thing is don't throw in a bunch of loras i actually dosen't work well with them. But this model in itself is like a freaking pony model (minus some extremely extremely hardcore dark stuff), you can prompt most of the NSFW without lora.
You just need better than average hardwares and run it on A1111 or Comfy with a very detailed workflow and tweak the settings. I recommand 5-7cfg with 40 steps and a 20steps hi-res on R-ESRGAN 4x+ using Restart/DPM++ 3M SDE
There is no substantial difference between A1111 and Forge except for the memory optimizations, and obviously, that Forge is outdated.
This is insanly good, by far the best porn capabilities. It's also the best model at rendering feet and hand.
Can anyone advise the optimal settings for image to image??
Great model! The look is incredible, second to none! Prompting has issues with anatomy, composition, hands, and faces. Especially the anatomy and composition. It puts people in the air, impossible places, and with extra limbs and mistaken anatomy. It reminds me a bit of SD1.5 in that it has similar issues with hands and anatomy.
You must be doing something wrong! Faces are not perfect but what kind of issues do you have with hands? In my experience this is by far the best model at generating anatomically correct hands (also feet).
This model has the potential to be the pony of Photoreal Nsfw models, one can get absolutely amazing onlyfans/reddit-esque gens with this model. Unfortunately this model, in my experiece at least, is fairly difficult to use compared to other models as it suffers from undertrainining (like the creator has said), leading to weird artifacts, bad anatomy, and inconsistent results. I needed to add heavy negative weights to stop the model from producing borderline abstract garabage much of the time. Without a proper prompt, maybe 1/5 gens will be okay, and with a proper prompt 1/3 will be good.
Surprisingly though, contrary to the creators words, this model seems to work well with photoreal loras trained on pony, at least with the ones ive personally made. I will make a seperate image post with images that i got using my loras alongside Big Asp, the ones ive already posted are without any loras. It should be noted that i did use adetailer on all my gens, and i would recommended everyone else does too. That being said, if i could rate this model out of 5 stars, id give it a 3.5 - Massive potential, but currently rough around the edges. I hope the creator of this model will give this model some more training because i believe he has truly made something great here, something that could become absolutely amazing!
Thank you for the detailed review! I always appreciate feedback to help. It helps guide the changes for future versions. And thank you for sharing your gens and experimenting with loras.
You should seriously enable Perturbed Attention Guidance with this model, it has an amazing effect on the output quality.
@nutbutter I think this recommendation should be provided upfront in the model page.
Also replacing CLIP encoder with the base SDXL version or another photo-real model works well for prompting with a more natural language, it seems to me that the CLIP embedding space is highly compatible.
@tshwwnbl Never heard of that. Ill look into it, but i dont think that is available on tensor art
@Spartacus98 You have to run it locally in ComfyUI or any other tool that allows generating images on your computer. There are custom nodes / extensions that implement that feature (look it up)
@Spartacus98 tensor art lets you open "ComfyFlow" workspace, which is ComfyUI workspace, and it has PAG built in under the PerturbedAttentionGuidance node (I haven't used it; just took a quick look on tensor art for ya is all)
@tshwwnbl tried this and my gens went from extremely mid to unbelievably high quality immediately. 11/10 comment.
@gygaxinor4657 Seconded! Never really used comfy much before, but tried a workflow with PAG and the gens are significantly better and anatomy far more consistent.
And here I was thinking "Pony Realism 2.1" was good... The prompting is difficult but oh man does it pay off!!
Tnx for this great model! Any ETA on the next version?
Gratitude!
If you’d like to save a little bit of compute next time, use Zstandard instead of gzip to compress your latents. It is much faster and obtains a better compression ratio.
Hands down the best kitchens. Also some other things. But just look at the coherency of those kitchens! My, my.
try to merge with sdxxxl 50/50
or with Acorn Is Boning XL
As a very amatuer fine-tuner, sharing not just what you did, but how you did it, is very appreciated. I can't thank you enough for the insight. Would you be willing to consider sharing your custom scoring model?
Thank you for the kind words. I shared the scripts and notebooks for training the quality model: https://github.com/fpgaminer/bigasp-training/tree/main/quality-arena
The code is quite raw and rough, so beware. As for the quality model itself, I didn't feel it was good enough to be worth sharing. It was thrown together just to be good enough to get the first version of bigASP done. But I'm happy to share it if anyone really wants it.
insane quality
thank you so much for making the tag list public, I use it all the time now, not only for your checkpoint but also for others (mostly pony tbh)! big shoutout <3
For Pony models, you can search derpibooru.org. I believe that's more canonical for Pony.
The use of PAG is really valuable with this model. Also low CFG. I have found PAG 1.5-2.0 and CFG 3.0-5.0 work well for me. My earlier examples in the model gallery were made without the benefit of this wisdom and I believe their dullness relative to my more recent contributions speaks for itself.
Thanks for your hint @foxfarmer. You are right about both PAG and the CFG range. I get the best results with CFG 4.0. For PAG, the whole range between 0.5-3.0 is decent but I like 2.5 best. The result of PAG is slightly better than without PAG, there are slightly less glitches. First, I was appalled to find out that using PAG doubles the generation time. However, there is a clever trick: Limit the use of PAG to only the first two steps or so. I have it ending at step 2 and it is almost the same as if it ran until the last step. The performance hit only applies to those first two steps and after that the speed returns to normal.
@UltraVixens There's no free lunch, eh? =-) My PAG+CFG iterations per second is "only" cut to 2/3 CFG-only but ... yeah, wow! I had not noticed that. I will explore whether I feel I can save some time by omitting it in later steps. Thanks!
You say you end at step 2. That's 2 of how many, if I may inquire?
@foxfarmer No matter if I have 40, 60 or 80 steps, I would stop PAG after step 2. 80 steps or 60 steps are not always better than 40 steps but more often than not they look slightly more natural in terms of anatomy.
For a fan of large natural breasts, this is a revelation. SDXL checkpoints and even the more photorealistic Pony checkpoints never felt natural and photorealistic enough, not even with LORAs of 'well-equipped' adult models. bigASP delivers on all fronts without even needing a LORA to achieve the dream shape and size for the breasts. SDXL and Pony LORAs can be used but their effect is different from what you may expect and the faces never get very close to the LORA subject. Nevertheless, you can mix NSFW, non-NSFW and style LORAs to achieve interesting effects and variation and to further enhance the photorealism and the anatomy which are great by their own right. The checkpoint also responds very well to Dynamic Thresholding and to CADS. A drawback is that the backgrounds are not very exciting, and there are sometimes issues with hands. This is now my new favorite checkpoint and I am very much looking forward to further versions. Keep up the great work!
I have to add a few things I have found out since I left the above comment:
- Use PAG and a lowish CFG range as suggested by foxfarmer in the comments
- I like to start with another NSFW checkpoint handling the first 3 steps of the image generation and then switching to bigASP (using the Refiner feature).
- Ignore Dynamic Thresholding, it is usable but it is not better than a standard photo with CFG 4.0. Moreover using it with PAG ruins the image.
- I have found CADS working okay with 0.6 to 0.9 or 0.75 to 0.95 ranges, the strength of 0.9 is pretty good. The image quality is about the same as without CADS. Use CADS only when you want even more variation than what bigASP normally provides and don't need strict prompt adherence for the background for example.
What is PAG and CADS?
@AnNye0ng PAG stands for Perturbed Attention Guidance, which is available for A1111 in an extension called "sd-webui-incantations". Look at its Github page for installation instructions. I strongly advise to use PAG as it clearly improves the image quality. CADS is another extension that you can install for A1111. I think it might be available in the standard extensions index of A1111. CADS does not add to image quality but creates more diversity. I must say though that bigASP produces quite diverse photos by itself even without CADS.
One tip for using this model:
The score tags seem to limit the model's output severely. You tend to get much better prompt adherence (or rather, tag adherence) if you leave them out.
Then, you can img2img or upscale with the score tags in the prompt, and this will give you a sharper and more detailed result.
Edit: I retract this advice -- see comment from @foxfarmer
I did a bunch of grids with various combinations of score_1 and score_2 in the negative and found it made no difference, so I definitely agree that they aren't useful there.
However...
I have previously found that "photo \(medium\)" in the positive makes a beneficial difference.
And now, in response to this comment, I decided to do a bunch of A/B comparisons with and without "score_9, score_8_up" at the beginning of the positive for my base-resolution generation. Having now looked at 50 pairs, I have to conclude that you are mistaken: Prompt adherence doesn't change for me (both generations are quite similar) but quality definitely improves with the score tags.
That said, who knows whether this holds true with other settings. I'm using fairly low CFG (5) and PAG (1.5).
@foxfarmer I think you're right. I think my advice is only valid for more obscure tags in which the model doesn't have much training on the tags. But even in those cases, you're probably better off getting decent output that isn't quite what you asked for, rather than horrible output that's slightly more like what you asked for (but still not really).
@foxfarmer Ok at the end of the day what should we put in the prompt pls.
@zGenMedia I personally like "score_5_up" at the beginning -- it gives the photos an imperfect/amateurish quality that makes them seem more realistic (to my eyes). I do think "score_1, score_2, score_3" is important in the negative. Beyond that, @foxfarmer is right -- the actual content of the generation doesn't change much with different score tags.
@zGenMedia @zGenMedia "score_9, score_8_up, photo \(medium\)," is what I use. (In fact, I follow that with "photograph" but I don't have any data to say that it is helpful.) I don't use any boilerplate in my bigASP negatives.
Score tags definitely alter and restrict the output somewhat, but without score tags in the positive, the output is vastly worse. If it lacks both score tags AND photo medium, the output is often aweful. Fingers crossed for a v2.
I want to add that this model generates absolutely wonderful facial expressions.
This is the best nsfw generative AI model that exists so far. Congrats.
Thanks!
what exactly setting you use like clipskip , sampler ..so on ?
This model is fucking insane for "low quality" realistic photos. The same prompt will produce completely different results (that follow the prompt) with different seeds, which is really good for actually getting something interesting.
I tend to just generate like 20 images with no negatives or minimal negatives, and 3-4 positive tags, and then find one result that seems to be doing vaguely what I want, then start adding tags, loras, and tweaking.
I can't get this model to produce pretty faces. The gallery doesn't have any acceptable examples to reference. Loras and embeddings don't help. I like the concept, though, and I'm looking forward to V2.
Use adetailer
I have the same problem, and when trying to inpaint with it to fix faces, it gives less than satisfying results... :( Otherwise it is the best model on here on par with pony
This is just what a model where all the data is actually real photographs of various quality looks like lol, the majority of other "realistic" XL checkpoints are full of "realistic" data that was actually generated by other models.
I had to give up, tried a bunch of different prompts from the examples, adetailer, highrez, used the same seeds, same sampler/steps... all came out low qual and nothing like the examples
Truly amazing when working from the tag list. Have yet to try making a lora for it though.
Request: do you have a list of tags with frequency? I'm curious to feed it to a LLM to come up with prompts
Thanks a ton
I'll try to generate a frequency list when I get a chance.
@nutbutter sweet, thanks!
Where's the link to send you tips?
🤷♂️
Great realism! Any chance of future compatibility with LCM?
Ok for real. How do you claim long prompt support yet your position_embedding weight is still same size i.e. no decay training on positional weights so they are still 77 and active. If you train model above the token limit you need to implement either custom layer for positional embedding which would mean you would also have to supply custom config which you haven't or you need to train the model with decay on the positional embedding weight and instruct on how to unlock over 75 token limit so user can take advantage of it. You basically just overfit the model with jibberish
Yikes
This is REAL realism. No smooth cartoony skin like the rest of the models out there. With enough steps and hires fixes, you couldn't tell if they are AI or not
word
It’s amazing. Thank you. You put a lot of sweat and money into this.
Can this model be used for a base model to train Lora or checkpoints?
Also, can you provide a link to the base model from which you do this one?
This was trained off base SDXL.
The defaults that CivitAI's online trainer uses when you choose Pony seem to work very well for BigASP also, I guess they're just good in general for training Loras on heavy finetunes of Base SDXL
I'm training an anime style Lora for this ATM on the same dataset as an existing Pony one of mine, first epoch is already looking pretty good. Doesn't introduce any new concepts or specific anime characters or anything, just changes the appearance of stuff bigASP already knows about (as was the case with my Pony version of it).
Awesome, I look forward to seeing the result!
@nutbutter out now, came out better than I was expecting overall: https://civitai.com/models/570136?modelVersionId=635476
@diffusionfanatic1173 Very cool, thank you for sharing :)
@nutbutter Thanks! I'm gonna do a kindof 3D one too called something like "Enhanced Unrealistic Concepts For bigASP", with probably a source_render tag, to add like better monsters and aliens and demons and stuff like that.
@diffusionfanatic1173 Very nice
V2 out: https://civitai.com/models/578869?modelVersionId=652508
Amazing work, thank you. Waiting for v2.
Am I missing something or it can’t do distant full body shots well?
Thank you :) For distant full body shots you can try the full body tag, and maybe putting close-up in the negative. But there's no tag for specifically "distant" in v1, so it might be hard to prompt for specifically. I tried a few gens like that and didn't get a distant shot, but it did do medium distance at least. I'll try to improve that in future versions.
Oh, looks like there is a "wide shot" tag, but not a lot of examples in the training data for it. I tried a few gens and it pushes the camera a little further out, but not much.
Thank you, Im gonna try this ☺️
Kinda hard to do gay porn with it
Thank you for the feedback! (civit never notified me of this comment...) v1 should be doing decently at solo male performers, but yeah I think anything more complex than that is not well represented in the current dataset. I'll get more male focused and gay focused content into the dataset for the next version :) If there's anything specific, let me know; I'm always happy to get suggestions as I prepare for the next version.
@nutbutter Thank you for listening to my complaint, I will send some buzz your way!
There may be a faulty assumption in this question, but have you experimented with training in such a way that the weights decay toward the base model instead of zero? Just curious since I have a version of ASimilarityCalculatior [sic] modified for SDXL which suggests that bigASP may be about as far from base SDXL as Pony is, and your listed weight decay value is surprisingly high to me.
Regardless, it's clearly a capable model and I very much appreciate that you've shared the tag list and all the development details, in particular tiny CLIP-based ranking models was a revelation for me.
This model took me some time to learn its quirks, but it works really well once you get it down.
care to elaborate on what you mean by 'quirks' ?
@I_dont_want_karma_ The settings the model prefers, using good tags, etc. I found that using PAG set at 0.9 helped a lot. Also using 3.5 CFG with dpmpp_3m_sde_gpu sampler like a lot of the pictures in the gallery got the most realistic output, and I think using a high step count (50+) is a must. On top of that, a lot of the tags in the tag list were a hit or miss for me. In general the tags with a lower count in the training set has little to no effect on the final output and tags with a higher count had too much of an effect if that makes sense.
@yolandarenee11189 I like to use UniPC with this. It gives better details, I feel like
@yolandarenee11189 Followed you but what is PAG? everything else I got. Just do not know that term. Sorry English isn't my first language.
@zGenMedia https://github.com/pamparamm/sd-perturbed-attention Perturbed Attenction Guidance helps with prompt accuracy and is good even without any prompts (e.g. in aDetailer or ControlNet)
@yolandarenee11189 I disagree that you need 50+ steps. I feel like the output doesn't get much better after 25 steps -- it just gets different. Sometimes you need more steps if you're plugging in a bunch of addons like IPAdapter or Controlnets. But 25 is usually enough.
I can't get it working correctly with ControlNet depth. Am I missing something??
I'm using it without an issue, using depthanything + controlnet depth so i don't think it's the model.
I can't use any control net, i get a good image in the background but a blurry mess in the forefront, like theres a fiber or something in front of a camera before the shot
This models is great, among the best seen yet, maybe the best, but did you really have to nuke the concept of age entirely? It seems like you can't say you want your secretary to be 32 years old, or your teacher to be 45 years old, because "year old" produces an old bald man that was deliberately overtrained to prevent anyone from using the model to generate psuedo-CSAM.
Honestly. Did you really need to do that? Can you un-deface the model or at least release it somewhere so I can get less than a 20 year age window for my extremely particular middle-age women fantasies?
If you actually care about getting what you want (god forbid if you happen to care about not being a dickish child) here is an unsolicited life lesson for you my boy - "honey catches more flies than vinegar". Don't worry, I'm sure that whatever gratification your little temper tantrum gave you outweighs the months of delectable meat tenderizing you could have gotten out of all those sweet mommies.
Your response is self-defeating (user name checks out etc etc) and confusing enough that it makes me wonder if it's actually the other side of the age spectrum that you are concerned about (not to mention the interesting way of framing your complaint). We both know that this guy didn't go out of his way to "nuke the concept of age entirely", much less to specifically take away your right to self-abuse to MILFs.
But you know what? And this I want to say for the other comments I've seen along these lines on this site - if I were a goddamn hero enough to freely release a model like this into the wilds and attach myself to it in any way whatsoever, you bet your ass I would utterly erase every age except maybe 'thirty two years old' on the dot.
I would make the thing come out looking like Tencent Stable Diffusion 4 Family Game Night Edition. You'd be lucky to tell one nightmare mass of flesh and eyeballs apart from another, much less bitch about it's age. JK, i still wouldn't even risk the smallest ounce of blowback from giving the mouth-breathing NAMBLA apologists the 'freedom' they value so dearly with their 'high ideals*' to exercise their 'creativity'. What is even the "upside" of not eliminating that possibility from a damned porn model? Thumbs-up emojis from
*they were really going through some serious philiosophical explorations in the 7th grade when the word 'thought crime' showed up on an exam in their honors (that's right) English class. they didn't actually read the book (nuance,blegh), but it just blew their small, sad world dude. sadly, they soon became addicted to (mmo,4chan,porn,etc), and their worldview never really developed any further. maybe the words got a little bigger
I forgot why I bothered starting this comment, and I also forgot how to turn italics off (thought it was basic markdown??). So I want to acknowledge I take a partial L for wasting precious minutes on this, even if I'm drunk and sleep deprieved. I've just seen shit like this comment multiple times. I'm just going to consider it a public journal entry.
Thank you BigASP author. I think you're a damned hero. (Now italics is off somehow..) Hope my comment isnt shitting up your page even more. I will say that getting some women just a little bit older would indeed make this thing even better.
Don't get me wrong though, OP is a clown
@bakersonjim46154 Nobody reading all that and nobody's being saved or helped by the censorship.
If you foil the perverts from making fake stuff they'll just go look at real stuff. Real talk, fam. Every second they spend amusing themselves with AI is a second they aren't amusing themselves with the real thing, and that's a good thing. So what or who are you actually helping by censoring checkpoints? I just want to be more specific than middle aged or mature. It would have been enough just to not train it on abuse material.
This checkpoint is great, but the author removed all celebs apparently as well. Any way to reverse this? All it gives me is someone that looks vaguely like so-and-so. I love the checkpoint, but I'm guessing the person who trained it was probably shocked by their tests and afraid that if they released the original version they might fall under scrutiny. That's unfortunate. Censorship benefits nobody.
@Sisyphuse Yeah I had a weird moment with that essay there. Honestly, I don't have a strong opinion about censorship, so I should probably leave that debate for those who are invested in that issue. I can understand the argument you are making, kind of like harm reduction policies towards addictive substances (and I can say for sure that I support those).
If it were the definitely case that it prevents real world harm, I'd agree. Who knows - transparently, the issue gives me too much personal ick to really think about too much. Admittedly, that is probably the same reason that policy towards drugs has been so shitty for so long. Historically, same with eace, women, etc. So I'll do what I think others who know they can't be objective should do and shut my mouth on it.
That being said - I'll summarize my original comment like this (i don't even want to read it) - person who made this model is a stud, and I don't fault them one bit if they didn't want to expose themselves to risk of any sort (legal, or even some hypothetical inconveinence) as they freely publish something they likely spent a lot of time and even perhaps $ on. I don't see much or any personal incentive to do so. A porn model doesn't seem to get you clout in the community IMO (any kind that matters), much less potential career gains (unless they want to literally work in porn AI or encounter some open-minded biz world types). It takes an idealist I guess. So he certainly didn't have to release it, but he did. So, IMO, appropriate comment involves kowtowing
He trained it using a tagger that has no concept of specific ages, the millions of images wore down whatever understanding base SDXL had of that I guess, it probably wasn't intentional (or rather it almost certainly wasn't lol). It's a joke to suggest that this model is "censored", it's not any less capable of producing suspicious content than any other model that can actually do porn that has ever existed (going all the way back to the SD 1.5 days).
The cat was out of the bag on that sort of thing on day one, almost everyone is complicit to some extent, and there's absolutely nothing anyone can do about it, even frickin' Dreamshaper can and would quite happily mix the concepts of nudity and any of the underage characters it is aware of if you asked it to.
I read this comment and said "really?". I loaded up bigasp in comfy and within 2 minutes was generating images of elderly grandma's taking it up the ass. There's no doubt that BigAsp isn't able to do somethings, but what it does, it does better than any model out there, and it understands age fine. I've never had a problem getting milfs.
I really hope you make a V2 with ameliorations. it's really good but it's stubborn asf too lol. This is THE most "candid" models ever. Not even close. This is ACTUAL realism. Wrinkles, makeup smears, skin blemishes, it's actually insane.
Can't wait to see if v2 ever comes.
Just want to share this to the community.
Take time looking up Known Tags
Amatuer, AsiansGoneWild, Boobies, etc
My favorite is shiny_skin
Each of them improves the output and quality depending what you are prompting.
Model is heavily biased when it comes to solo. Meaning if you want couples you would need to put in the right tags ex: GWCouples
This is my current setup I am using Automatic1111:
Positive Tags:
score_8_up, photo \(medium\), [insert known tag here], 1girl, solo, lips nose, shiny_skin, [add whatever else here]
Negative Tags:
score_1, score_2, score_3, 3d, anime
I found that adding these two would improve the quality, but at the cost of adding words in your gen.
watermark, web address
I am looking forward for future updates.
this is the biggest breakthrough in model quality since Pony. Truly incredible work and I'll be eagerly awaiting v2. I'll gladly donate to the cause if you have a link
I'll join the cause if there's a link 💯
Did anyone manage to merge this with another model? Every time I merge it, the new checkpoint applies a grey filter on every image.
I've had this happen when merging checkpoints. make sure you're using the SDXL vae when you generate your images with your merged model. fixes the grayness and the weird smatters of dots.
...or you cam bake in the VAE when merging
this model is honestly unmatched at inpainting. it's incredible how realistic the output comes out (at least most of the time)
hi, how can you make it perform inpainting?
I was excited to try this out from all the hype but this model is unresponsive and produces many cursed images. Using contronet was also a no-go since it doesn't understand my prompts anyway.
My only feedback is that I followed instructions and got bad results. I stuck with danbooru tags and sometimes got a good image but it's super restrictive.
Make sure you're only using tags from the lists linked to on this page. Make sure your UI isn't doing any accentuation on your prompts. And make sure you're using DPM++ 3M SDE Karras or one of the other Sampler/Scheduler combos recommended.
@Gremble I tried and its like pulling teeth to get something basic as a blowjob lol. Mind sharing some prompt examples? Lustify seems better IMO
@AverageAndAbove try this:
score_7_up, photo_\(medium\), pov, 1girl, blowjob
If that doesn't work, then try photo_(medium) instead
Same here, getting garbage results. i can't generate low res for hires. For example want to generate 768x512 but then the results is cursed as you said. Check out the pics i posted, it's ridicilous.
@chrisss1 The list of supported resolutions is provided in the model's description; it's the same as base SDXL.
Found this by "accident" and the results are kind of nice and fresh. Its now in my top3!
Thanks for the great work!
Any tip how to avoid women or femboys?
I added 1boy, male focus etc...
Negative prompt a lot of things but I am still getting a lof femboys.
It's trained on JoyTag; I'd take an image that you don't like and run it through JoyTag to see what terms you might want to place in the negative prompt.
@SlothSimulation Thank you very much!
@SlothSimulation 天才
@CyclopsGER just add futa, futanari, 1girl, woman, breasts, etc to the negatives. add one or two at a time, (futa and futanari for sure) and then maybe try using a male character lora.
@MochiTits Will try, thank you! But I dont want to use a lora. I like the characters from bigASP and does not want to alter them.
Immaculate model. Can't wait for a V2!
Isn't 1e-4 a very high learning rate? In my experiments, I need to use much smaller learning rates (around 1e-6) to avoid weird results.
Also why did you freeze TE2 but train TE2? I see that this is a popular choice, but I don't know why.
Learning rate depends on batch size; I used a very large batch size. I assume you mean why did I freeze TE2 but train TE1. The common wisdom is that TE2 tends to get overtrained quickly, so it's best to leave it frozen. Whether that's true or not, I did not ablate that.
@nutbutter Thanks!
Has anyone found a way to get quality images without using score_whatever and photo \(medium\) ? These prompts clarify the images, but they also restrict output in a nontrivial way judging on my experiments with not using them.
I've found you can dial the whole positive and negative preambles down to like .000001 and get most of the detail improvement with less imposition on the output flexibility, but if you know a better way, please post.
Hopefully any future version will not have the pony-style preamble.
Nice work, i have tried a lot with sdxl but till now i have got only garbage i tried with 84k images but i didn't get better output i trained the model with kohya dreambooth and can you tell me for 100k images do i have to change some of your config settings or will the same config setting work?
Can you tell me your discord id, i had some questions for you
Simply the best naughty checkpoint to date. Excellent work. Head and shoulders above all the rest I've tested in terms of output quality with good promptability.
Gives its best outputs with vertical resolutions around 1280, with height under ~1136 being clearly worse. Seems somewhat stronger in portrait than landscape.
Maybe the first model I've seen that makes green eyes look like real eyes instead of radioactive neon!
BigAsp can do latex, but needs strong prompting for it and just as it starts hitting, the model starts putting masks or goggles on people for some reason. It's a great foundation for loras with latex though and would probably work great with simple text embeddings for concepts like latex that are clearly in unet but prompt poorly stock. Similarly, with the exception of the very strong cumsluts tag, cum prompts barely register but if you prompt hard it's in there. Excellent results for nipple piercings, so-so with pokies (covered nipples). More flexible than most models with non-POV and non-solo focus.
The known tags list is great, but most of the non-danbooru tags do nothing. It would be great to see that list with the number of times the tag appeared in the dataset to give an idea of which might really work. Also nice if bad-tokenizing tags aliased to stuff we can prompt, like :d that just gives :D, or :q or 69, but so far e.g. I haven't found a single model that can show a person licking their lips.
The tag list with counts: https://gist.github.com/fpgaminer/8c1b488aa81f9713efdb8f9245e8a0e8
I know that people like me are rare, but I like dark femboys. But I can't cross them with white guys. It turns out just a guy in white clothes. How to fix it. What am I doing wrong?
Amazing work, can you please consider making a version for Flux? or at least a Flux lora? please it would be really cool
Aren't flux models quantized? I've heard they're a pain to train because of it, and that might be why we haven't seen much progress at NSFW checkpoints so far. That and the license. Can any trainer comment? I'd dearly love a flux-based model that retains prompt understanding (multiple different people etc), but I wonder if it's too difficult.
Absolulely an amazing model! So much possibilities hidden within! It puts realistic expressiveness on another level. My favourite alongside NatVis
HOLY SKIN QUALITY. HOLY SEX. HOLY MULTIPLE CHARACTERS & GOOD FACES. HOLY MOLEY IT PLAYS WELL WITH 8 STEP LIGHTNING LORA?! Don't use add detail at usual strengths, start with literally a value <0.10. it takes away the photo realism and skin details, and air brushes it out, its fine at high values in oil, wet, cum covered scenes, and more of those studio smooth perfect AI girl looks if you want that, but even for the liquid covered porn I would err on low first, you'll be surprised. The prompting has its plus and minuses, I suspect the prompting in part is why this model can output such good fingers, limbs, sex, skin, photorealism, shadows, lighting, etc, but it is a bit frustrating with no natural language. if Natvision prompting and this model could be achieved....
It's hard to explain the skin, it's the photorealism, the replication of the almost "splotchiness" (patchy?) of red and white tones in skin in RAW photos, and then the shadows and natural light.
It can be a huge pain to not get futanari, get correct amount of characters, not have two guys when prompting for mff scenes, but its worth it. Pony will always have its place for the artifical sex creativity, but gone are the days of needing to use controlnet, or pony realism img to img with a normal SDXL model to finish for complex scenes, and sex scenes.
It plays really well with character loras, even ones without booru style tags, It's turned portrait based character sdxl base trained loras, into babes getting pounded pretty easily.
make sure to check out the tag data; https://gist.github.com/fpgaminer/e835328c7883b1929419273f6e73c3aa
this guide;
https://civitai.com/articles/5864/mining-the-bigasp-caption-database ,
and I'll add on to the data list usage: lunaokko, aeriessteele, ellieleen1, make for great combinations, ellieleen1 and your own asian character loras make for some great silver/blonde haired versions of your character.
I use it with DPM++SDE Trailing, 8 step lighting lora, CFG 2, shift 1. still great great skin photorealism, faces can suffer.
is this the same as https://huggingface.co/fancyfeast/bigasp-v1/tree/main ?
can somebody clarify the settings more? I use the ones mentioned but I'm still getting only garbage.
I was having trouble with it too. Every single image came out soft, blurry, and with a massive amount of film like grain, even though I made no mention of adding grain. It's also given me the most deformities of any other SDXL model I've tried. No matter which settings I used, resolution, prompt style, LoRAs, fixes or detailers, I couldn't get a single usable output. Also, like so many other models, it was very Asian-centric and I had to add negative prompts to try and stop it, which then led to it giving me just black women. After spending a couple of days with it, I've given up and deleted it.
It seems like the Photo \(medium\) and aesthetic tags really restrict the outputs. There are a lot of concepts (like places etc) that it's clear the model still knows (you can trigger them without "photo medium" and "score" tags, but you can't get those ideas with the preamble.
They do appear to aid in getting max quality output, but at the cost of reduced idea-pull from the base model. I'm hopeful this can be addressed and look forward to seeing the V2 if we ever get so lucky.
why does the face always block out when im generating nsfw content? Does anyone have the same issue?
bigASP shouldn't be doing that. What program are you using, settings, prompt, etc?
@nutbutter im using automatic 1111, i haven't change any setting from default. promt is just very vanilla nsfw picture, nothing extreme
@lojeff8816 I uploaded an image I generated in auto1111: https://civitai.com/images/34774056 Try dropping that into auto's png info tab and sending to txt2img and see if you can reproduce the image.
Hey, nutbutter. I see work on JoyCaption is going well. Just curious if there was any update on potential plans for an expanded BigASP V2 in the future?
Yup, it's cooking.
@nutbutter Any hints on how long training might take?
@nutbutter Hi, what is the approximate percentage of the number of photos for each score_X ?
@null The actual training run takes about 5 days. I'm just finishing up data prep right now and it'll probably take a few test runs first.
@sisyphus953
score | percentage
-------+---------------------
0 | 2.3877273595267707
1 | 5.6785856601786178
2 | 7.5237223556480090
3 | 10.4240159440504969
4 | 11.7054169835993339
5 | 16.6620791964961223
6 | 14.9009992934230210
7 | 16.2911190162216239
8 | 10.5792245441183352
9 | 3.8471096467376693
@nutbutter How many pics will it be trained on? Very excited. Been looking forward to it since V1. Is there any way to get good results without photo medium and aesthetic scores?
@null 6M images
@nutbutter @nutbutter OMG THANK YOU. YOU ARE HERO. Can we please get the first trial run when it's ready? More checkpoints = more betterer.
@nutbutter Can you upload it to tensor art once you feel its ready to be uploaded? Im so excited to try it! 🙏🏾
@Spartacus98 Will do!
This is a great checkpoint.
Do any of the prompt words in the training contain "r/" from "reddit"?