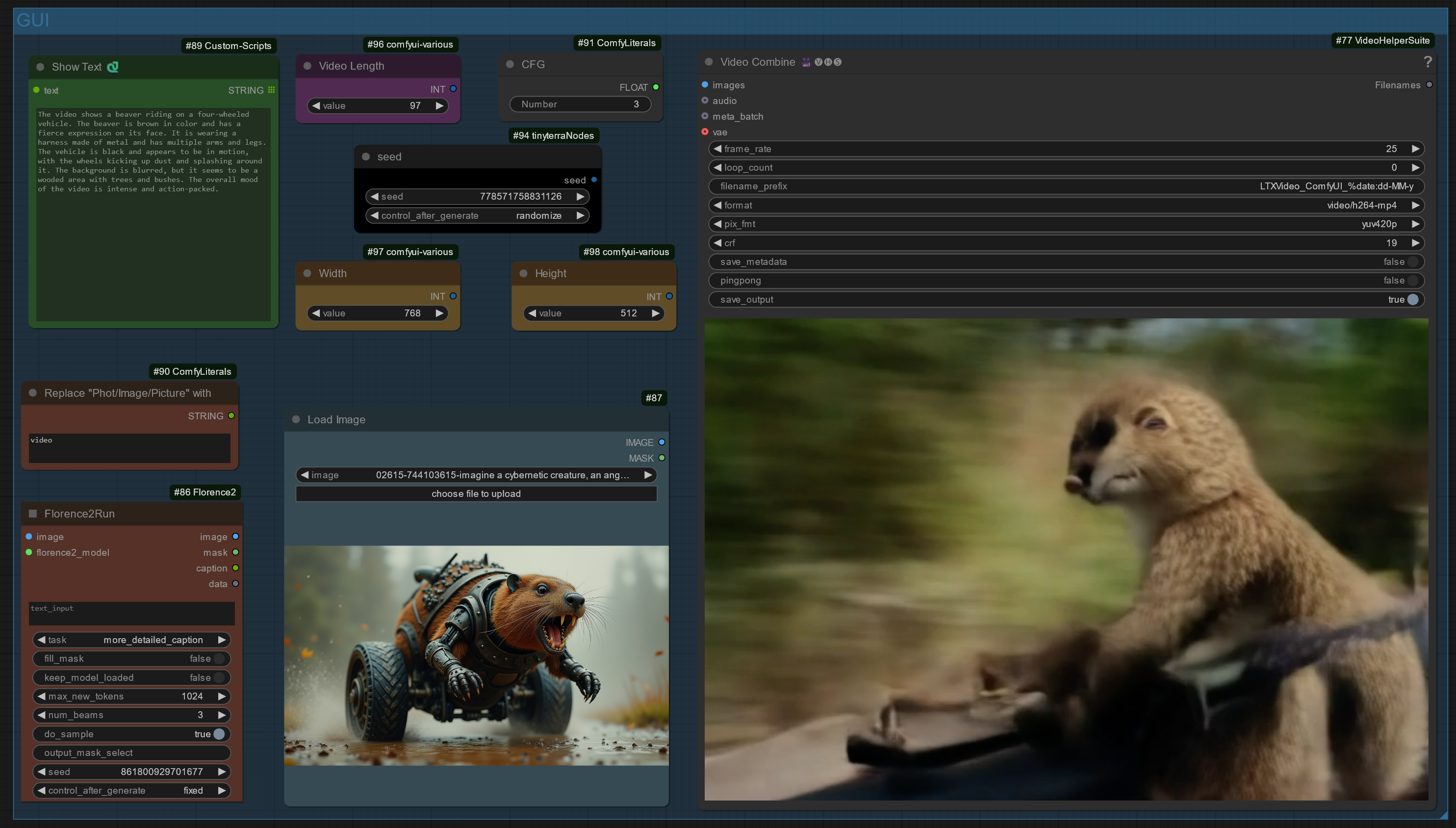

Workflow: Input Image (or prompt) -> captioning to a text prompt -> prompt is used for LTX TEXT to VIDEO (this is a Text to Video workflow, see my other workflow for Image to Video)
V5.0: Support for LTX 0.9.5 GGUF Models and Wavespeed/Teacache
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
Worklfow supports Florence caption and LTX Prompt enhancer and works with all models (0.9 / 0.9.1 / 0.9.5)
(see notes in workflow for more details)
V4.0: Support for GGUF Models
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
(includes a GGUF Version and a GGUF+TiledVae Version for low Vram)
V3.1: Support for model 0.9.1
V3.0: GUI Clean up, reduced no. of custom nodes, feature to use your own prompt.
V2.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
GUI includes two new nodes in blue:
STG settings, showing CFG, Scale and Rescale. Plus a switch to change between two layers of the model to be skipped (8 or 14 (default), chose "true" for layer 14 or "false" for layer 8)
I copied a note in the workflow with further info and usable values/limits. Feel free to experiment. In my testing, I kept the values within STG settings as default and just used the switch.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences.
V1.0: ComfyUI Workflow: LTX IMAGE-to-TEXT-to-VIDEO Using Florence2 Caption
This workflow transforms the input images into a prompt (Florence2 for captioning) and uses the LTX Text to Video model for video generation (Image -> Prompt -> Video)
Description
included a png file for easy drag and drop and added "steps" parameter to gui
FAQ
Comments (9)
Thank you, but i am stuck, IT question: I get alot undefined nodes in ComfyUi: When loading the graph, the following node types were not found:
DownloadAndLoadFlorence2Model
Florence2Run
Float
JWInteger
ttN seed
KepStringLiteral
The manager dont help..any thoughts? What to do when things are undefined?
Usually it helps to „Update All „, restart, then „Install missing nodes“, both in Comfyui Manager
@tremolo28 All up to date, missing customs nodes are still empty, anyways I wont bother you with this, thanks.
@Samsura same man
@loneillustrator. If "update all" and "install missing nodes" did not help, maybe check if you are on the right Chanel (Manager:Channel: default, is what I use). Other than that I can not realy support with comfyui related issues. I am kind of a comfyui noob myself ;)
how do you get it to pan in so slowly? I put slow pan and fast pan in the negative and it's still goes psycho on a very simple prompt
I just drag/drop a picture in the worklfow, the rest is done by the model/setup. Maybe try different seeds.
there seem to be different things which trigger movement : 1. seed : it seems to have the impact that, if lower , then slower (movement), or less movement.
2. max and min shift
3. cfg
4. frame_rate in conditionint (would'nt prefer that)
Ltx does not understand the word pan, nor scroll, nor follow, nor many other keywords. The camera follows the subject of the prompt(whatever is most detailed). Camera movement is nearly impossible to control beyond point at subject. Crop of your image can impact it but not enough to be reliable.