



















Merged with Hyper dev 8 steps lora from Bytedance, Unet only, need clip L, t5xxxl and vae
https://huggingface.co/ByteDance/Hyper-SD/tree/main
Ultimate version
More versatility
Improved artistic side
V4.0
Better realism
Better versatility
Better nudity
Try it with:
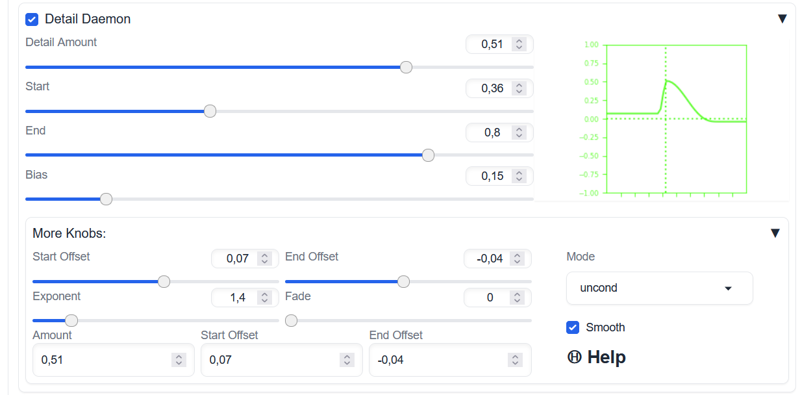
Euler/Beta, 10 steps, guidance 3,5 and detail deamon
V3.0
More lora merged for more versatility
Better lighting
Fix vertical trame
V2.7
Merged with my lora: https://civarchive.com/models/866492/moreface-lora
More realism
More versatility
V2.6
More realism, thanks to @bissonfrederic69429 for his wonderful lora SkinDetails
Recommended settings : 10 steps, Guidance 3, Euler/Beta
V2.4
More lora merged
Improve NSFW
More realism
More versatility
Hyper Dev gguf-q4_0 version merged with my lora Real-lora.
Hyper Dev Fp8 Unet version merged with my lora Real-lora.
Hyper Dev bnb nf4 Unet version merged with my lora Real-lora.
https://civarchive.com/models/650205?modelVersionId=727461
More realism for skin, background with less blur.
8 to 20 steps recommended settings : 12 steps, distilled CFG 3, Euler/Beta
Node for comfyui: https://github.com/DenkingOfficial/ComfyUI_UNet_bitsandbytes_NF4
Work with Forge, add vae and clips manualy.

Description
gguf q4_0 version
FAQ
Comments (14)
Why did you use Q4_0, instead of Q4_K_S ?
This work is amazing! May I ask if you used any open-source code for training and merging LoRA based on Flux? Could you please share it with me? Thank you!
@jice Thank you for your response. Based on your suggestion, I tried using the code from [flux_merge_lora.py](https://github.com/kohya-ss/sd-scripts/blob/sd3/networks/flux_merge_lora.py) to merge flux1-dev.sft with Hyper-SD/Hyper-FLUX.1-dev-8steps-lora.safetensors, but I encountered the following error:
WARNING Unused keys in LoRA model: flux_merge_lora.py:192
['transformer.context_embedder.lora_A.weight',
'transformer.context_embedder.lora_B.weight',
'transformer.norm_out.linear.lora_A.weight',
'transformer.norm_out.linear.lora_B.weight',
'transformer.proj_out.lora_A.weight',
'transformer.proj_out.lora_B.weight',
'transformer.single_transformer_blocks.0.attn.to_k.lora_A.weight',
'transformer.single_transformer_blocks.0.attn.to_k.lora_B.weight',
'transformer.single_transformer_blocks.0.attn.to_q.lora_A.weight',
'transformer.single_transformer_blocks.0.attn.to_q.lora_B.weight',
'transformer.single_transformer_blocks.0.attn.to_v.lora_A.weight',
'transformer.single_transformer_blocks.0.attn.to_v.lora_B.weight',
'transformer.single_transformer_blocks.0.norm.linear.lora_A.weight',
'transformer.single_transformer_blocks.0.norm.linear.lora_B.weight',
'transformer.single_transformer_blocks.0.proj_mlp.lora_A.weight',
'transformer.single_transformer_blocks.0.proj_mlp.lora_B.weight',
'transformer.single_transformer_blocks.0.proj_out.lora_A.weight',
'transformer.single_transformer_blocks.0.proj_out.lora_B.weight',
'transformer.single_transformer_blocks.1.attn.to_k.lora_A.weight',
'transformer.single_transformer_blocks.1.attn.to_k.lora_B.weight',
'transformer.single_transformer_blocks.1.attn.to_q.lora_A.weight',
'transformer.single_transformer_blocks.1.attn.to_q.lora_B.weight',
'transformer.single_transformer_blocks.1.attn.to_v.lora_A.weight',
'transformer.single_transformer_blocks.1.attn.to_v.lora_B.weight',
'transformer.single_transformer_blocks.1.norm.linear.lora_A.weight',
'transformer.single_transformer_blocks.1.norm.linear.lora_B.weight',
'transformer.single_transformer_blocks.1.proj_mlp.lora_A.weight',
'transformer.single_transformer_blocks.1.proj_mlp.lora_B.weight',
'transformer.single_transformer_blocks.1.proj_out.lora_A.weight',
'transformer.single_transformer_blocks.1.proj_out.lora_B.weight',
'transformer.single_transformer_blocks.10.attn.to_k.lora_A.weight',
'transformer.single_transformer_blocks.10.attn.to_k.lora_B.weight',
'transformer.single_transformer_blocks.10.attn.to_q.lora_A.weight',
'transformer.single_transformer_blocks.10.attn.to_q.lora_B.weight',
'transformer.single_transformer_blocks.10.attn.to_v.lora_A.weight',
'transformer.single_transformer_blocks.10.attn.to_v.lora_B.weight',
'transformer.single_transformer_blocks.10.norm.linear.lora_A.weight',
'transformer.single_transformer_blocks.10.norm.linear.lora_B.weight',
'transformer.single_transformer_blocks.10.proj_mlp.lora_A.weight',
```
It seems that many keys don't match. Could you please take a look and see if the code I’m using is the same as yours?
@huxianwang I dont know if the same code, i use the gui of Kohya.
https://github.com/bmaltais/kohya_ss
@jice Thank you for your response. May I ask, did you first merge all the LoRA models with FLUX before applying the quantization?
@huxianwang Yes
How to make the “Hyper Dev Fp8 Unet” model work in Comfi? I always get an error when running workflow:
UNETLoaderNF4 Dtype not understood: F8_E4M3
Comfi updated, node installed https://github.com/DenkingOfficial/ComfyUI_UNet_bitsandbytes_NF4?tab=readme-ov-file
What am I doing wrong?
This WF working good https://civitai.com/models/700264?modelVersionId=783547
skill issue i think
same
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.