

This is a reposted model.
I am not the original creator.
Warning:This model is generally only used as a base model for training LoRA, and the image generation effect of this model is not as good as f1.d-fp8.
But if you insist on using this model to generate image, it also works. You can have a try.
source: Kijai/flux-dev2pro-fp8 · Hugging Face
And maybe above is also not the original creator, below is a fp16 version.
source: ashen0209/Flux-Dev2Pro · Hugging Face
I don't know how they are related, so I posted the sources of both.
The principle and effect of this base model are as follows: (also reposted)
source: Why Flux LoRA So Hard to Train and How to Overcome It? | by John Shi | Aug, 2024 | Medium
Why Flux LoRA So Hard to Train and How to Overcome It?
TL, NR
Do not train LoRA on distilled model like Flux-dev/schnell.
Train LoRA on a finetuned model with input guidance=1.0.
Here is a model I finetune with 3 million high quality data, not itself satisfactory, but will improve LoRA training result. (Do not apply LoRA on the tuned model, apply it on distilled model Flux-dev.)
https://huggingface.co/ashen0209/Flux-Dev2Pro
Some Examples for LoRA reslts:
https://huggingface.co/ashen0209/flux-lora-wlop

The results got from LoRA with the same train/val setting tuned from different model
Background
The recently released Flux model by BlackForest Lab is truly impressive, standing out with its exceptional text comprehension and detailed image quality. It surpasses all current open-source models by a wide margin, and even leading closed-source models like Midjourney v6 have no advantage when compared to it.

However, when the open-source community for text-to-image models attempted to fine-tune it, numerous challenges emerged. I found that the model would either collapse entirely in a short time or produce poor fine-tuning results. Issues like distorted human limbs, diminished semantic understanding, and blurry, meaningless images became prevalent. Unlike with SD1.5 or SDXL, fine-tuning or training LoRA on Flux.1 proved to be far more difficult. Here, I’d like to discuss the potential reasons for these difficulties and explore possible ways to overcome them.
Understanding Flux-dev distillation
Let’s first guess how Flux-dev works. Unlike SD and many other T2I models, Flux-dev does not use negative prompts for CFG (classifier-free guidance) because this guidance is already distilled into the model. The training objective might be as follows (personal guess, but very likely):

Guessed training process
Firstly Flux-dev is initialized by Flux-pro, and during each training iteration, the guidance is randomly chosen and using this guidance scale, Flux-dev predicts the denoising result. Meanwhile, Flux-pro predicts the denoising result without the guidance embedding, but in a classifier-free guidance manner, i.e predicting the positive and negative at once and combine them with guidance_scale. Flux-dev is likely trained with that distillation supervision in addition to the flow matching loss. After this distillation process, the Flux-dev model can generate images with only half the computational cost compared to the classifier-free guidance method while maintaining similar quality.
As for Flux-schnell, it may be produced using adversial distillation method, similar to what was introduced in SDXL-turbo. However, since it is more challenging to train, we will not discuss it further here.
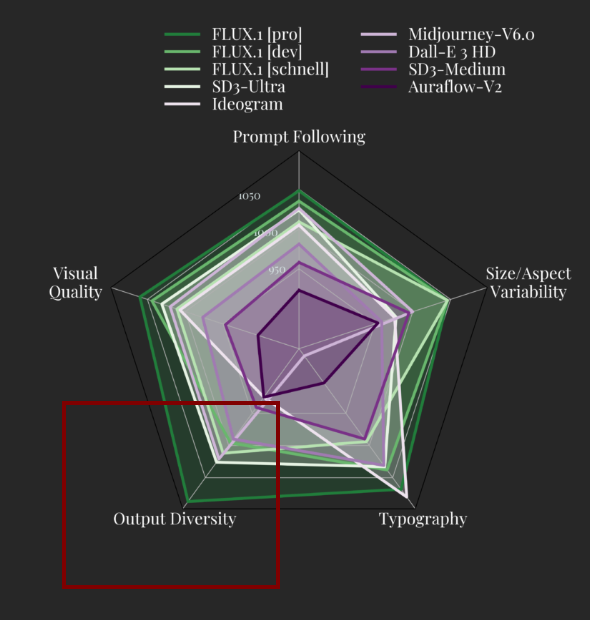
Speculation that some capability has been “cut off” from pro model
Additionally, there might be other details that we not yet know. For instance, the output diversity score of Flux-dev and Flux schnell is significantly lower than that of Flux-pro. This could indicate that some other capability has been “cut off” or reduced. For example, there might be another input condition, say, an aesthetic input embedding that was likely restricted to a narrower range (maybe for human preference) in the Flux-pro teacher model during distillation and do not exist in Flux-dev. There is also other possibility that the dev model is just overfitted to a much smaller subset of the training set. All such speculations are likely, but at this point, the truth remains unknown.
Why the training fails
After understanding the distillation process of Flux, we can figure out the key reason for the failure in training Flux-dev lies in the cfg guidance scale. How should it be set during the training process without the distillation from Flux-pro?
If the guidance scale is set to 3.5 or within a reasonable range greater than 1, as recommended for the inference stage, it might seem like the good approach since it mirrors the values used in the original training stage. However, without the constraints provided by the Flux-pro cfg results, the training dynamics change significantly. It will then destroy the guidance embedding since guidance distillation does not exist any more and often leads to the collapse of the model if the training process is long enough.
The easier approach is to use a guidance scale of 1.0 during training. This might seem counterintuitive, given that the original training and inference stages do not use a guidance scale of 1.0. However, there are two reasons why this is good: (1) The distillation loss under guidance=1.0 is minimized because cfg does not take effect on flux-pro which approx flux-dev so that we can get rid of the teacher model. (2) The setting of training, without distillation, mirrors that of Flux-pro. And Flux-pro itself has no guidance scale vector as input and defaults to 1.0. Therefore, generally, training the model with guidance scale 1.0 is to recover the Flux-pro model.
However, there is still problem. No one knows how many images and how much computational resources does it takes. Additionally, guidance scale 1.0 is probably out of distribution of the original Flux-dev distillation training, indicating that if not being trained with many steps, it will not be solid enough.
How to train Flux well
Unfortunately, there may not be any easy solutions. Many LoRA models have been produced, but few are satisfactory without sufficient datasets and training steps. The most reliable way to produce a good model is to recover Flux-pro by training on Flux-dev and then fine-tuning the LoRA on that recovered model, rather than on Flux-dev. Otherwise, we risk losing the guidance embedding or ending up with low-quality results.
Here is the fine-tuned model “Flux-dev2pro” that I obtained by training on 3 million high-quality images for two epochs. https://huggingface.co/ashen0209/Flux-Dev2Pro
While it’s far from perfect and actually produces worse results than Flux-dev, I did notice several improvements that could be beneficial. Let’s take a look at some generated images with a guidance input set to 1.0:

Using a guidance input of 1.0 is not a typical setting for inference and generally leads to poor results with the original model. However, it demonstrates that the fine-tuned model performs better under this specific training setting, where the original model fails. Although it actually performs worse under normal inference settings — since we lack the distillation training with a larger guidance scale — this isn’t a major concern. We don’t use it for inference; we use it solely for training (as discussed in the previous section) and can continue training LoRA with this setup to achieve better results.
Here are some of the outcomes from my experiments with this model. I trained a LoRA in the style of Wlop (a famous artist) on two base models, the finetuned “Flux-dev2pro” and the original “Flux-dev”.
LoRA url: https://huggingface.co/ashen0209/flux-lora-wlop
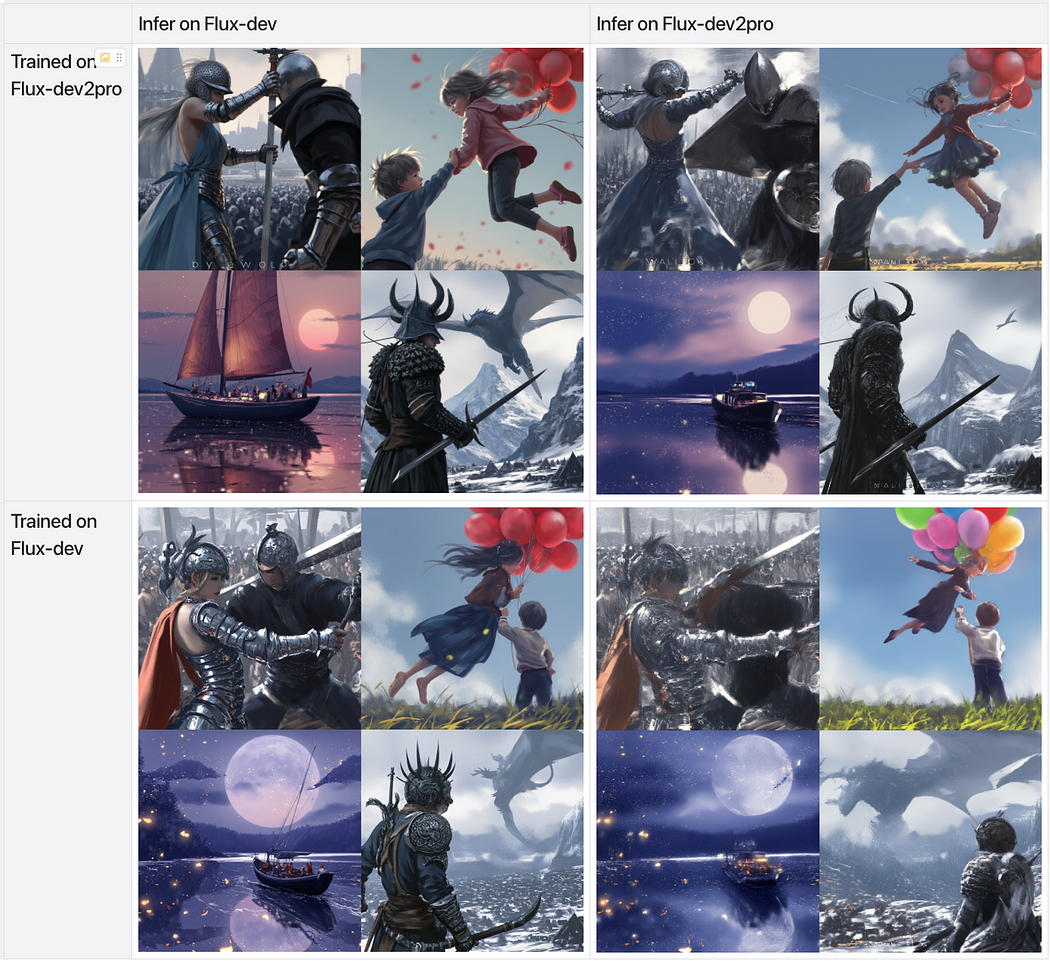
Training lora on finetuned model and infering on original model produce the best result
As expected, the LoRA trained on “Flux-dev2pro” and applied to Flux-dev produced the best results, outperforming the others by a significant margin — similar to how training a LoRA on SDXL and applying it to SDXL-turbo or SDXL-lightning yields superior outcomes.
While the initial results from training the LoRA on “Flux-dev2pro” and applying it to Flux-dev are promising and show significant improvement, it’s clear that my current version of “Flux-dev2pro” is still a work in progress. There’s potential for further refinement, and I’m optimistic that with continued effort, or contributions from the community, we’ll see even better models emerge. The journey to perfecting these models is challenging, but each step brings us closer to unlocking their full potential. I’m excited to see how this field evolves and look forward to the innovations that lie ahead.
Description
FAQ
Comments (20)
doesn't work with fluxgym...
I'm using the workflow from the instruction, and it seems to be working fine (it is in progress). Although I admit, fluxgym seems pretty awesome. https://civitai.com/articles/7131/flux-lora-trainer-on-comfyui-v10
@moxie1776 thanks, maybe I will try it, looks muy complicado though
@Partisano v1.1 isn't too bad. Just follow the walk through, and there are additional notes in the workflow. It is definitely more complicated, but I didn't have to much problem getting it to work. My first run w/ this is about done, I'm curious to check it out.
Fluxgym has poor compatibility and adaptability. Its training effect was also not as expected when I used it.
At this stage, I do not recommend using fluxgym. But to be honest, the UI of fluxgym looks more comfortable, and I like it very much.
You should use the workflow mentioned above, using the node 'flux trainer', it's useful and convenient.(The premise is that you know how to install nodes in ComfyUI)
@Partisano It just looks complicated. In fact, as a beginner, most parameters don't need to be changed.
To confirm - it's just the unet that has been retrained here, right? Not either of the CLIPs, or the VAE?
It's just a unet. Use this unet as your base model when you train a LoRA. CLIPs and VAE are not provided here, you can use t5, clip_l and ae.sft.
thanks, that's what I thought. Initial tests suggest this works well :)
if I use this model to train an anime-style LoRA, will it produce good results?
Sorry, I don't know...
Why not have a try?Or you can wait for a formal version of this model.
@NS_hhhh Thanks for your response, I'll give it a try. And, well, loosely speaking, Wlop's work can also be considered a kind of... um... anime style? It's just not that "anime." So, I still have quite a bit of confidence in the outcome.
Can you explain what operations you have done to the original please ? It was a sharded model in 3 safetensors files and way more than 11 GB
Sorry, I don't know either...So I posted the fp8 version.
Ok then i didn't pay attention enough :-) i was probably referring to the fp16 one. Thx for uploading the fp8 one. Have you used it yet for training ? If so have u seen a difference ?
@valentinkognito365 Yes, I have trained several LoRAs with the FP8 version, and my last three LoRAs were all trained with the FP8 version. But I don't have much time to compare the two base models with the same training parameters.If you get a obvious different result, welcome to share with us.
@NS_hhhh What exactly do I need to do to use fp8 version in FluxGym? Is it enough to replace the file in unet folder? Or it has to be renamed...?
can this model or similar models be used in fluxgym?
Funcionando para FluxGym solo lo tuve que poner dentro de C:\Users\particular\AppData\Roaming\StabilityMatrix\Packages\FluxGym\models\unet\bdsqlsz\flux1-dev2pro-single (esta fue al ruta de mi carpeta) y modifique el nombre del original, "flux1-dev2pro1.safetensors(de 23gb) y puse el descargado de aqui con(11.62gb) y funciono de maravilla flux.
Don't use FluxGym.
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.