
















Capabilities
Widescreen & portrait up to 1536x1024 and 1024x1536
1920x1080 sometimes works, sometimes not. This is a limitation of pre-SDXL models' internal transformer architecture.
Photorealism - prompt with a year, a location, and a camera make.
Adventure - prompt coherence to allow silly requests.
Dark images - High guidance level with low CFG rescaling allows CRAZY dark images.
Bright images - Not bound to darkness like offset noise models, this terminal SNR prototype model is capable of producing pure white scenes.
Intentionally under-trained to allow additional fine-tuning.
Combine with textual inversions and see the true power of OpenCLIP!
No NSFW is trained into this model at all. It is family friendly.
Why it looks broken in Automatic1111?
Most of stable-diffusion-webui's samplers are unfortunately broken due to sampling from the leading timestep during inference. This is incongruent with the nature of training and inference in diffusion models:
During training, noise is added to a sample.
During inference, noise is removed from a sample.
When the noise addition ends during training, the instance is on the trailing timestep.
Most samplers start from the leading timestep, emulating a forward pass, rather than properly emulating the backwards pass.
Solution
Use DPM++ 2M sampler.
Install the A1111 extension for CFG (classifier-free guidance) rescaling
I find that higher CFG values around 7.5-9.5 produce stunning images, and a rescale of 0.0 allows the creation of very bright and very dark images.
However, if images appear over-contrasted or washed-out, you might need to up the CFG rescaling value to around 0.3 to 0.5. The maximum recommended value is 0.7, but this can result in washed-out images in a low-contrast manner.
Comparison vs 2.1-v and realism-engine:
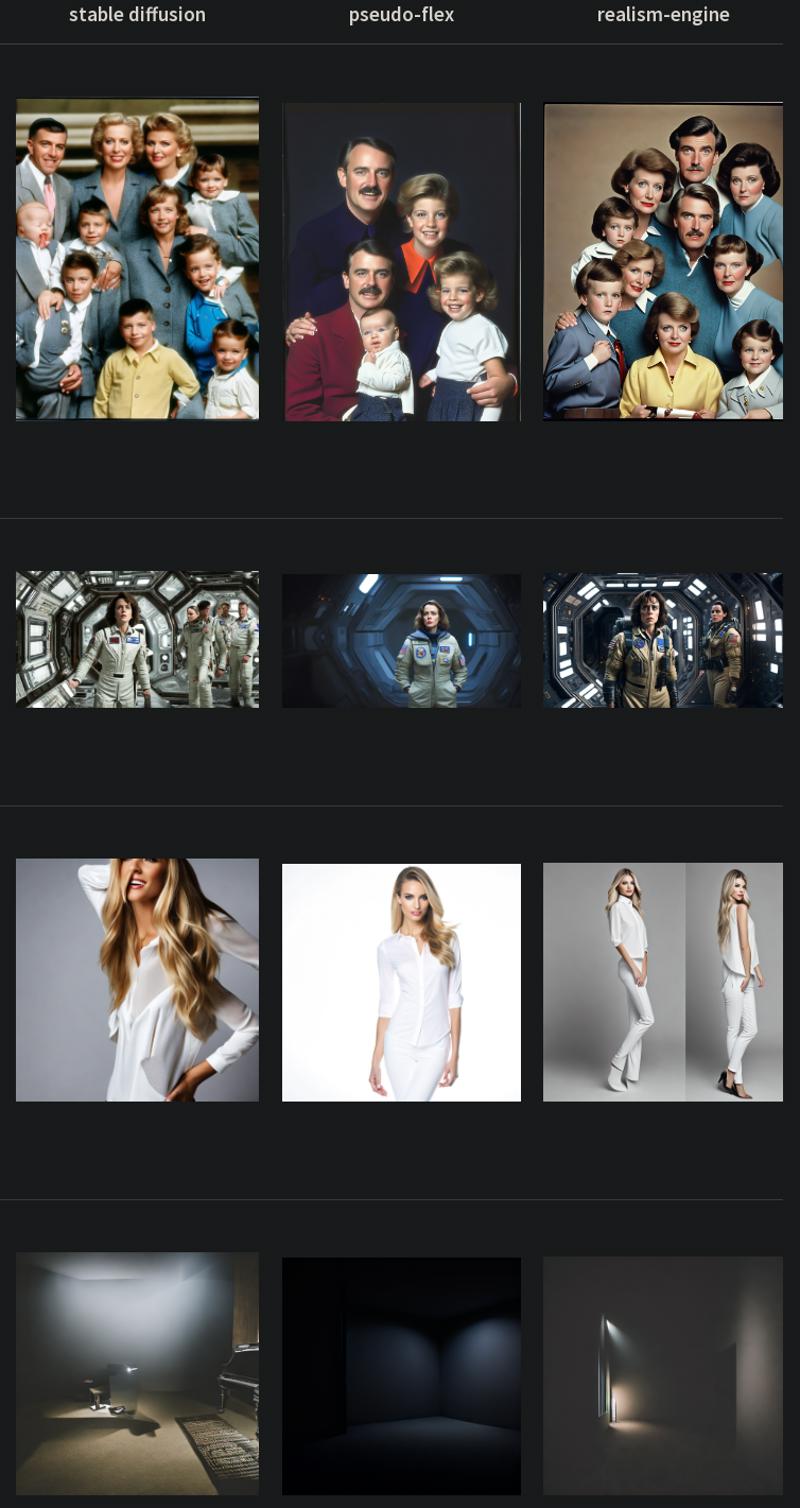
Training details
The original Huggingface Hub model card contains all information available on the training of this model.
Description
Batch size 150, training time 5 days for unet and 2 weeks for text encoder.
FAQ
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.