




ReVisionXL - Comfyui Workflow
**Make sure to update your comfyui before using this workflow as it is new**
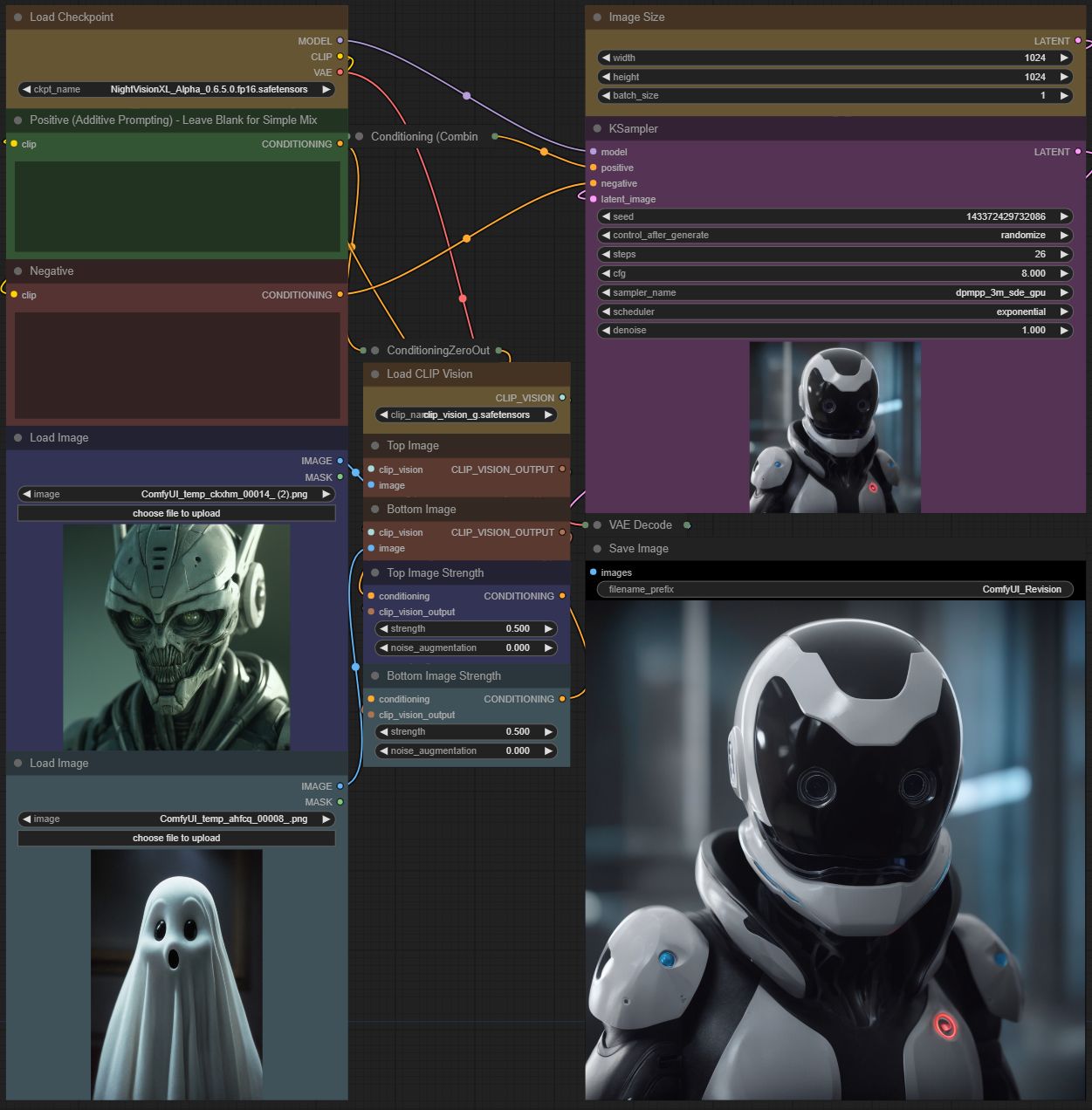
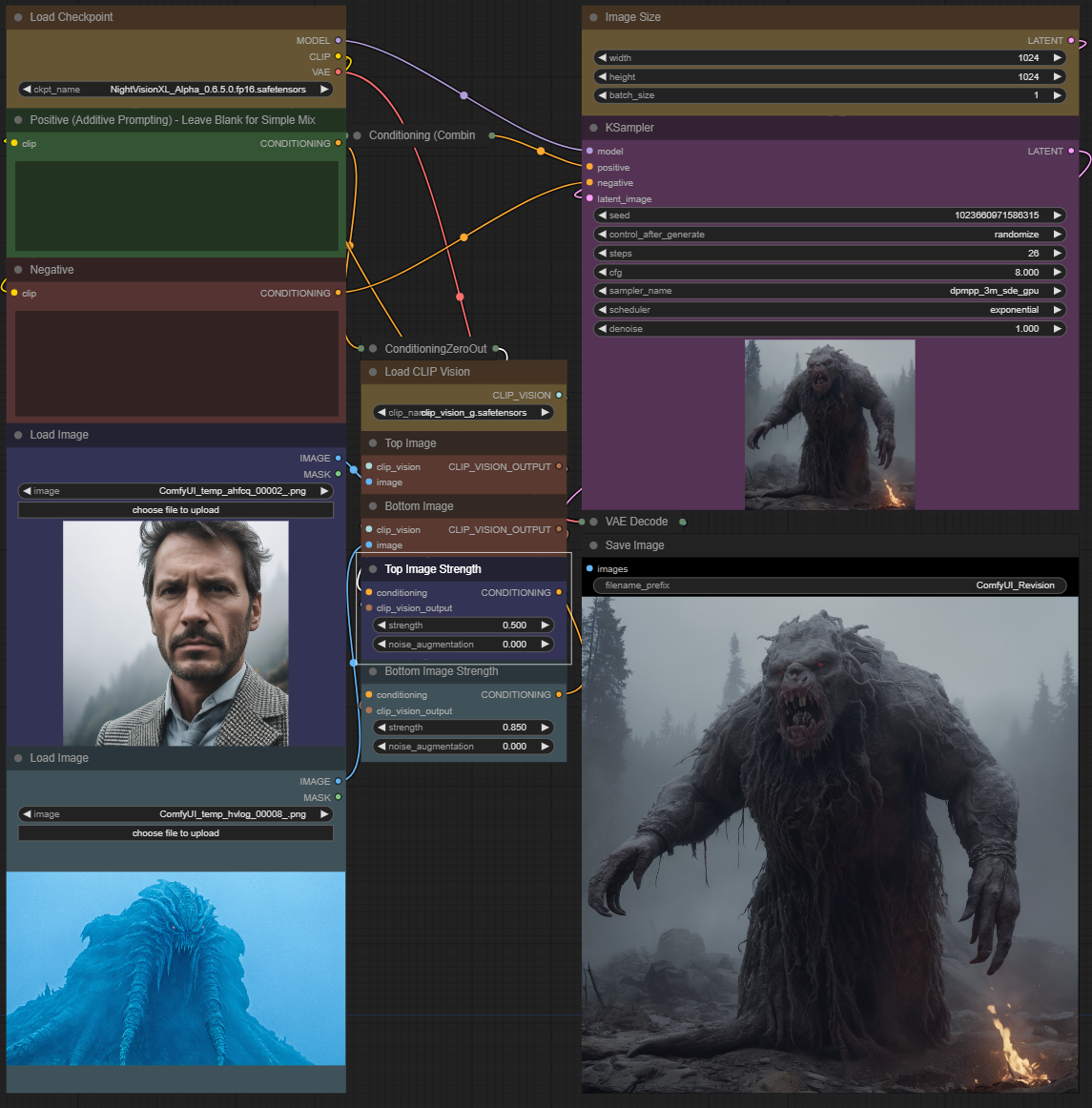
ReVision is a new technique implemented into comfyui that allows you to take 2 different images, and use the new Clip_vision_g to mix the elements of each picture into 1 new picture!
Here is the link to find Clip_Vision_G model:
https://huggingface.co/stabilityai/control-lora/blob/main/revision/clip_vision_g.safetensors
Put the model in your Comfyui/models/clip_vision Directory.
With this workflow you have the option to use the prompt boxes or not youll get an image either way. Do be warned that using the prompt boxes may make your image very greatly.
Adjusting the top image strength and bottom image strength will result in taking the elements of one image higher than the other. Feel free to experiment as it is very new!
Have fun!
Description
Added ReVision Workflow
FAQ
Comments (5)
In case anyone is getting errors, be sure to update ComfyUI to the latest version.
Hello, I have completed the installation and there are no missing nodes, but there is an issue. The generated images are completely unrelated to the two imported images
@wyxzddsjj919 hi, ive had that heppen with a couple models. some models seem to respond better than others to the clip vision. same goes for pictures. if all else fails try to describe exactly what you want in the positive prompt. clip vision takes elements of both images and combines them into something completely different and sometimes gives unexpected results.
@viakole Thank you for your help. I went to RED to check the data. some people pointed out that COMFUI installed FOOCus, so just uninstall it ~
:(
Error occurred when executing CLIPVisionLoader: Error while deserializing header: HeaderTooLarge File "D:\Stable_Diffusion\ComFyUI\ComfyUI\execution.py", line 151, in recursive_execute output_data, output_ui = get_output_data(obj, input_data_all) File "D:\Stable_Diffusion\ComFyUI\ComfyUI\execution.py", line 81, in get_output_data return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True) File "D:\Stable_Diffusion\ComFyUI\ComfyUI\execution.py", line 74, in map_node_over_list results.append(getattr(obj, func)(**slice_dict(input_data_all, i))) File "D:\Stable_Diffusion\ComFyUI\ComfyUI\nodes.py", line 727, in load_clip clip_vision = comfy.clip_vision.load(clip_path) File "D:\Stable_Diffusion\ComFyUI\ComfyUI\comfy\clip_vision.py", line 78, in load sd = load_torch_file(ckpt_path) File "D:\Stable_Diffusion\ComFyUI\ComfyUI\comfy\utils.py", line 11, in load_torch_file sd = safetensors.torch.load_file(ckpt, device=device.type) File "D:\Stable_Diffusion\ComFyUI\python_embeded\lib\site-packages\safetensors\torch.py", line 308, in load_file with safe_open(filename, framework="pt", device=device) as f: