




Flux fix Update - 7/2/25 - evening:
There was a bug with the Flux loader for t5xxl, so I jiggered it and got it working for todays evening push.
Will likely need to do something similar for SD3 and SD35 as well.
Workflow Release - 7/2/25 - morning:
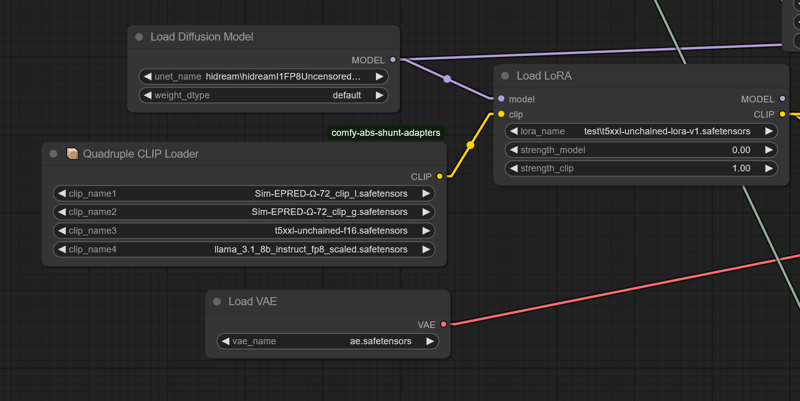
Current workflow requires the comfy-clip-shunts node addon. You don't NEED to use the shunts, but it comes with the clip loaders that support the t5-unchained.
These loaders work BECAUSE they essentially replace the original sd function calls with function calls directly linking utilization.
For the shunts, you can use standard bert uncased or bert cased, instead of beatrix but the results won't be as accurate.
Shunt code with unchained.
https://github.com/AbstractEyes/comfy-clip-shunts/tree/dev
Full untrained unchained model:
https://huggingface.co/AbstractPhil/t5xxl-unchained
I have a ton of clips loaded here. The omega 24's are very good for this, since they're closer to the original vit-l-14 and laion vit-bigG.
https://huggingface.co/AbstractPhil/clips
Augmented and improved by res4lyf, I would suggest installing it.
https://github.com/ClownsharkBatwing/RES4LYF
Special thanks to Kaoru8 for their base t5xxl-unchained conversion and repo. It doesn't have any additional training on top of the base T5, but it's converted and the training that I fed it with clearly works.
https://huggingface.co/Kaoru8/T5XXL-Unchained
Not bad... a fair working sd35 prototype in a week.
By this time next week I hope to have the Flux variation fully operational and the clip suite in prototype stages.
I genuinely need some time to rest. This was very taxing on my mental health it seems, so I'm going to take some time to recover and regenerate.
I'm going to take time to work on my tools and do smaller finetunes rather than full finetunes. These larger finetunes are expensive and very taxing on the body and mind when the programs don't function correctly.
Yes this is a T5 lora. It's treated as though the T5xxl's lora_te3 is the "T5xxl" text encoder. I've extracted the lora_te3 layers from the original sd35 trained lora and resaved. Simple process really, no telling what sort of defectiveness it has. I doubt it'll load in anything but comfyui or forge, but here it is.
You can have a conversation with the loaded T5xxl-unchained with the lora weights applied; using standard LLM inference if you like. It'll summarize pretty well.
800 meg lora. The process is a lot easier than I thought it would be.
https://huggingface.co/AbstractPhil/SD35-SIM-V1/tree/main/REFIT-V1
from safetensors.torch import load_file, save_file
# Load the safetensors model
input_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/sd35-sim-v1-t5-refit-v2-Try2-e3-step00003000.safetensors"
output_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/t5xxl-unchained-lora-v1.safetensors"
model = load_file(input_path)
# Filter out TE1 and TE2 tensors
filtered = {k: v for k, v in model.items() if not (k.startswith("lora_te1") or k.startswith("lora_te2") or k.startswith("lora_unet")) }
print(f"Filtered out {len(model) - len(filtered)} tensors.")
print(f"Remaining tensors: {filtered.keys()}")
# Save result
save_file(filtered, output_path)
print(f"✅ Saved cleaned model without TE1/TE2 tensors to:\n{output_path}")
Rip them yourself if you want. The newest T5 is still training.
Requires the correct tokenizer and config for the T5xxl and the T5xxl model weights to function.
Without the base t5xxl-unchained, tokenizer, and correct dimensions configuration; you will receive a size mismatch error.
You need the big ass T5xxl fp16 or fp8. It was trained in fp16 so you'll get better results from the finetune with it. You can probably just tell comfyui or forge to downscale it.
https://huggingface.co/AbstractPhil/t5xxl-unchained/resolve/main/t5xxl-unchained-f16.safetensors
When the clip-suite is ready, it'll automatically scale in program and allow hardware-level quantization hot-conversion (Q2, Q4, Q8, etc) utilization, and saving within ComfyUI.
At that point you'll only need one model and everything will just convert at runtime using the META C++ libs.
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/config.json
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/tokenizer.json
To modify Forge you can swap these files with the ones at the address; the only exception being the sd3_conds.py needing a direct modification to the template contained within code.
Make a backup of the original configs if you want. It doesn't matter though. The t5xxl-unchained in it's vanilla form behaves identically to the original t5xxl.
------------------------------------------------------------------------
configs
------------------------------------------------------------------------
modules/models/sd3/sd3_conds.py
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/text_encoder_3
backend/huggingface/black-forest-labs/FLUX.1-dev/text_encoder_2/config.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/text_encoder_2/config.json
-------------------------------------------------------------------------
tokenizers
-------------------------------------------------------------------------
backend/huggingface/black-forest-labs/FLUX.1-dev/tokenizer_2/tokenizer.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/tokenizer_2/tokenizer.json
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/tokenizer_3/tokenizer.jsonDescription
This is a T5xxl exclusive lora that can be loaded into comfyui; the first of it's kind - tested with the most recent version of comfyui with the t5xxl loaded with the triple clip loader. The only weights that exist are based on the T5xxl.
It will work with any T5xxl based model; assuming the T5xxl unchained does work.
The effect on the standard T5 is undocumented and untested; so I wouldn't advise playing with fire.
FAQ
Comments (18)
Wow, amazing
config.json
tokenizer.json
Using forge, what are the correct paths for these two files?
modules/models/sd3/sd3_conds.py
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/text_encoder_3
backend/huggingface/black-forest-labs/FLUX.1-dev/text_encoder_2/config.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/text_encoder_2/config.json
backend/huggingface/black-forest-labs/FLUX.1-dev/tokenizer_2/tokenizer.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/tokenizer_2/tokenizer.json
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/tokenizer_3/tokenizer.json
Can this LoRA be used in the basic image generation workflow of FLUX dev? Because I keep getting random images when using this LoRA (strength 1.0). Could you explain how to use it correctly in ComfyUI within a standard workflow?
Try around strength 0.3 to 0.5 give or take. It's an experiment, so it's not guaranteed to work yet.
Getting a full professional workflow ready will require a sd3 style shift embedded in a flux 1d lora variation baked into the lora, and I haven't figured out the exact math yet. So bare with it for now; experimental.
I'll get it going soon enough. All the models will have an adapter soon enough with a really easy to use interface.
SD35M has dual layers; which is likely some behavior I'll need to unlearn from the T5 as they learned side-by-side, but it's definitely much closer to where it needs to be. This is very doable as I have many prototypes now. SD35M and Flux1D both have dual layers; so the trajectory learning based on SD35 is likely affecting the dual layer responses of the Flux1D.
It may need a couple million samples of direct learning from flux as well; but we'll see. That's pretty fast if I just have the flux frozen. In any case, there will be a much better prototype by this time next week that will fit better to the goals.
The clip-suite that I'm developing will be plug-n-play for many forms of the T5 and LLMS, so you'll know immediately if things work or if they catch fire and I need to hear about it.
I was thinking; it's equally possible that the tokenizer somehow failed in the program. I'm giving you the benefit of the doubt, but it's still not controlled enough yet for me to be 100% certain and pull the trigger on the adapters until the suite is up and operational.
I want to be able to clean install comfyui manager, and then the clip-suite from a base comfyui. Then I can be certain of all elements for installation and utilization; to make sure everything is within parity and orderly.
Once I can without a doubt load and match the outputs from the suite in the same way as the base version's jury rigged variation, then I can be certain that problems are happening in sync or problems are happening from external input.
Alright a little tinkering;
Load flux normally
Set lora to 0.71539 or just 0.71 or 0.72
res4lyf is the sampler pack you'll want.
disable flux guidance
20 steps
1.0 cfg
res_2s_sde
1024x1024
I'll make a proper workflow after work.
Thanks for sharing, keep up the research work <3
After this train I'm halting big trains for a bit. Flux and the T5 full refit is going to take time to set up and I need time to breathe.
@AbstractPhila Yeah, makes sense! Super interesting stuff, but personal health and well-being is equally important :D
What does this LoRA do exactly? I couldn't really understand.
It's a T5 unchained train with a million images ran for 4 epochs. It updates it's new tokens to be more compliant with big training and lora fitting.
@AbstractPhila So it makes Flux follow my prompts better?
This had much more impact than I imagined. Nice work.
what this even do ? it need special t5xxl to work with ?
That's what 2.7 million steps will do.
Hi. How do we use this in ComfyUI portable? Do I just load the LoRA in my workflows or do I need to do other work beforehand to make this LoRA work properly? Thanks!
Indev today. I'm getting it working. It'll be in the repo;
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.