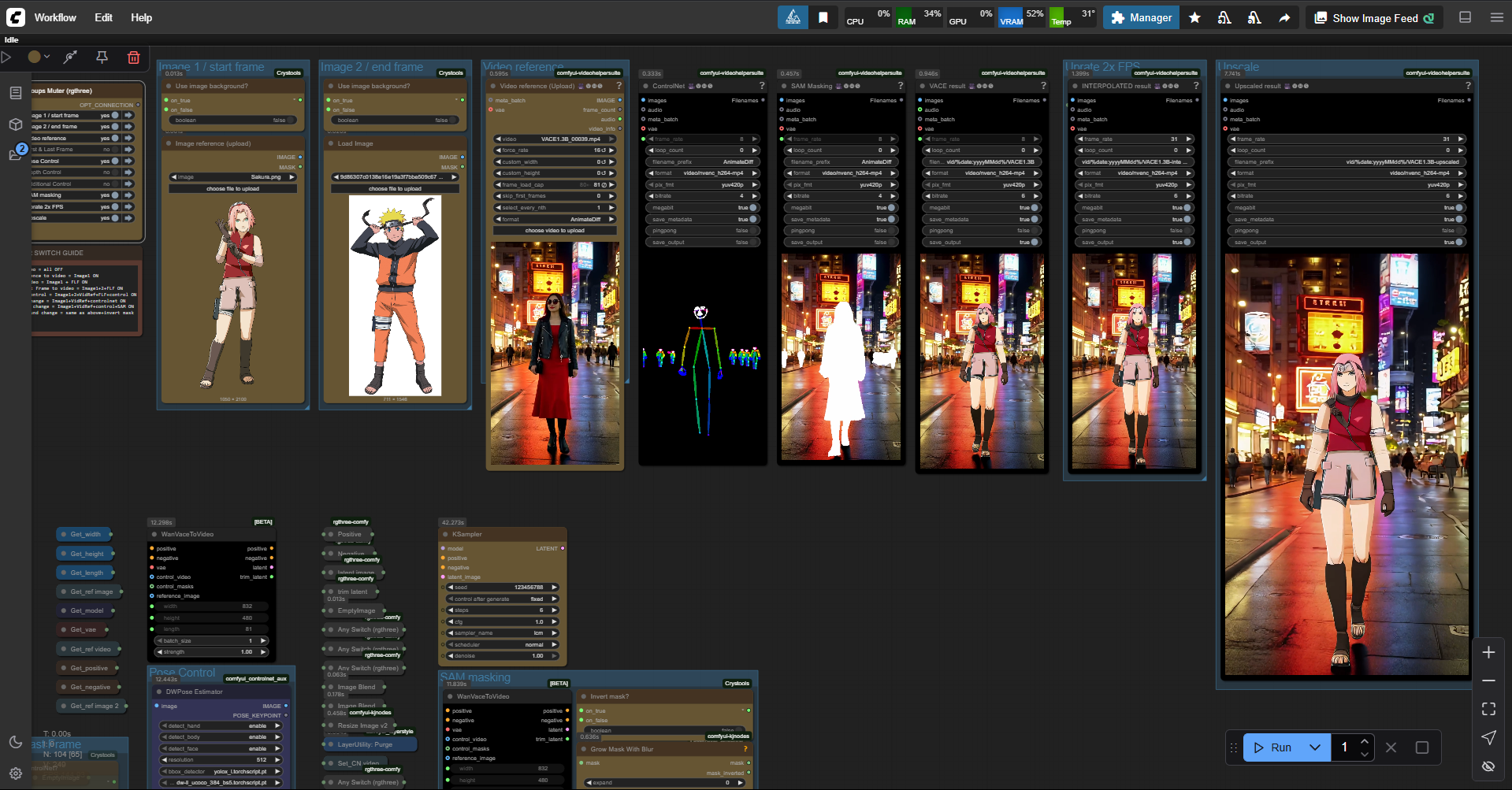
Comfyui workflow for text to video, image to video, video to video, video stylize, video character replacement, clothes swapper, long video generation, low VRAM, 6 steps, all in one simple ULTIMATE workflow.
=====================
v2 Coming soon
add prompt progression/scheduler
add xtend existing video
add 2 image reference
=====================
v1.20250724 Ultimate
add xtend long video generator (with controlnet+masking available)
add loopback feature
better upscale and uprte method
higher resolution for the same VRAM
Framepack killer
=====================
READ ME‼️‼️
Adjust only parameters in YELLOW nodes
prompt the GREEN node in detail
read the MUTER SWITCH GUIDE and MODEL GUIDE
check additional switchs/adjustment in YELLOW nodes
leave the BLACK nodes intact
bypass SAGE ATTENTION node if you don't have it installed
====================
MODEL GUIDE
Use VACE model + CauseVid and/or Self-Forcing lora
14B for quality
1.3B for faster inference
Change GGUF Loader node to Load Diffusion Model node for .safetensor files
===========================================================
14B VACE model GGUF + CauseVid lora (6 steps only)
https://huggingface.co/QuantStack/Wan2.1_14B_VACE-GGUF/tree/main
or
14B FusionX VACE GGUF (CauseVid merged)
https://huggingface.co/QuantStack/Wan2.1_T2V_14B_FusionX_VACE-GGUF
===========================================================
1.3B VACE Self-Forcing model used (6 steps only, no CauseVid needed)
https://huggingface.co/lym00/Wan2.1_T2V_1.3B_SelfForcing_VACE/tree/main
*1.3B VACE GGUF fails to give good result
===========================================================
Use https://openmodeldb.info/models/4x-ClearRealityV1 for upscaling
=====================
SWITCH GUIDE
Text to video = all OFF
Image reference to video = Image1 ON
Image to video = Image1 + FLF ON
First & Last Frame to video = Image1+2+FLF ON
FLF video control = Image1+2+VidRef+FLF+control ON
V2V style change = Image1+VidRef+controlnet ON
V2V subject change = Image1+VidRef+control+SAM ON
V2V background change = same as above+invert mask
Switch ON Xtends switches according your needs (monitor progress in the group)
Loopback ON to make looping video
Description
AIO workflow for WAN VACE 1.3B 6 steps
FAQ
Comments (20)
Image1 + Image2 + FLF gives video with white background.
background image1+2 switch to true
Of course :) I was blind ;)
@orzechowy33332648256 post your results here please, thx 👍
Great wf. I still see the lines in the final video when doing pose control. Img to vid. Is that supposed to happen?
May I ask how to modify the parameters? After redrawing, the characters in the outVideo do not look like real people (both the photos and the video are real people), but rather in a 3d or anime style
Try to detail the prompt, photo realistic, etc. But, if you try to paint real people you know, surely you will notice the difference. No matter how advanced the tech will be.
Throws an error in the ui, https://ibb.co/k2FmRCSs, there is a link to the error.
Its a Ksampler error, No module named 'sageattention'.
I am using Comfyui_windows_portable version.
You can bypass that sage-attention node, it used only to reduce the generation time to about 60%-70%. Example: you can bypass it and get the result in let's say 300 secs, if you install sage, it will be around 210 secs.
18 days ago... and i got 'nodes are not found or have been removed from comfy registry message'. I am starting to believe CivitAi does not have working workflows.
Which nodes position you are missing? Mine are still working just fine.
kukalikuk I assume its working for you because you have those nodes already downloaded but if you use the manager to get them it says:
Failed to find the following ComfyRegistry list. The cache may be outdated, or the nodes may have been removed from ComfyRegistry.
ComfyUI_LayerStyle_Advance
ComfyUI_LayerStyle_Advance
masquerade-nodes-comfyui
gguf
derfuu_comfyui_moddednodes
At least those are the ones I'm missing
Dantor check and repair the channel nodes manager for your comfyui, i got those nodes from the manager. Gguf is one of the most used nodes and I'm sure that I got it from the manager also. In my case, no manual git clone method for the nodes you mentioned.
Working, but flf2v is making a video with the last frame different from the one I set.
Much different or less? Or no last frame at all? I'll update with more improvement in the next version, i hope to finish it in the weekend.
hellow i got this error "AIO_Preprocessor.execute() missing 1 required positional argument: 'image'"
AIO preprocessor is additional control if im not mistaken. Did you turn on the additional control switch? what control did you choose? try turn it off.
Don't bother fixing it, i'll post the new updated workflow with better usage.
when turned off it works