




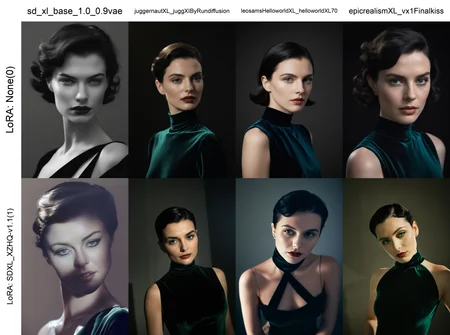


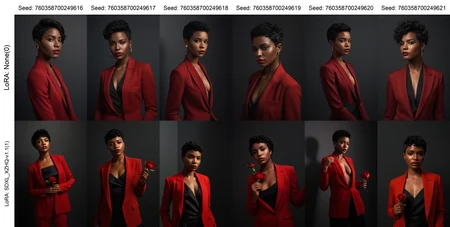

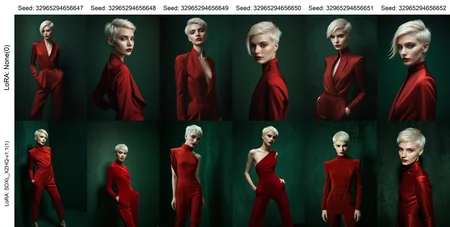

LoRA Details
Test tune of ~17K images trained at 1024x1024 with buckets using captions from CogFlorence-2.2 at batch size 4 for 4 epochs.
All images were manually filtered to the best of my ability to avoid low quality/watermarks/AI/etc.
All images are originally at least 1024x1024 total pixels.
Reason for creating this LoRA
I wanted to throw some fairly high quality but "general use-case" images at a model to use as a base so it can be further trained on more specific tasks in the future.
Description
This version does not contain much nudity, and may be biased towards women. I am working on increasing the dataset size and variety, and optimizing the training settings if needed.
There is a v1, but it was trained at batch size 1 for 1 epoch with the text encoder LR at half the amount v1.1 was trained at, so I don't feel it is worth publishing.
FAQ
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.