
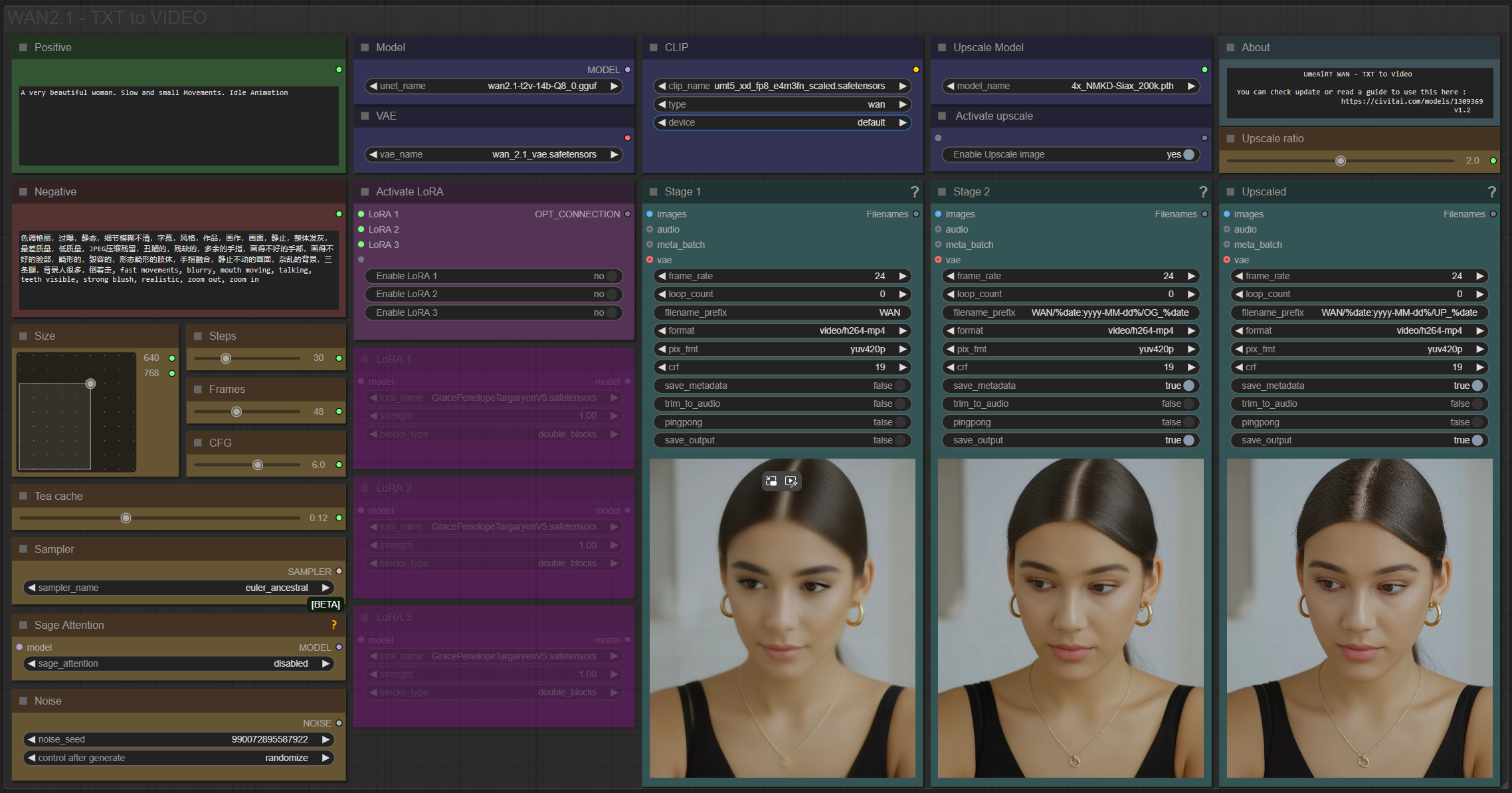
Description:
This workflow allows you to generate video from text.
You will find a step-by-step guide to using this workflow here: link
My other workflows for WAN: link
Resources you need:
📂Files :
For base version
T2V Model: fp16, fp8
In models/diffusion_models
For GGUF version
T2V Quant Model: Q8, Q5, Q3
In models/diffusion_models
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
📦Custom Nodes :

Description
Bugfix : path for windows
Update : New teacache node, UI adjustment
Testing : No group node to maximise missing node detection
FAQ
Comments (4)
Hi, All other error corrected but now it said
Unexpected architecture type in GGUF file, expected one of flux, sd1, sdxl, t5encoder but got 'wan'
This means your ComfyUI is not up to date.
@UmeAiRT Thanks a lot dear. Your Suggestion worked.
Thanks a lot for amazing workflow. Working on 8gb gpu