



v2_FLUX_D_model_Q8_clip_Q8
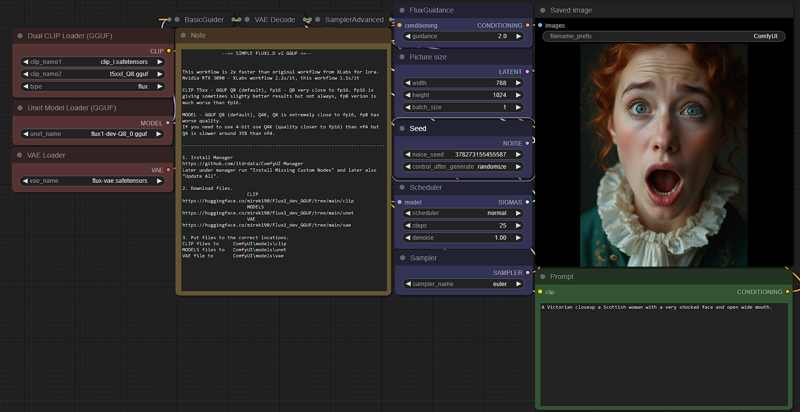
v2_FLUX_D_model_Q8_clip_Q8_IMG_TO_MG
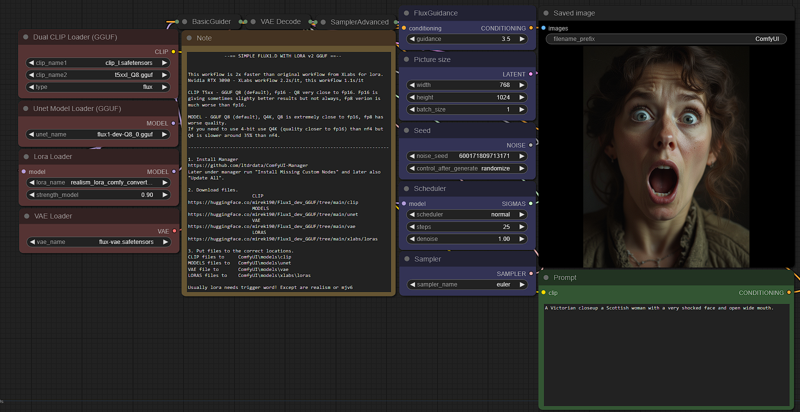
v2_FLUX_D_model_Q8_clip_Q8_LORA.
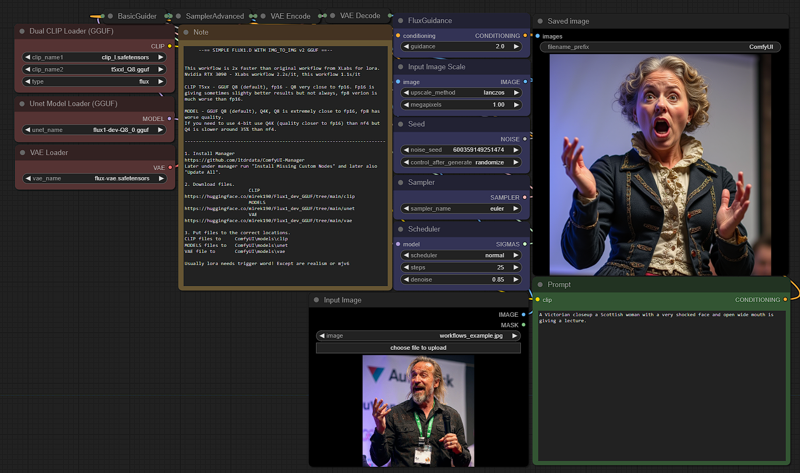
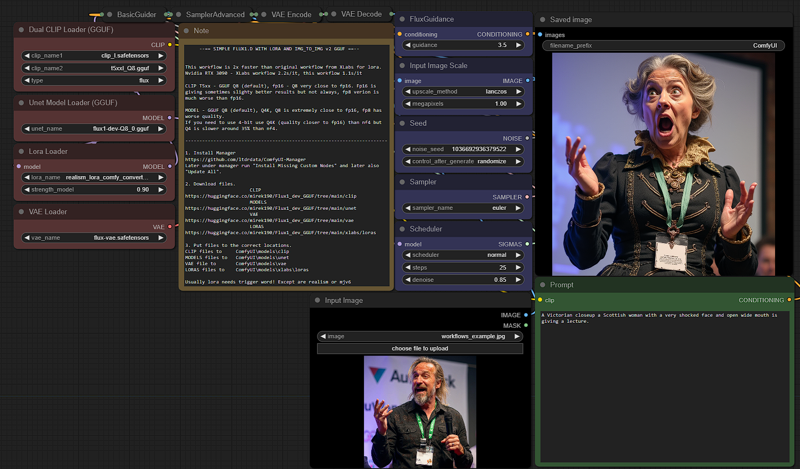
v2_FLUX_D_model_Q8_clip_Q8_LORA_IMG_TO_MG
Comparison T5xx fp16 to Q8 - almost the same quality


Comparison Q4 to Q8 (Q8 is extremely close fp16) - Q4 slightly dropped quality but still much better than nf4.
Q4
 Q8
Q8

Q8 Q4
Q4

Q4 is also a bit slower than nf4 but quality is far better
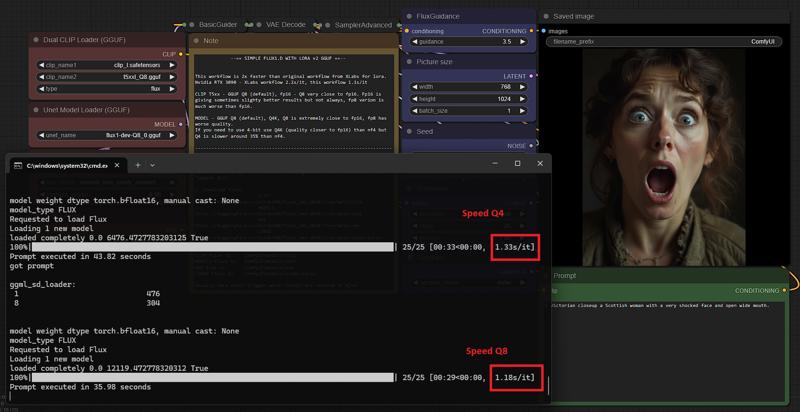
Speed Q4 vs Q8
Description
FAQ
Comments (16)
q8 and t5q8 are 2 different things? i'm confused a little
FLUX1 is using - model (here Q8 gguf) and clip (here t5xx Q8 gguf) also apart of those 2 ggufs are clipI (fp16) and vae (also dp16) as those last 2 are very small fp16 is not a problem.
t5xx refers to the clip model (it goes in the clip folder) the other (dev or shnell) refers to the unet model. Then, there's also the vae model
Your workflow is a joy, thank you
thank you ;)
ok. i have 3060 12gb and 40 gb ddr4. your workflow with dev Q4_1 and t5-v1_1-xxl-encoder-Q5_K_S gives 4.30s/it. Can be Q8 fast?
Q8 is faster but it depends if your card will be swapping to ram often ... then will be slower.
I get the following error - I updated comfy and the custom nodes:
Error occurred when executing DualCLIPLoaderGGUF: module 'comfy.sd' has no attribute 'load_text_encoder_state_dicts' File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 316, in execute output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 191, in get_output_data return_values = mapnode_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 168, in mapnode_over_list process_inputs(input_dict, i) File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 157, in process_inputs results.append(getattr(obj, func)(**inputs)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-GGUF\nodes.py", line 287, in load_clip return (self.load_patcher(clip_paths, clip_type, self.load_data(clip_paths)),) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "F:\ComfyUI\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-GGUF\nodes.py", line 246, in load_patcher clip = comfy.sd.load_text_encoder_state_dicts( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Solved the issue by updating dependencies in Comfy
"LORAS files to ComfyUI\models\xlabs\loras"
Are you sure Loras go there?
Anyways I've put them under models/loras/flux and they appear but don't produce any difference!
Xlabs nodes point there.
I'm not seeing any difference in image output no matter what lora I use. It doesn't seem like this is actually using the lora's provided.
sorry .. my mistake ... loras going to models/loras
Is it as simple as cloning the lora node and linking it up to add another lora?
Thank you for such clear instructions and workflows that actually work!!
just getting a grey image all the time?