

https://www.linkedin.com/in/abdallah-issac/
For lora training Purpose
https://medium.com/@zhiwangshi28/why-flux-lora-so-hard-to-train-and-how-to-overcome-it-a0c70bc59eaf
Description
FAQ
Comments (48)
Would it be possible to quant this down to half the size (maybe a Q8 or Q6_K) for those of us using GPUs with less than 16GB of VRAM? Or would that completely defeat the purpose of what you're doing?
I'll give it a try! Thanks a lot!
please the result
@AbdallahAlswa80 I'm still working on it. I've trained a couple of loras with your model, the results are fine, but I haven't tried to train the same loras with the standard dev model and compare them.
@DirectorKobayashi what about your result , what do use ? ai toolkit , kohya ssd scribt!
@AbdallahAlswa80 I'm using kohya through ComfyUI. I'm training some style lora's, one for a very specific army uniform / weapons set - another one to give them a proper look, to learn about blood and mud stains, wounds, explosions, etc.
I started with simple trainings with 15-20 images per dataset, Network size 16/32, high learning rates and low steps (2000-3000).
Now I'm retraining with 30-40 images, N64, low learning rate and 10000 steps.
@DirectorKobayashi hhh lets go to core ,, i have best lora result with 1:4 ex: 8:32 ratio of dim:alpha , with 0.0005 , and adam8bit , cosine with restart , what about yours !
@AbdallahAlswa80 interesting, I'm using 1:1 ratio of dim:alpha and 0.0001lr, adam8bit, cosine wih restart - The training will finish in about 10 hours from now. I'll let you know tomorrow!
One last thing I'm using fp32 gradient_dtype and save_dtype.
@AbdallahAlswa80 Hi, I've finished the trainings. I'm not really sure yet, but probably training with your checkpoint introduces some strange effect on the generations. It's a very peculiar issue, it looks like an inkjet print, when the printer is not very clean and it creates some vertical "columns" with different luma / chroma in the final image. If I use the lora trained with "standard" dev model I don't have that issue.
@DirectorKobayashi Are you testing the Lora on this checkpoint or on the standard dev checkpoint? According to the article, this checkpoint will yield bad results even with the lora you trained on it. Youre meant to train on this checkpoint and test the lora on the standard dev checkpoint
@Spooder yes I'm generating with the standard Dev model, not the one used for training. I followed the instructions. The results are not good in my opinion.
What was the estimated cost of the 2 epochs? What resources did you train on (1xH100? 8xH100?...) - I am wondering how "worth" this solution is as it still requires guidance scale of 1
did you try it for training ?
I don't think the means are worth the loss of control. It's more like converting it to a heavy version of sd1.5 with bells and context if we turn off the distilled configuration.
the guide talks about the results of using this, but it doesnt seem to cover what exactly this is and what is really different here...what did you do to this that makes it any different from the normal flux dev model? remove layers? set layers to 1? what is this? this appears to be just a fine tune....i'ld expect results with similar training parameters to be almost identical aside from shifting a little.
this for lora training ,,, not for structure discussion
@AbdallahAlswa80 its a undertrained fine tune, got it.
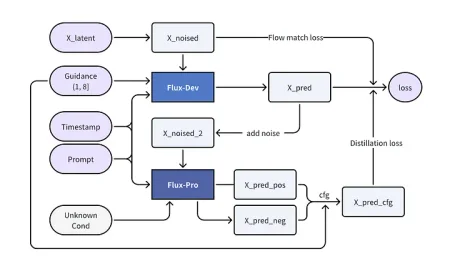
You should train LoRA on a fine-tuned version of Flux, like Flux-dev2pro, instead of using the standard Flux-dev model. Flux-dev uses distillation, which cuts off certain guidance capabilities, making LoRA training harder and less effective. The author fine-tuned Flux-dev2pro on a large dataset, which helps improve LoRA results by using a guidance scale of 1.0 during training. The recommendation is to train on Flux-dev2pro and then apply the LoRA to the original Flux-dev for the best results. ChatGPT
11k images isn't exactly the crème-de-le-crème image set.
This works very well, I've seen much better results training LoRA's with this checkpoint.
I don't like the idea of turning down the distilled configuration just for the sake of ease-of-access. It's losing the majority of context and situational control, to convert the model to a very heavy version of sd1.5 with weak t5 context control.
Initial tests show gender confusion, bad quality images, low context awareness, and ignoring entire prompt segments.
It seems the initial tests weren't meriting towards the overall goal when it comes to TRAINING with the D2 model and the inferencing the actual 1D model.
yea you cant use hammer to cut potato
AbstractPhila, With this model? Or with lora trarined on this model and applied then to regular dev model (as it supposed to be done)?
This model not for generation purpose, it's for training only. For generation you shoud use Dev (with all it distilled conf etc.)
@desm0nt https://github.com/huggingface/diffusers/blob/main/docs/source/en/api/pipelines/flux.md
Even for training purposes, you're better off running Schnell if you want to reduce the distillation CFG.
I've also noticed merging my already existing Flux1D loras with this Dev2 model has very little impact on the outcome, which basically means the results from my original 1D loras are having little to no impact on the D2 finetuned version of this model.
Meaning I have to start training again from scratch and discard all of my currently trained loras to get even close to the point I'm currently at, if I were to use dev2 as a training utility.
@AbstractPhila Lora trained on shnell have weak/incorrect effect on dev. While lora trained on this dev2pro for me (on the same steps with same config and dataset on ai-toolkit) works then on dev better that trained on clean dev. Not significantly but better. And instead of dev training it's training more stable (don't jump from good to bad and back) and do not overbaked on more steps.
@desm0nt I'll give it a shot. I'll train one later directly with dev2, and then run it on base dev for comparison. From what I've seen, my dev1 loras run clean on schnell as well with very few steps currently.
@AbstractPhila How did you training test go (if you did train that way after all)?
@Moofi Simulacrum V4 is entirely trained on a flux1d2 merge with loras.
@AbstractPhila Not much to see there :-)
@Moofi Yea only about 20 articles and a bunch of explanations that may or may not work together.
sorry if this is a dumb question...
would it be worthwhile merging a lora into this model? or, is there no benefit...
never mind i just saw another commenter 'kinda' answered the question...
@tedbiv I'm running more complicated tests with this model and so far the outcome is promising. I'd say train some loras on it. Remember, run the loras through standard flux 1D to inference correctly after training with this model.
more parameters in model means less loras effects , i think u will have less effect if your lora close to merged lora !
Any thoughts on Flux SchnellToPro or OpenFlux DevToPro?
Currently running 2 trainings;
Flux1D standard ->
Flux Lora UNLR 0.0001 TELR 0.000005
ETA; 30 hours -> 4x 4090s
Flux1D2 ->
Flux Lora UNLR 0.0001 TELR 0.000005
ETA; 30 hours -> 4x 4090s
Datset:
Simulacrum-V1 - Tags Only; 1400 images 1024x1024
The outcome is promising even with the incomplete dataset i used to train the first trained 8 epochs. It's worth experimenting further with this model. The majority of the context is retained and even context that is lost with the base Flux1D model's preliminary training stages is retained.
I've warranted myself further investigation and additional spending on more trainings with it due to the promise of the initial versions.
The full manifest will be ready sometime this week, since the full finetune trainings will take some time to conclude.
(Might have to eat my hat on this one, it turned out really good so far.)
@AbstractPhila aha the lose less in this model !?
@AbdallahAlswa80 So far training with THIS model and then using the lora with Flux1D is producing the correct outcome.
Can't seem to merge my created loras with it. Any advice?
please explain more about your lora merge way !
can we use this as a standalone model? i mean i dont really know exactly what this model is. is it just the standard flux dev/pro? or like a merged hybrid of both or something? thanks
yeah ! why not
@AbdallahAlswa80 ok thanks but if you dont mind what is this model? is this a hybrid of dev and pro or something else
According to the article linked, this is a special finetune and is NOT to be used to generate images as the results are worse than standard dev. It's purely for training Loras only that then function better in standard dev. If you use it to generate images, you will get bad results.
You can definitely use a model like this for image generation, but keep in mind since its not fine-tuned and its not pruned/trained or anything like that, so far as I know, the results you get will be less "easy", you'll have to do fixed seed experimentation, tweak the model sampling settings, and be really razor sharp with your prompts. I use dedistilled, its a similar concept from a slightly different direction. The point of these models is to have the model with as few predefined 'stylistic' parameters embedded in it. That makes it GREAT for training a lora, but for image creation, it takes some getting the hang of. HOWEVER, with all of that said, I wouldn't even consider using a distilled/pretrained/pruned type model anymore. The possibilites are pretty much endless with these type of models, you tell it to do something and it will do it. Its just that, sometimes, you gotta rethink how you're telling it what to do to get the results you want. There's also a mix of this model AND flux dedistilled that's on here, its by sapian, its the sapian nude male/female model, and oddly enough, it excells at non nude content, its just fine tuned in regards to if you DO want nudity, it looks better. So I highly recommend anybody use these types of models, just keep in mind you'll feel like you just started yesterday with prompt crafting because the results you get (at first) won't be ideal. But once you understand how the models like these "think" you can pretty much get them to spit out a more unique, not-so-overly polished looking result without having to plug a realism or photography lora in it. You want flash photography on a polaroid? its there. You want cinematic? its there... you just gotta figure out what cinematic means, and just how detailed you want to be. Or if you want it to look like an insta-cam photo in a truck stop bathroom... you gotta be able to roll up your sleeves and dig into your prompt tool box. but the results, in my opinion, are much better, AND, you rely SO MUCH LESS on LORA, unless you're looking for a very specific thing, like particular facial features or something, and even then, the loras are usually not necessary.
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.