





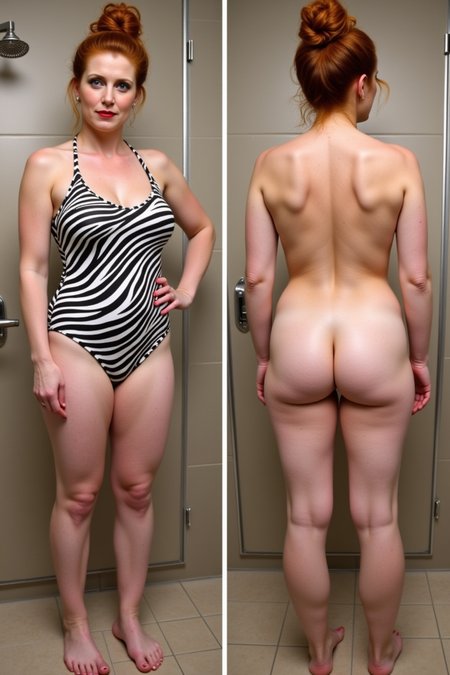













The purpose of this LoRA is to produce side-by-side images of a subject, one wearing clothes and the other nude.
Since the text encoder is not trained, it may need a little push to get it to provide the correct composition. Try prefacing your prompt with these instructions: side-by-side clothed and nude images of [a woman] wearing [clothing] replacing [a woman] and [clothing] with whatever particulars are relevant to your composition.
Version 4.9 - trained at 1024x1024 and finely tuned for better photorealistic female anatomy. Not as flexible for male subjects and illustrated/animated styles.
Version 3.9 - trained at 1024x1024 with limited synthetic data. Slightly biased toward occasionally generating blurry/lower quality photographs
Version 2.5 - trained at 640x640 - Produces better results than v1. Somewhat biased toward synthetic data with unrealistically smooth skin.
Version 1.0 - trained at 512x512
Description
This version was created using the same dataset as V1 but with a slightly larger resolution and using the Prodigy optimizer over five epochs. I think it gives slightly better results.
FAQ
Comments (1)
Interesting,but quality is not even close to Flux,generation is more like SDXL
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.