
**Don't forget to Like 👍 the model. ;)
SkyReels models link:
https://huggingface.co/Kijai/SkyReels-V1-Hunyuan_comfy/tree/main
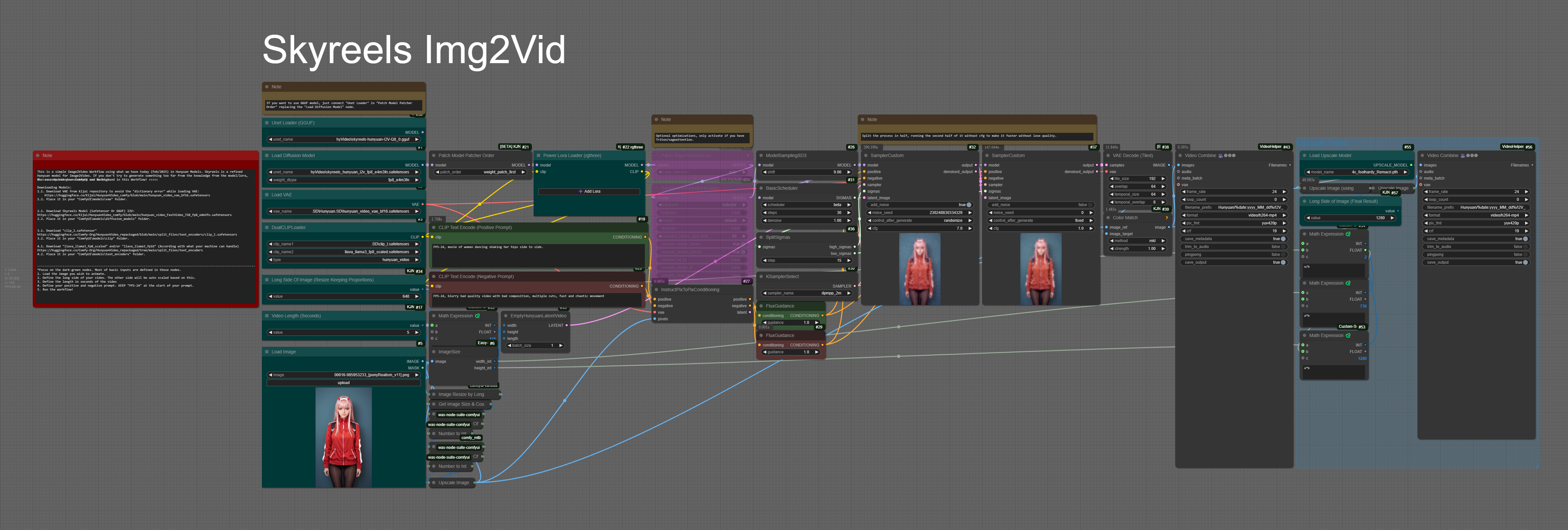
Straightforward and effective – this is an Image-to-Video workflow using the new Skyreels Img2Vid (Hunyuan refined) model!
Compared to the old Img2Vid LoRA workflow, this one delivers better quality, more consistency, and lower VRAM usage. In my opinion, it's a huge step forward – we're finally getting there!
As always, instructions and links are included in the workflow. Just make sure to update ComfyUI and the required nodes before running it!
That’s it. Leave a like and have fun! 🎥✨
Description
First Release
FAQ
Comments (73)
Thanks for creating this, will give it a try today. EDIT: I get an error for missing node torchcompilemodelhyvideo? EDIT2: Works well even with the error. Quality is excellent! Very slow to process, maybe will help to use Sage and Teacache?
I did not create. Haha. I just compiled in a "didatic" way!. You can install the missing node with manager easilly. If I got it right, the missing nodes will use Triton and sage to make the generation a little bit faster, the workflow will work without it as well. About the Speed, I believe they will make a "fast" lora, like with the original Hunyuan model, very soon. SO it will beocme faster.
Is it possible to use this workflow with 12GB of RAM? That is, without having to wait too long for each video.
It's possible with GGUF models and adjusting the size/length of the movie. About the speed generation, we can't do much for now I think. But soon they will comeup with a "fast" lora for this model for sure.
As someone with a RTX 4070 12gb, yes, i can use the fp8 model with torch compile and sage attention, (1min per second), however when trying to use a lora i get OOM. Luckily, the GGUF model allows to use them (without torch compile sadly) and their times seems to be the same
Avoid using the "Patch Weights Order" node, as it's the one causing the OOM error.
@ai_wifus yep is there some kind of a bug with that thing? im able to use loras without that node, but im not sure if they are working as intended
@Mikusha The "Patch Weights Order" is what makes the Loras being loaded with the model in the right way. If you'r enot using Loras, you can Bypass it (Ctrl+b), but if you're using Loras, you need it Enabled, or else you're just wasting memory. It's experimental, but I did not have any problems with it. I tried running it Enabled and Bypassed and it works the same for me.
I'm going through WFs daily now lmao. Not complaining. Thanks for having an Add lora node most do not include one!
Yeah! It's the first time I like the generation fomr a local I2V WF. And I'm using the Hunyuan loras in this. works great in my tests!
Well I gave it a shot. 4 hours ETA on the Sampler on a 4070 TI. lowered the steps to 20. Not going to work for me lol
@dkain76 4 hours? Something is wrong...
@Sam_A I'll try it again later after a reboot. I'm not having this issue on another WF using the skyreels Iv2 Q5 with GGUF. Only takes 15 minutes for it.
Yeah this is taking way too long even with GGUF for me. 1 hour and it's only like 6 steps out of 15
@Melty1989 Could you tell me your Vram % usage during the run? Also video length and image size (after workflow resize it)?
@Sam_A I should’ve mentioned more details. I’m on a 3080(10GB). Image size was 512 and length was 2 seconds
VRAM was 100% used
Edit : Doing a 2nd run now, with these settings:
Q8 GGUF
Long size of image 320
Video Length 2
Sageattention is installed
First sampler took 575 seconds to execute. By the time the 2nd finished (with upscaling), total time was 4505 seconds. Yeah, I'm not sure what's up with this workflow - but its definitely not optimized for low VRAM cards from what I've just witnessed.
@Melty1989 I think Q8 is too much for 10GB Vram. I would go with a smaller model.
@Sam_A I did try it with a Q6 as well. Still the same issue. Took like 1200 seconds.
In the original workflow I left the wrong link to safetensor and GGUF files, but I just fixed it and also added the link to the original post.
can it run with 10gb of vram?
no.
Yes. Using GGUF model, adjusting image size and video length.
I'm able to run it using skyreels-hunyuan-I2V-Q4_K_S.gguf on my 3080 10GB.
@hishiryo cool, how long it takes to generate one video?
@Rating_Agent Just tested it. 3 second video. 720x resolution. Took 915 seconds.
@hishiryo mine stuck at 79 %. i use 3080 too
@Rating_Agent Yeah, I do have some issues with things just slowing down a lot. Usually I restart ComfyUI and it fixes it.
Could be settings being too high too.
@hishiryo sent you a dm, maybe you can help me
it gives me this error
UnetLoaderGGUF
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]).
same problem
Update your comfy and nodes. It will only happen if you do not update your comfy.
@Sam_A I taught my comfy was up to date (12h "fresh") but after updating right now as you suggested it look like problem is solved, thanks!
@sivsuc Great! :D
This should be fixed in ComfyUI version 0.3.15. There's an issue in ComfyUI's GitHub issues list somewhere. I am on the previous version and simply made the small changes to the 3 files in this commit: https://github.com/comfyanonymous/ComfyUI/pull/6862/files ...That resolved this issue. I backed up the original files just in case, but the next update is only going to wipe them out anyway and the changes are small so you could revert them worst case.
"This setup is built on original ComfyUI nodes,"
well no. I had to install close to 10 custom nodes to run your workflow... I don't call that original or native nodes...
I tested and stopped the generation after more than 20 minutes as it felt stuck at 7%, sucking my CPU non stop...
I ran the SAME generation with this workflow (same model, etc.): https://github.com/comfyanonymous/ComfyUI/pull/6862 And it took less than 8 minutes to complete. And using about 10GB less VRAM (with yours I go up to 20~23 GB of VRAM used).
I'm not sure what is so "fast" about your setup. Except the fact than you can load a LoRA, it does nothing better except slowing shit down to a crawl so much that you don't want to wait for it to finish. EDIT: 1020 seconds. Finally finished. But no video in the UI, nor in the hard drive... wtf.
You're obviously doing something wrong. Probably in video length or image size. You should learn some respect before comment on internet. But unlike you, I will be polite and try to help with your problem. The generation uses exactly the same nodes of the example you used, so the input data is different 100%. The original workflow was configured to be used with around 20GB. to use less Vram you need to use your brain and reduce the specs according with your need. Now tell me, the length of the videos in both generations and the output image size you picked in both generations?
When loading the graph, the following node types were not found
Int To Number (mtb)
Label (rgthree)
Power Lora Loader (rgthree)
Use the manager to install it. Those nodes are used to auto resize the image, so you don't need to calculate stuff.
wont run past first 3 boxes
Could you please be more specific?
try click on file names in these boxes and reselect them
then your pc has low vram
If you are running into a size mismatch error, there's a GitHub issue discussing that somewhere in ComfyUI's GitHub issues. The latest version 0.3.15 should have a fix. For whatever reason ComfyUI desktop didn't update to the last, but on version 0.3.14, I was able to copy the changes to 3 files from this commit: https://github.com/comfyanonymous/ComfyUI/pull/6862/files and then things worked. You could just try to make sure you have the latest version of ComfyUI or wait a while until some of the issues are worked out.
just required comfy update
I don't know why but this gives me OOM's out of the wazoo. I ended up adapting my own workflow using bits from this (the math scaling of the initial image mostly) and now I get good results around 640x 129 frames (sometimes even 720x on a 4060 Super). I have not integrated the upscaler at the end of the generation yet which may be the reason why your workflow OOM's on me. Not sure. Further testing is required.
The TorchCompileModelHyVideo node will not stop being red no matter how much I try to update it through the manager. Any ideas?
You don't need to use this node unless if you have triton installed. This is just one method to accelerate the generation I left in the workflow, but it's optional. If you want to install it, you can do using the manager.
Would you consider adding the "Enhance A Video" node? Kijai says on the github that it's a win-win. Thanks
Yes. I have it in my other workflow, but it does not fit in here, It's part of the VideoWrapper nodes and only connects with it. I wish I could use it in this workflow. They will probably create something soon.
For anyone interested in the speed of this workflow/skyreels, I'm on an RTX 3090 24gb, im using the Q4 gguf model, i left everything as default and without upscaling, the generation of a 4 second clip took me around 15 minutes
If you're running with 24gb Vram, you can use bf16 and it will not make so much difference on generation speed but will have better quality. Also, if you use Sage you can cut the time in HALF. If you try to run another workflow with the same settings (video length and latent size), but without using the half sampling method used in this workflow, the generation will take 25% more time. Also one more detail. The time depends on how many steps you take. With 20 steps you can already generate something descent. My original workflow is configured to use 30, but you can reduce to save time. But yeah. From my tests in terms of speed:
Hunyuan > SkyReels > HunyuanFast model.
I waiting for Skyreels fast model. If it works like Hunyuan fast model, the generation time will go down drasticaly! :D
@Sam_A Still I havent figure out the reason why this workflow is drastically more time consuming than kijais native node wf. On a 4070 12GB u cant run it. The small ggufs are not giving a decent output. But fp8 which I use in many other wfs shows 1.800secs per it
@sikasolutionsworldwide709 You will noe believe it, but there is a node called "Large Size of Image". If you reduce it to 512, like most of the workflows, the speed will be normal like any other workflow. It's in instructions. Bogher size of output means longer time processing. lol
It's all about input settings. I forgot to set it down before posting the workflow, but i tested it in 3060, 4070, 4090 and harld no proboems, as long as I respect the GPU capacity of processing. I ensire you, if you reduce the "large size of image" to 512 it will be fast like any other workflow.
@Sam_A I have figured out that the main issue is the "patch model patcher order node" which has no effect. I have tested the output with and w/out on gguf Q8. Furthermore I recommend to resize the chosen input picture near to the chosen basic res and aspect ratio in the workflow. I also changed the image resize/input nodes for more flexibility.
@sikasolutionsworldwide709 This is crazy. For some people the "patch model patcher order node" is causing problems. This node is what makes Loras load in the "right order", but if you'r enot using Loras and if the node is cuasing problems, you can bypass it without problems. I tested it in 3 different machinnes and had no problems. About resolution, yeah. In a 4090 I use it as high as I can, but with 12gb Vram, I reduce the resolution to a little bit above 512 and use upscaler to got up to 1280p, and then Topaz it.
@Sam_A I will upload my output including the wf later, currenty I am workin on the final upscale procedure. 432x632 output is similar to urs bClip and model fp8, gentime 1.435 secs. As for loras the rgthree works very well much better than a row of double blocks loaders
Hello. Stop at "HunyuanVideo Sampler" no error nothing
"got prompt
Failed to validate prompt for output 12:
* HyVideoSampler 6:
- Return type mismatch between linked nodes: context_options, received_type(FETAARGS) mismatch input_type(HYVIDCONTEXT)
Output will be ignored
Prompt executed in 0.02 seconds"
Weird, because there is no this node in the workflow.
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]).
This error is caused because your comfyui is not updated. It's the first item in the instructions. Update it and it will work.
This is how to fix it. People keep saying just update comfy, I've updated everything and it still was not working.. the only solution is the following, this did work. But you need to manually update 3 files yourself.
I had the same issue too - everything appeared to be updated etc. There was probably a more elegant solution somewhere, but fixed it by downloading and replacing these 3 files from the comfyui github here: https://github.com/comfyanonymous/ComfyUI/pull/6862/files我也遇到了同样的问题 - 所有内容似乎都已更新等。某个地方可能有一个更优雅的解决方案,但通过从 comfyui github 下载并替换这 3 个文件来修复它:https://github.com/comfyanonymous/ComfyUI/pull/6862/files
the link is lost, can you provide it again? Thanks!
https://github.com/comfyanonymous/ComfyUI/pull/6862/files
this fixed it for me thanks
Trying to understand your workflow.. I guess the image is being reduced to smaller size so there enough vram to process it. how do you control this ? Is there a simple way to set the reduction factor.
There is a node called Large size of image or something like that. It's in the instructions. The big red note at left of the workflow.
Is it possible make perfectly loop animation with skyreels?
I tried the 201 frames trick, but it didn't work for me like ot does with original hunyuan.
@Sam_A Haha yeah, i know about this trick, it doesn't work for skyreels. That why i asked, any other options for loop animation with a skyreels?
@pitkevich Well... Not that I know. I wish... Haha
@Sam_A Also hope it will able with wan 2.1 also ;)
@pitkevich To be honest, I don't think it will :\
Got it working on 4090. Quality is really good but 36 minutes for five seconds is still pretty long. Tried using sageattention and triton (both installed under windows) to speed things up and got this error during triton compile:
"Feature 'cvt with .e4m3x2/.e5m2x2' requires .target sm_90 or higher"
This means it won't compile on Ada cards (aka 40 series) but requires Hopper architecture.
Do you have any means of changing this requirement of the workflow to sm_89 Ada architecture? Thx
EDIT: Using sageattention alone brings render time down to 16 minutes but the result is complete hallucination.
It's weird. I'm using a 4090 and the sampling time is around 8 minutes with a 720p 5s video. I use only Sage btw. What is the size of the image you're trying to use?
Am lost have this error message anyone know the answer to this
SamplerCustom
Given groups=1, weight of size [3072, 16, 1, 2, 2], expected input[1, 32, 31, 80, 56] to have 16 channels, but got 32 channels instead
Update your comfyui and the nodes. This error is because your comfy is not updated.