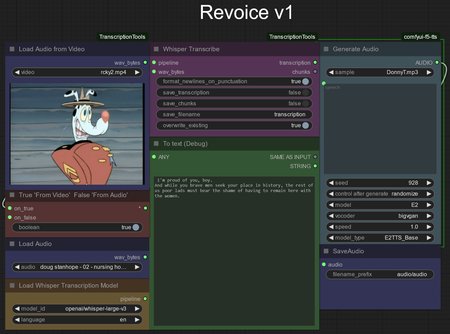
This is a joining of 2 ideas, the nodes for ComfyUI Transcription Tools and Comfy UI F5 TTS - Text To speech.
Load a video or audio file, set the switch 'True' for Vid input, 'False' for Audio input and run, the video or audio file is transcribed and then converted into whatever voice you choose. Rocky533 deserves the lions share of credit for his simple but excellent text to speech kit.
For voices I recommend editing roughly a 40 second sample file with some changes in inflection in the speech, combine with an empty .txt file with the same name and add to your ComfyUI\input folder. It can do a passable job with as little as 7s.
Disconnecting the STRING output from the corner of the text box in the Generate Audio node will turn this into a transcriber and a text 2 audio set-up letting you edit as you like.
To use BigVGAN, you have to add a little dot to make it work with ComfyUI. In the file
custom_nodes/ComfyUI-F5-TTS/F5-TTS/src/third_party/BigVGAN/bigvgan.py
Add a little dot on the line at the top that says.from utils import init_weights, get_padding
so it's becomes. from .utils import init_weights, get_padding
Description
Create a conversation between 2 speakers name files like so:
voice.DonnyT.mp3*
voice.DonnyT.txt
voice.DonnyT.Tay.mp3
voice.DonnyT.Tay.txt
voice.DonnyT.DonnyT.mp3 (copy of first file)
voice.DonnyT.DonnyT.txt (copy of second file)
One speaker is the 'main' one and the others are under their naming banner. Add as many voices as you like with the same naming convention.
(* in this example this file would be used in the 'sampler')
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.