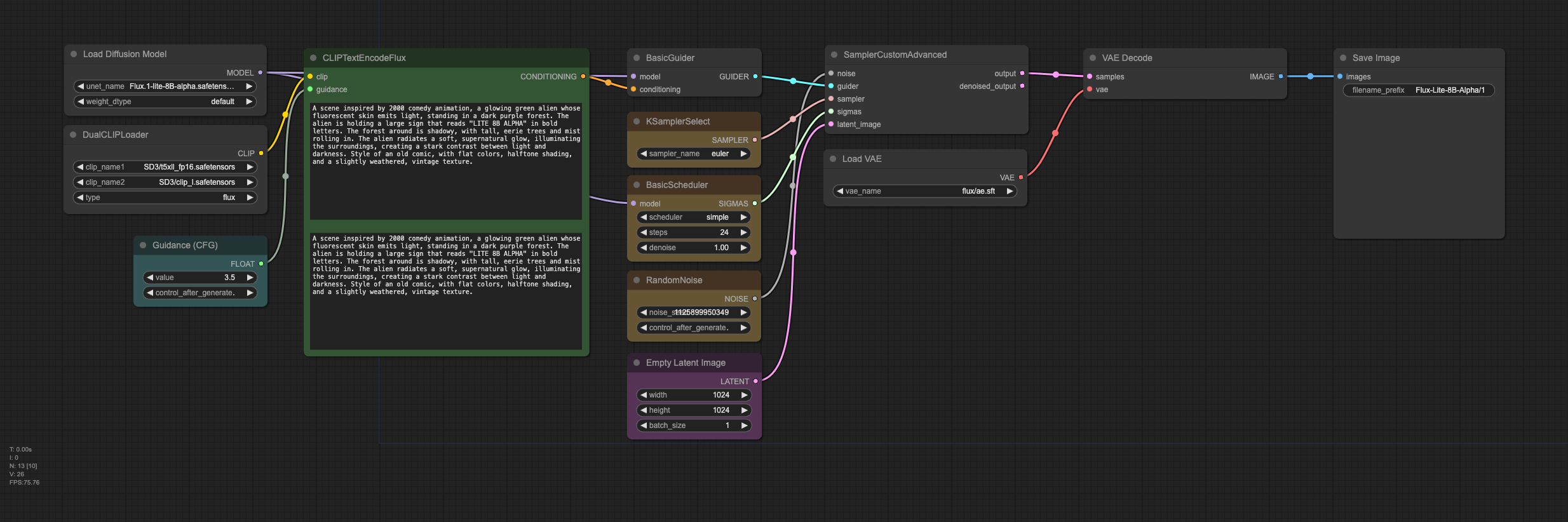
Source: https://huggingface.co/Freepik/flux.1-lite-8B-alpha from Freepik
The alpha release of Flux.1 Lite, an 8B parameter transformer model distilled from the FLUX.1-dev model. This version uses 7 GB less RAM and runs 23% faster while maintaining the same precision (bfloat16) as the original model. Download GGUF version here.
 ☕ Buy me a coffee: https://ko-fi.com/ralfingerai
☕ Buy me a coffee: https://ko-fi.com/ralfingerai
🍺 Join my discord: https://discord.com/invite/pAz4Bt3rqb
Description
FAQ
Comments (18)
Very interesting! Downloading and will test it right now!
Thank y ou for your work!
what vae I have to use with it?
what graphics card does it work for? and at what speed? can 8gb vram work?
If your PC has enough ram (24gb or so) it can run, just needs to offload it.. even 22gb models work on low vram GPUs, just requires a lot of system memory .. and time, cause its slower with offload to system memory.
Model doesnt have to be fully in GPU memory, but its a lot faster if it is.
nop 12GB is lilit - FLUX isnt that good yet ... you can still work witl SDXL an PONY ;)
Could you go a bit more into the process you've used? I see flux LoRAs working with it, and I would expect a distilled model to be utterly incompatible, as I believe dev and schnell are, for example.
Edit: Ah, I see it's more along the lines of smart layer-skipping. Cool.
error dont work in
WEBForge-UI ...
all 30 models iv donwlaoded working so fare including GGUFs, BNF4, DEV , Schnell
Its diffusion model, not sure what is webforge workflow for that, but it requires that.
You probably used checkpoint models only before, which is slightly different thing.
Also didn´t work with ForgeUI for me, but I attached a ComfyUI workflow
Image quality is really good. Model size is really big and LORA isnt really working, it loads part of it, not all of it and throws quite a few messages in comfyUI console.
But, I think its on a good way. Some smaller quant should give probably same quality as FP8 regular dev, which IMHO is a win.
Yea and its really fast.
The model ist the biggest gift for all of us that do not own a consumer grade tiny little RTX 4090 with 24GB VRAM since the release of the original Flux1.dev model.
It works like a charm for me in my standard ComfyUI workflow with each and every LORA I am using with it.
The model is very small when used right and really really fast.
CLIP encoders and the model fit perfectly in the VRAM of my RTX 4060TI and multiple LORAs are merged with the model on the fly while rendering the image. 20s rendering time per image was a dream before and now it is real.
You definetely should thank Ralfinger for hosting this model here and give it more than a try.
If you want, there are smaller quants on https://huggingface.co/city96/flux.1-lite-8B-alpha-gguf/tree/main .. but problem with LORA not really working right is still there, due shifted blocks. We could use some lora blocks patch setup to apply LORA correctly with this model, cause otherwise its really pretty good and fast model.
do you know if there is a reason why this version and also the gguf version of it completely ignores the conditioning of the controlnet?
so far results are pretty decent and shaved off 2 seconds (went from 12 to 10) of render time at lower vram use as well. so a good start. i wonder if it is easier to finetune?
12 seconds? I have 7 minutes!
Thank you so much for this art generative model, everything works really well. Finally I got good results locally. I have been experimenting for a long time with art-generative models online and locally on my computer. And finally found the optimal workflow! Thank the gods and RalFinger. If interested, I'll tell you in more detail how I used this model. Thanks again! Looking forward to the beta version of the model.
For some reason, details are lost. Prompt "Batman standing at the grave. Pencildrawing" in most cases does not draw the grave, only Batman. With other prompts, a decrease in details is also noticeable. Compared with the quantized dev on q3-q4