
Flux fix Update - 7/2/25 - evening:
There was a bug with the Flux loader for t5xxl, so I jiggered it and got it working for todays evening push.
Will likely need to do something similar for SD3 and SD35 as well.
Workflow Release - 7/2/25 - morning:
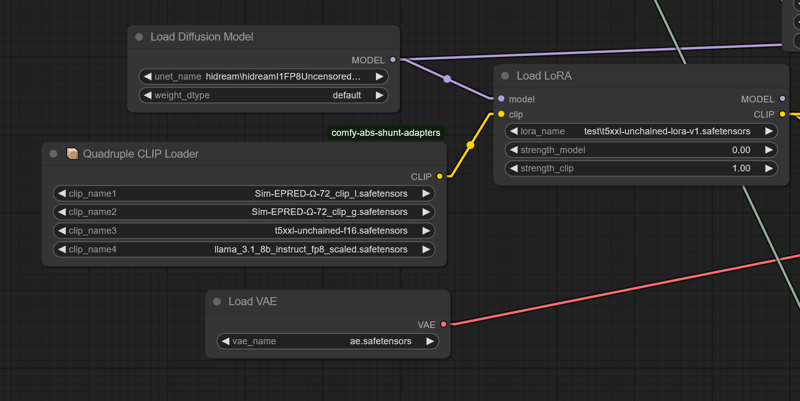
Current workflow requires the comfy-clip-shunts node addon. You don't NEED to use the shunts, but it comes with the clip loaders that support the t5-unchained.
These loaders work BECAUSE they essentially replace the original sd function calls with function calls directly linking utilization.
For the shunts, you can use standard bert uncased or bert cased, instead of beatrix but the results won't be as accurate.
Shunt code with unchained.
https://github.com/AbstractEyes/comfy-clip-shunts/tree/dev
Full untrained unchained model:
https://huggingface.co/AbstractPhil/t5xxl-unchained
I have a ton of clips loaded here. The omega 24's are very good for this, since they're closer to the original vit-l-14 and laion vit-bigG.
https://huggingface.co/AbstractPhil/clips
Augmented and improved by res4lyf, I would suggest installing it.
https://github.com/ClownsharkBatwing/RES4LYF
Special thanks to Kaoru8 for their base t5xxl-unchained conversion and repo. It doesn't have any additional training on top of the base T5, but it's converted and the training that I fed it with clearly works.
https://huggingface.co/Kaoru8/T5XXL-Unchained
Not bad... a fair working sd35 prototype in a week.
By this time next week I hope to have the Flux variation fully operational and the clip suite in prototype stages.
I genuinely need some time to rest. This was very taxing on my mental health it seems, so I'm going to take some time to recover and regenerate.
I'm going to take time to work on my tools and do smaller finetunes rather than full finetunes. These larger finetunes are expensive and very taxing on the body and mind when the programs don't function correctly.
Yes this is a T5 lora. It's treated as though the T5xxl's lora_te3 is the "T5xxl" text encoder. I've extracted the lora_te3 layers from the original sd35 trained lora and resaved. Simple process really, no telling what sort of defectiveness it has. I doubt it'll load in anything but comfyui or forge, but here it is.
You can have a conversation with the loaded T5xxl-unchained with the lora weights applied; using standard LLM inference if you like. It'll summarize pretty well.
800 meg lora. The process is a lot easier than I thought it would be.
https://huggingface.co/AbstractPhil/SD35-SIM-V1/tree/main/REFIT-V1
from safetensors.torch import load_file, save_file
# Load the safetensors model
input_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/sd35-sim-v1-t5-refit-v2-Try2-e3-step00003000.safetensors"
output_path = "I:/AIImageGen/AUTOMATIC1111/stable-diffusion-webui/models/Lora/test/t5xxl-unchained-lora-v1.safetensors"
model = load_file(input_path)
# Filter out TE1 and TE2 tensors
filtered = {k: v for k, v in model.items() if not (k.startswith("lora_te1") or k.startswith("lora_te2") or k.startswith("lora_unet")) }
print(f"Filtered out {len(model) - len(filtered)} tensors.")
print(f"Remaining tensors: {filtered.keys()}")
# Save result
save_file(filtered, output_path)
print(f"✅ Saved cleaned model without TE1/TE2 tensors to:\n{output_path}")
Rip them yourself if you want. The newest T5 is still training.
Requires the correct tokenizer and config for the T5xxl and the T5xxl model weights to function.
Without the base t5xxl-unchained, tokenizer, and correct dimensions configuration; you will receive a size mismatch error.
You need the big ass T5xxl fp16 or fp8. It was trained in fp16 so you'll get better results from the finetune with it. You can probably just tell comfyui or forge to downscale it.
https://huggingface.co/AbstractPhil/t5xxl-unchained/resolve/main/t5xxl-unchained-f16.safetensors
When the clip-suite is ready, it'll automatically scale in program and allow hardware-level quantization hot-conversion (Q2, Q4, Q8, etc) utilization, and saving within ComfyUI.
At that point you'll only need one model and everything will just convert at runtime using the META C++ libs.
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/config.json
https://huggingface.co/AbstractPhil/t5xxl-unchained/blob/main/tokenizer.json
To modify Forge you can swap these files with the ones at the address; the only exception being the sd3_conds.py needing a direct modification to the template contained within code.
Make a backup of the original configs if you want. It doesn't matter though. The t5xxl-unchained in it's vanilla form behaves identically to the original t5xxl.
------------------------------------------------------------------------
configs
------------------------------------------------------------------------
modules/models/sd3/sd3_conds.py
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/text_encoder_3
backend/huggingface/black-forest-labs/FLUX.1-dev/text_encoder_2/config.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/text_encoder_2/config.json
-------------------------------------------------------------------------
tokenizers
-------------------------------------------------------------------------
backend/huggingface/black-forest-labs/FLUX.1-dev/tokenizer_2/tokenizer.json
backend/huggingface/black-forest-labs/FLUX.1-schnell/tokenizer_2/tokenizer.json
backend/huggingface/stabilityai/stable-diffusion-3-medium-diffusers/tokenizer_3/tokenizer.jsonDescription
This is the shunts workflow meant to make the t5xxl unchained work.
FAQ
Comments (22)
This is interesting. Do I want to use the full untrained unchained clip in the clip loader as well as the lora or just the lora?
You need the untrained unchained as well as the other, since the untrained one is prepped but not trained yet.
@AbstractPhila thank you, will give it a go
@EricRollei21 Good luck. It'll likely get a real finetune soon, so stay tuned for the unchained upgrade.
@AbstractPhila Awesome! Will do.
AbstractPhila Any update? I’m excited to check out unchained. I’m confused why people aren’t talking about it more
You've done a great job. Take care of yourself.
Could you kindly provide me with the GITHUB addresses of the node packages to which the following nodes belong in the workflow?
"Beatrix Assignment"
"AquadrupleCLIPLoader"
"EncoderLoader"
"prompt”
"Beatrix Omission"
I have already installed it
https://github.com/AbstractEyes/comfy-clip-shunts/
https://github.com/ClownsharkBatwing/RES4LYF
These two node packages still indicate that the five nodes mentioned above are missing. Thank you very much if you could let me know!
The problem has been solved. Simply switch "comfy-clip-shunts" to the DEV branch
lzhfdwu007 DEV is the more stable dev but not fully stable, and dev2_electric_boogaloo is the less stable progression with an additional formula added named "Rose Similarity"; the math based entirely on a multi-stage similarity augmentation system.
Rose similarity has shown both additional rigidity and additional solidity with the edge-detection of similarity. There are some additional rigidity elements that need to be ironed out but it's showing some promise.
How to solve the problem of AQUAdrupleCLIPLoader node error when running COMFYUI workflow? The error message is as follows:
got prompt
Failed to validate prompt for output 65:
* EncoderLoader 56:
- Value not in list: padding: 'True' not in ['max_length', 'longest', 'do_not_pad']
Output will be ignored
Failed to validate prompt for output 66:
Output will be ignored
Loading HiDream CLIP CLIPtype.HIDREAM 4, most likely: model_options={}
Detected T5-XXL model.
Detected T5-XXL model without final projection layer.
!!! Exception during processing !!! hidream_clip() got an unexpected keyword argument 'distilled_t5'
Traceback (most recent call last):
File "D:\ComfyUI\ComfyUI\execution.py", line 427, in execute
output_data, output_ui, has_subgraph, has_pending_tasks = await get_output_data(prompt_id, unique_id, obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\execution.py", line 270, in get_output_data
return_values = await asyncmap_node_over_list(prompt_id, unique_id, obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\custom_nodes\ComfyUI-Lora-Manager\py\metadata_collector\metadata_hook.py", line 172, in async_map_node_over_list_with_metadata
results = await original_map_node_over_list(prompt_id, unique_id, obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\execution.py", line 244, in asyncmap_node_over_list
await process_inputs(input_dict, i)
File "D:\ComfyUI\ComfyUI\execution.py", line 232, in process_inputs
result = f(**inputs)
^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\custom_nodes\comfy-clip-shunts\node\clip_nodes.py", line 158, in load_clip_internal
clip = load_clip(ckpt_paths=[clip_path1, clip_path2, clip_path3, clip_path4], embedding_directory=folder_paths.get_folder_paths("embeddings"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\custom_nodes\comfy-clip-shunts\abs_sd\CLIP.py", line 265, in load_clip
return load_text_encoder_state_dicts(clip_data, embedding_directory=embedding_directory, clip_type=clip_type, model_options=model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI\ComfyUI\custom_nodes\comfy-clip-shunts\abs_sd\CLIP.py", line 522, in load_text_encoder_state_dicts
clip_target.clip = hidream.hidream_clip(**t5xxl_detect(clip_data), **llama_detect(clip_data))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: hidream_clip() got an unexpected keyword argument 'distilled_t5'
Hidream miiiiiiight be broken. I'd need to check. The clip sampler is currently only compliant with SDXL as is, so you would need to run that against the sampler either way. If the shunts are giving you problems that's another story entirely - it's possible that it's broken.
Hey there. I was wondering if you knew if t5 unchained could be used on bigasp2.5 to improve generations, or is it incompatible?
Lyra will be handling that soon enough. Give me a couple weeks to work out all the logistics, but Lyra has big plans.
@AbstractPhila Sweet. 2.5 is great except for the obnoxious blurring or pixelation present on certain concepts. Any ideas on negatives or ways to bypass that issue?
@regularcheckin Lyra will solve that directly soon enough. If it helps, flow-matching models are all v-pred, so you can make some shenanigans happen if you're careful.
@AbstractPhila Having seen what the publicly released 2.5 is already capable of, I'm very excited for even more shenanigans. It's hard to get a wow, but when it produces, does it ever...
@regularcheckin Lyra is basically the entire shunt system I built in a single AI. She's conceptually powerful enough to house everything, I just need to train the variants.
@AbstractPhila I'm super excited for anything you release.
llama has abliterated versions too
meta-llama-3.1-8b-instruct-abliterated.Q4_K_M.gguf
I don't trust quantized versions of models; especially when the systems are so rigidly dedicated to the rounding effectiveness for theta accuracy.
@AbstractPhila I care about none of this, only making the women wear less clothes.