
FP8 Version
Source: https://huggingface.co/Comfy-Org/flux1-kontext-dev_ComfyUI
Workflow: https://comfyanonymous.github.io/ComfyUI_examples/flux/flux_kontext_example.png
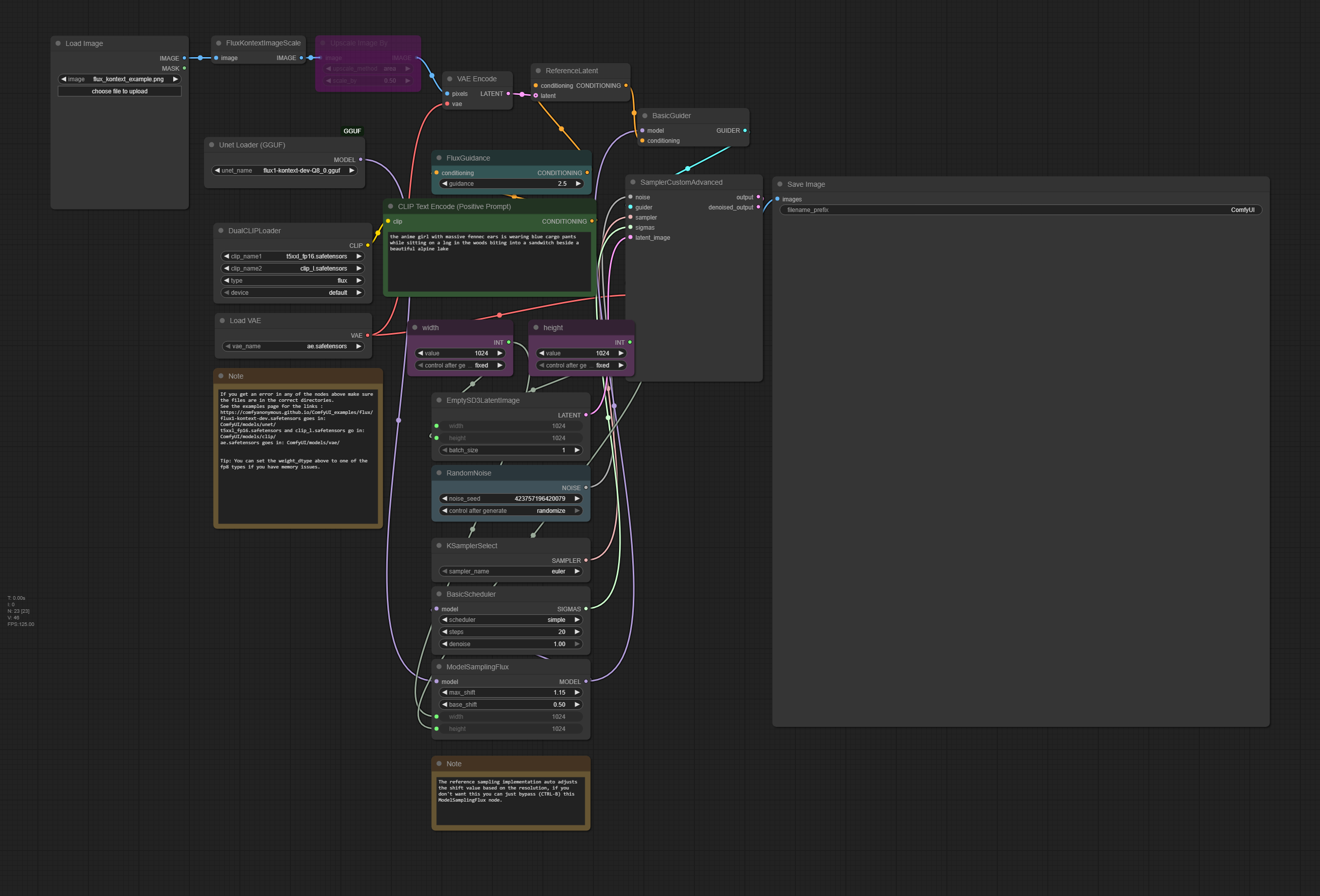
GGUF Version
Source: https://huggingface.co/bullerwins/FLUX.1-Kontext-dev-GGUF/tree/main
Workflow:
https://huggingface.co/bullerwins/FLUX.1-Kontext-dev-GGUF/blob/main/Kontext_example_gguf.png
Prompting Guide
https://docs.bfl.ai/guides/prompting_guide_kontext_i2i
Overview of Flux Kontext (Flux Context)
Family of AI Models: Flux Kontext is a new family of AI models available in three versions: [Dev], [Pro], and [Max].
Revolutionary Image Editing: This model revolutionizes the image editing process.
Simplified Instructions: Instead of describing what you want to create, you simply tell it what you want to change.
Natural Language Understanding: It understands natural language instructions and makes precise edits while keeping everything else exactly the sam
FAQ
Comments (30)
Amazing! And quite simple!
I find it hard to understand. You give the link to the GGUF quantified models, with the basic workflow which is not compatible with them.
{kind=link}
@Hikarias any way to run it 4x faster ? I m on mac and it takes 2 minutes per iteration even on q2?
update comfy.
Very versatile and useful model! Only tragic downside is its heavy censorship and bias.
Let's see how long it will take the community to rid the patronizing "integrity checker" a.k.a. thought police.
This is the thought police! You're under arrest for advertising freedom of thought on the modern internet. You're coming with me, criminal scum...
Check the highest rated entry for Kontext on civitai ;)
@adadsqe No surprises there 😄
But I wonder why the LoRA was banned while the random dude that merged it into his checkpoint is allowed to benefit off of it. Seems pretty unfair to the original creator.
adadsqe how do I see highest rated entry?
@Kir_A its gone :,(
Is anyone having success with maintaining the look of two reference images and merging them? Like "have this man standing in the kitchen". Its like either the man stays the same or the kitchen stays the same but not both.
I made a workflow where I purposely blend them in an image THEN put that in kontext.
Like every workflow I seem to download here, I get missing nodes and Manager shows nothing to fill the gaps. What you've done looks great but guess I can't use it :(
That's because you need to update ComfyUI to the latest version, That's all.
Thank you very much for the prompt response. I haven't updated in about 3 weeks. I'll give that a try!
Sadly thats a comfy issue. It's absolute garbage but so many people have taken up the garbage it's now become the norm
I'm seeing a lot of big heads on stubby bodies.
So far, Kontext has been okay for background, outfit changes, style changes, etc. it works better then any model locally i seen so far. but i can't for the life of me figure out using the default combine workflow in comfyui how to combine multiple images, out-put is always the same as the stiched image even when using format example on official site, or in rare cases it will modify left or right image only and not do anything i asked. I am finding it's ability to understand text input very unforgiving and difficult to use for a flux model, I think it has a lot of filters built in that block a lot of text and may be part of the problem. or it only recognizes a limited vocabulary. but for things it does understand, it does well, so huge potential. Hopefully someone will put out a prompt guide with better example prompts for Kontex if i am missing something.
EDIT: I did review link to prompt guide. for basic single image editing in guide it works great. i am just struggling to understand how to prompt multiple input images
Here's an example prompt for character generation: "Recreate the second image with the first image character in the 3 positions, front, side and back. Full body shots with gray background. Photorealistic style." This works flawlessly for me. Here's the workflow: https://civitai.com/models/1722303/kontext-character-creator?modelVersionId=1949065
@shibadigital I do not think that is what they want. I think they want a person in a background and you supply the two images. like a combine.
@zGenMedia That basic workflow does work to do an image merge/combine. Example: "Replace the background of the first image with the second image." What I've found is that some images work better as do other seeds. This really isn't any different than other models - especially the seed part. The reality is that we're very early in the learning phase with Kontext, so the knowledge base is limited. Part of jumping onto the bleeding edge.
Now if we could somehow stop EVERY SINGLE DAMN female produced by these models looking like Ana De Armas, then we might have some progress LOL.
well you haven't checked this one : instagram @That_stand_user idk how they are doing that but it really looks photorealistic. if anybody knows please share it with the community
Well I would say its the intended result and how life should be to make this world a utopia.
After generation, the image is just a black background. Malevich's Black Square. What am I doing wrong? Help!
Kontext, not just this model, is amazing when it works correctly, but after using a different workflow, it becomes just a regular generator.
Details
Files
flux1KontextFp8And_q80.gguf
Mirrors
flux1KontextFp8And_q80.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1KontextFp8And_q80.gguf
Flux1-Kontext-Dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
flux1-kontext-dev-Q8_0.gguf
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.