

















These are some XL models based on NoobAI/pony XL with a little modifications, they are mainly for anime/realistic bara kemono content, and should be ok for all contents.
I chose pony purely because of its NSFW ability. (Now I'm thinking about switching to NoobXL because Pony is a pain in the ass to tweak)
NoobAI based model out now.
If you like my work, consider buy me a coffee please <3 (completely voluntary)
如同License内提及的,本模型及其生成的图像禁止商业化使用!
For CkNoob_EPS_Ⅺ_11:
This is a new EPS model that based on Chenkin Noob v0.1. Based on my testing, compared to EPS10, this model features better background coherence, higher contrast, slightly more detail, and a bit more responsiveness to artist styles. Just note that the composition of the generated images with the same prompt can sometimes differ noticeably from EPS10. And the overall feel and behavior of this model can sometimes differ from EPS10.
Just as the EPS10, when using this model, try using a CFG scale between 3–7 (recommended 5). It is recommended to keep using Euler a sampler for best overall results, but switching to DPM++ 2M may produce more detailed (and chaotic) outputs.
For NoobAI_EPS_Ⅹ_10:
This is a new EPS model that merges the the core features (hopefully) of EPS3 and EPS7. It aims to increase overall versatility while sacrificing just bit of fine detail. Backgrounds are much more stable compared to EPS3, though occasionally not as consistent as EPS7.
EPS10 fixed the issue of overly saturated or blown-out colors at high CFG values. Artist tags still work well as before, and stability when using the DPM++ 2M sampler has been improved.
When using this model, try using a CFG scale between 3–7 (recommended 5). It is recommended to keep using Euler a sampler for best overall results, but switching to DPM++ 2M may produce more detailed (chaotic) outputs.
For NoobAI_EPSReal_Ⅸ_9:
This is a new photorealistic model. Compared to EPSReal5, it sacrifices some photorealism in exchange for greater versatility, and also fixes a few minor bugs from EPSReal5. When using EPSReal9, set CFG to 4–7. The default sampler is Euler a, but in some cases switching to DPM++ 2M can enhance fur texture.
For NoobAI_VPR_Ⅷ_8:
This is a new VPRED model. Compared to VPR4, it still keeps the ability to generate very dark images, but fixes the issue of overly high contrast. At the same time, it greatly improves the photo-realistic style, while basically keeping the artistic style unchanged.
Plz use 'eular a' or 'eular' sampler for generation only, CFG 5-7, CFG Rescale(optional) 0-0.6.
Like VPR4, this model is also a v-prediction model, which means it requires some extra setup to work properly:
If you’re using this model in A1111 WebUI (none dev branch), make sure to download the .yaml file and place it next to the model. Also, don’t forget to enable the 'Zero Terminal SNR' option in the settings — it’s more likely for this model to get better results with ztsnr. If you’re using A1111 dev branch, enable ztsnr is all you need.
If you are using comfyui: download this image and drag it into your comfyui to get workflow: https://huggingface.co/Laxhar/noobai-XL-Vpred-0.5/blob/main/comfy_ui_workflow_sample.png
If you’re using webui reforge, make sure to enable 'advanced model sampling for reforge'. (Image below in VPR4 part)
For NoobAI_EPS_Ⅶ_7:
A slightly improved version campared with EPS6, it's slightly more detailed, more sharp/clear overall, and it can generate more stable backgrounds, this model's usage and purpose is basically the same as EPS6, please refer to the introduction of EPS6 (below).
For NoobAI_EPS_Ⅵ_6:
This is a model designed to optimize EPS3 (hopefully). Compared to EPS3, it has more vibrant colors, stronger contrast, and while it keeps most of the high detail that EPS3 is known for, the backgrounds are cleaner and more organized (not as messy or chaotic as EPS3 often does to backgrounds, and rarely generates messy dots/particles). It also has some of the Illustrious models mixed in as parts, and it seems to work better with Illustrious-based LoRAs than EPS3?
This model is still responsive to artist tags, and has a less "3D-like" default style compared to EPS3 when you're not using any style/artist tags. Note that some artist tags may react differently than EPS3.
Currently, the issues with this model are: At higher CFG, images can sometimes turn out too vibrant or overexposed. And when not using artist tags, the images can sometimes be too simple (not very detailed) compared to EPS3. Finally, this model seems more likely to generate images with watermarks or signatures.
Keeping a low CFG scale when using this model may give you better results (the ideal CFG=3~6), use a lower CFG scale (Minimum CFG=2) when the prompt is short (or when you feel the image is too saturated), and increase it as the prompt gets longer (maximum CFG=7).
Overall, this model performs equal/slightly better than EPS3 most of the time (especially when you're using artist tags) IMO, but the vibe’s sometimes different... So if you prefer EPS3, feel free to swap models as needed.
Still use dan tags and e621 tags plz, csv here: https://drive.google.com/file/d/1FuME-Ch5a9PsfDX5DN68ygjQaR28EdXZ/view?usp=drive_link
For NoobAI_EPSReal_Ⅴ_5:
This is a photorealistic model that fixes the brightness and contrast issues, compared to EPSReal 2, this model no longer generates very bright nights and it has slightly more details than EPSReal 2, but the tag(prompt) obedience of this model may be slightly worse.
This model still struggles to make photorealistic fur textures (sometimes the fur can look like fursuit/plush suit textures) and it sometimes tends to generate pov perspectives. And, this model struggles to make nipples disappear.
For NoobAI_VPR_IV:
VPRED version of checkpoint was recently updated to add VPRED autodetection, redownload it plz.
This is an experimental v-pred model based on Noobai V-Pred 1.0. Compared to EPS3, it gives you higher contrast, more vibrant colors, and can create darker images. The overall style leans more towards e621 than danbooru. But it’s trickier to use than EPS-based models, and tends to produce less detailed results.
Plz use 'eular a' or 'eular' sampler for generation only, CFG 5-7, CFG Rescale(optional) 0-0.6.
If you’re using this model in A1111 WebUI (none dev branch), make sure to download the .yaml file and place it next to the model. Also, don’t forget to enable the 'Zero Terminal SNR' option in the settings — it’s more likely for this model to get better results with ztsnr. If you’re using A1111 dev branch, enable ztsnr is all you need.
If you are using comfyui: download this image and drag it into your comfyui to get workflow: https://huggingface.co/Laxhar/noobai-XL-Vpred-0.5/blob/main/comfy_ui_workflow_sample.png
If you’re using webui reforge, make sure to enable 'advanced model sampling for reforge'.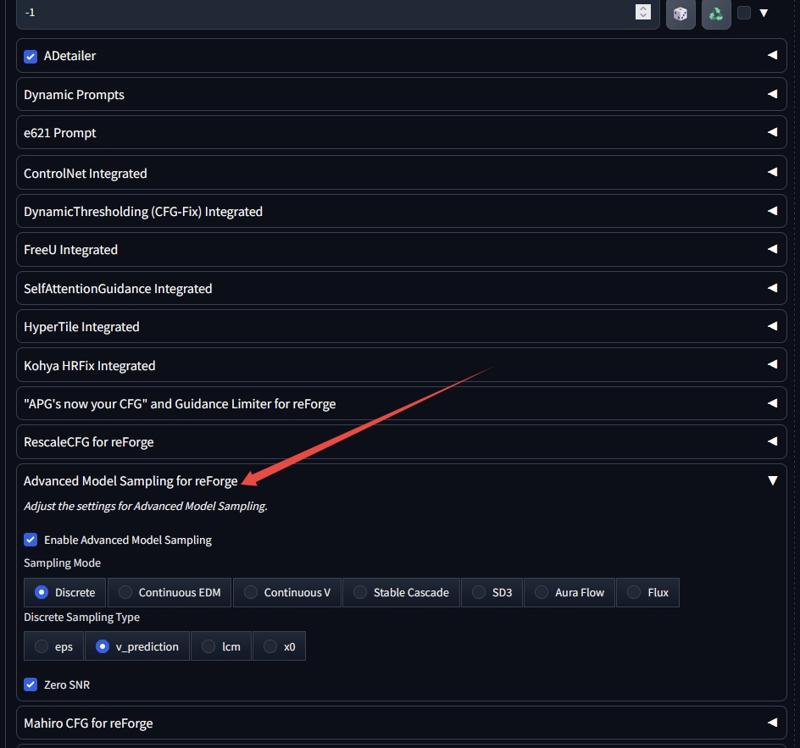
For NoobAI_eps_III:
This model is an advanced version of Eps I. Compared to Eps I, Eps III's method is more aggressive, it has more details, and it's more responsive to artist tags, and has brighter colors, but may be slightly less stable than Eps I.
Still use dan tags and e621 tags plz, csv here: https://drive.google.com/file/d/1FuME-Ch5a9PsfDX5DN68ygjQaR28EdXZ/view?usp=drive_link
For NoobAI_epsReal_II:
This is an experimental model, trying to convert the style of a noob model into photorealism, the final result is kinda ok?
Add 'realistic, photo, photorealistic' to positive and 'flat colors, toony' to negative prompt can enhance realistic style, but these tags may affect anatomy (especially the penis), please use selectively <33
For NoobAI_eps_I:
A merged model using NoobAI epsilon-pred, can react to artist tags. Use both danbooru tags and e621 tags, add quality tags plz.
Tag csv here: https://drive.google.com/file/d/1FuME-Ch5a9PsfDX5DN68ygjQaR28EdXZ/view?usp=drive_link
For realistic_delta:
A more versatile model compared with beta version, it's more accurate with tags, has better compatibility with loras, but may lose some details and has less photo-realistic style.
For v4.0:
v4.0 is just a regular update :o
For realistic_beta:
This is a version based on pony realism model, intended to do photo-realistic furry contents, should be able to do all furry/human contents(male furry bias). It looks good if nothing's wrong xd.
Issues:
The background of the generated image is not well controlled by prompts, this model is not very obedient, it often generates canyons and some green plants as background, and cannot do large sky background. This problem can kinda be solved by prompting.
Sometimes it does a lot of unnecessary blurring/depth of feild.
Cannot do very dark/high contrast images.
Somewhat unstable in doing NSFW contents. (Compared with those anime pony models)
Sometimes the body parts of furry characters will become human(hands especially).
Having trouble getting characters out of the ground! (They seem to be stuck to the ground XD)
For v3.0:
This version has reduced anime style, enhanced details, and seems to be more responsive to artist tags.
For v2.0:
A model similar to v1.0 that fixes the yellowing issue, increases color saturation and may have more details, but it is worse at doing realistic contents?
For v1.0:
It's ok to use 'score' tags or 'zPDXL' embeddings or not, use score tags will generate kemono-styled (japanese furries) images, not using score tags will generate western-styled (those common ones on e621) images.
Prompt length can significantly affects the style and the effect of score tags.
Can react to some artist tags.
Optional style tags: 'by mj5', 'by niji5', 'by niji6'.
Sometimes output images can be too yellow with score tags. (especially with short prompts)
Description
FAQ
Comments (49)
Looking forward to seeing this grow, awesome!
Just a follow up- holy cow is this good. All my Pony trained loras have been working so well on it too; with some I am getting better results than even with Pony. Some don't work ofc, but many do.
It generates consistently decent heads and faces. I am absolutely blown away.
I just made my first lora for this, and will be posting it soon. Some incredible results I can't wait to share.
Good start, but I prefer the vpred models much more. Anime is perfect with Pony, but Furry... seems to need a few more versions.
you can try compassmix for XL if you like vpred models <333
He normally starts with either an anime or realistic look before doing a hybrid version. Be patient and let the man cook. Good things come with time.
SAY GOODBYE TO F*CKING PONY!
Too early to say, but this does look promising
Not quite yet. I think CompassMix XL Lightning might fit your needs if you're tired of Pony, or just the Seaart XL model if you've got a beefy GPU.
but this model is based on pony xddd
It's still a pony model, but we get the gist.
Nice as always and the first model that implemented my prompts for a specific image the way I imagined it :)
This checkpoint has been a long one waiting for me. All the other SDXL and Pony checkpoints either never come close or skew way too much toward humans and lithe female looks.
The results I am getting is spot on furry artwork with none of those awkward results where human lips or some other non furry look pops up.
I forsee good results with future endeavors with this. I have finally came across a checkpoint to use with the new stage of picture making with the program. Kudos and well done to the maker.
I have tried this model and it has the same problem as the XL version of YiffyMix. It is not able to generate anatomically correct female animal genitalia.
i think it might be because pony can't do this right :(
One thing I will miss with this model is the ability of making images in the style of multiple artists that Seaart's Model and the SD1.5 counterparts of this model have, but it can be solved with the creation of a Lora.
yes, but since XL is be better than sd1.5 in doing artist styles, and there will be more artists who would have problems with that, so i think eliminating the effects of artist styles would be better :o
Wait, what? This was actually the biggest plus point of me of the v120! Instant showstopper, sorry. I got great results by merging two or three different artists. Why wouldn't artists care for SD.1.5 but suddenly for SDXL model? Doesn't make much sense for me. Okay then, I will have to wait or look for another model :(
Just a quick question from newbie: why I can't see buttom "create" under some models, and how to make them generate?
civitAI's fault :(
Users in CivitAI can consent the usage of the models they upload here in the generator, but if that model is a Checkpoint, CivitAI's staff have the last word.
There really should be a styler CSV for this checkpoint
maybe next time, the artist's styles are not that good in this version
Although I been using this primarily for furries, it is actually amazing on humans.
Is onsite generation possible with this model?
i've check the 'onsite generation' check box but civitai won't let us use it so idk :(
Are you planning on doing realistic/hybrid/anime versions like with your 1.5 model?
no plans at the moment as there seems to have been decent realistic models on this site based on pony xd
Pony Realism 🔮 - v2.1 Main + VAE | Stable Diffusion Checkpoint | Civitai
as for hybrid models, i think artist tags on XL would be more likely to be offensive to the artists (because I've tried, the styles are far too similar), so there will be no such models for now :o
Noob here, how does this checkpoint merge work? Can i merge it with other checkpoints?
of course you can use this model to merge with any other models, you can use A1111's default merger to merge models, please note that merging XL models will consume a lot of system RAM :(
Amazing model,thank you so much :)
I need to get the space to effing download this, this is yiffin' amazing XDDD
Is there a way to use LORA in image generate without downloading it?
I need this to make a character lora but can't figure out how to use it after downloading it.
Currently there is no way to use this model without downloading it, as for training, you can directly use pony diffusion XL to train loras, and the trained lora can be used on this model.
Try on Tensor: https://tensor.art/models/750720954595964488
Outstanding model with excellent style response. Thank you for releasing it.
wow, and as I way in my native language, (Esto va a ser chido)
使用起来像是Niji画风的小马模型,整体使用体验下来比较顺手,但是有两个不知道是不是只有我出现的问题:1.画风加了不同提示词感觉差别不大(看起来都像是Niji的日系二次元画风) 2.这个模型好像很青睐生成一些光影对比明显的图,甚至有时候整个画面都是过曝或是欠曝的状态
是这样的,训练的时候加入了大量niji画风,然后混模的时候画师tag效果被削弱了,然后画面经常发黄,是模型的问题(
目前只有用画风lora然后PS调色了,建议等迭代()
@indigowing 已老实 期待以后的版本
I've downloaded it, but how do I use it on this site?
Currently there is no way to use this model on civitAI :(
@indigowing fuck...
Two questions:
1. Why aren't people putting the prompts in their pictures anymore? I haven't been here a little while. Just curious why that changed.
2. What do keywords like score_8/score_8_up do? I've been seeing it in a lot of prompts and don't know what the different numbers are supposed to mean...
Based off the pictures posted, this does look like a great model.
1. It is likely the site does not pick up the prompt metadata for some people. I have this issue myself because I use custom ComfyUI nodes. Others may choose not to share their prompt.
2. The score tags are specifically for PonyXL based models. This model is a finetune of Pony, so they will work here. Check out the Pony Diffusion V6 checkpoint in the Suggested Resources above for details.
@syntaxerror22 Hello, can you say more? I still don't understand.What do keywords like score_8/score_8_up do?
@yxyxy go onto the pony xl page on civitai, score tags are used for what type of images you want your image to be based off from, this is in the from of ratings, when training data is taken the score of it in the form of likes from different sites is mapped to the score system, score_9 is highest, yet you usually want to use a few with it, so score_8_up, score_7_up, score_6_up, so that your generated image will be of this quality, these usually should be at the start at the prompt before all else. its braindead but good ig, dk
I wish it would/could work with prompts, just like the v120 did. I enjoyed using ((emphasis)) by (these things) rather than having to constantly change numeric values.... let alone this overall "score_up" principle is just stupid.
How do I use it???