
Please see our Quickstart Guide to Stable Diffusion 3.5 for all the latest info!
Stable Diffusion 3.5 Medium is a Multimodal Diffusion Transformer with improvements (MMDiT-x) text-to-image model that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
Please note: This model is released under the Stability Community License. Visit Stability AI to learn or contact us for commercial licensing details.
Model Description
Developed by: Stability AI
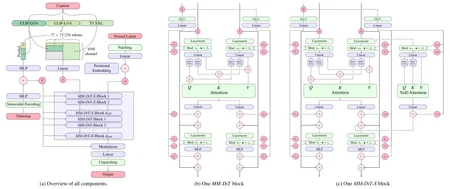
Model type: MMDiT-X text-to-image generative model
Model Description: This model generates images based on text prompts. It is a Multimodal Diffusion Transformer (https://arxiv.org/abs/2403.03206) with improvements that use three fixed, pretrained text encoders, with QK-normalization to improve training stability, and dual attention blocks in the first 12 transformer layers.
License
Community License: Free for research, non-commercial, and commercial use for organizations or individuals with less than $1M in total annual revenue. More details can be found in the Community License Agreement. Read more at https://stability.ai/license.
For individuals and organizations with annual revenue above $1M: please contact us to get an Enterprise License.
Implementation Details
MMDiT-X: Introduces self-attention modules in the first 13 layers of the transformer, enhancing multi-resolution generation and overall image coherence.
QK Normalization: Implements the QK normalization technique to improve training Stability.
Mixed-Resolution Training:
Progressive training stages: 256 → 512 → 768 → 1024 → 1440 resolution
The final stage included mixed-scale image training to boost multi-resolution generation performance
Extended positional embedding space to 384x384 (latent) at lower resolution stages
Employed random crop augmentation on positional embeddings to enhance transformer layer robustness across the entire range of mixed resolutions and aspect ratios. For example, given a 64x64 latent image, we add a randomly cropped 64x64 embedding from the 192x192 embedding space during training as the input to the x stream.
These enhancements collectively contribute to the model's improved performance in multi-resolution image generation, coherence, and adaptability across various text-to-image tasks.
Text Encoders:
CLIPs: OpenCLIP-ViT/G, CLIP-ViT/L, context length 77 tokens
T5: T5-xxl, context length 77/256 tokens at different stages of training
Training Data and Strategy:
This model was trained on a wide variety of data, including synthetic data and filtered publicly available data.
For more technical details of the original MMDiT architecture, please refer to the Research paper.
Usage & Limitations
While this model can handle long prompts, you may observe artifacts on the edge of generations when T5 tokens go over 256. Pay attention to the token limits when using this model in your workflow, and shortern prompts if artifacts becomes too obvious.
The medium model has a different training data distribution than the large model, so it may not respond to the same prompt similarly.
We recommended to sample with Skip Layer Guidance for better struture and anatomy coherency.
Description
Official Stability AI ComfyUI workflow for SD 3.5 Medium