Go here for Wan2.2 WF ≈➤🍥 Wan 2.2 (GGUF) [i2v / FFLF] + [t2v] Workflow
Thanks to @definitelynotadog for Dual KSampler Worflow.
Thanks to @Ada321 for uploading Self-Forcing(Lightx2v) Lora here on CivitAI.
*25/7 Updated 🟨 Dual Sampler Workflow to V3 (Updated this in case anyone wants to try, its slower and slightly more complex - nothing change for the base structure)
*24/7 Added 🟩 Single Sampler Workflow V3
Added Video Preview for all WF
Added Post Processing Section for Expanded & Compacted WF
Shifted some inputs to Post Processing Section for Expanded & Compacted WF
Seed node in Expanded & Compacted WF is set to "New Fixed Random" by default.
Swap VRAM-Clean Up to Easy-Use Custom Node Clean VRAM
Added Icons, adjusted some Visuals and edited+added some Notes
Minor visual adjustment in Interpolation+Upscaler WF
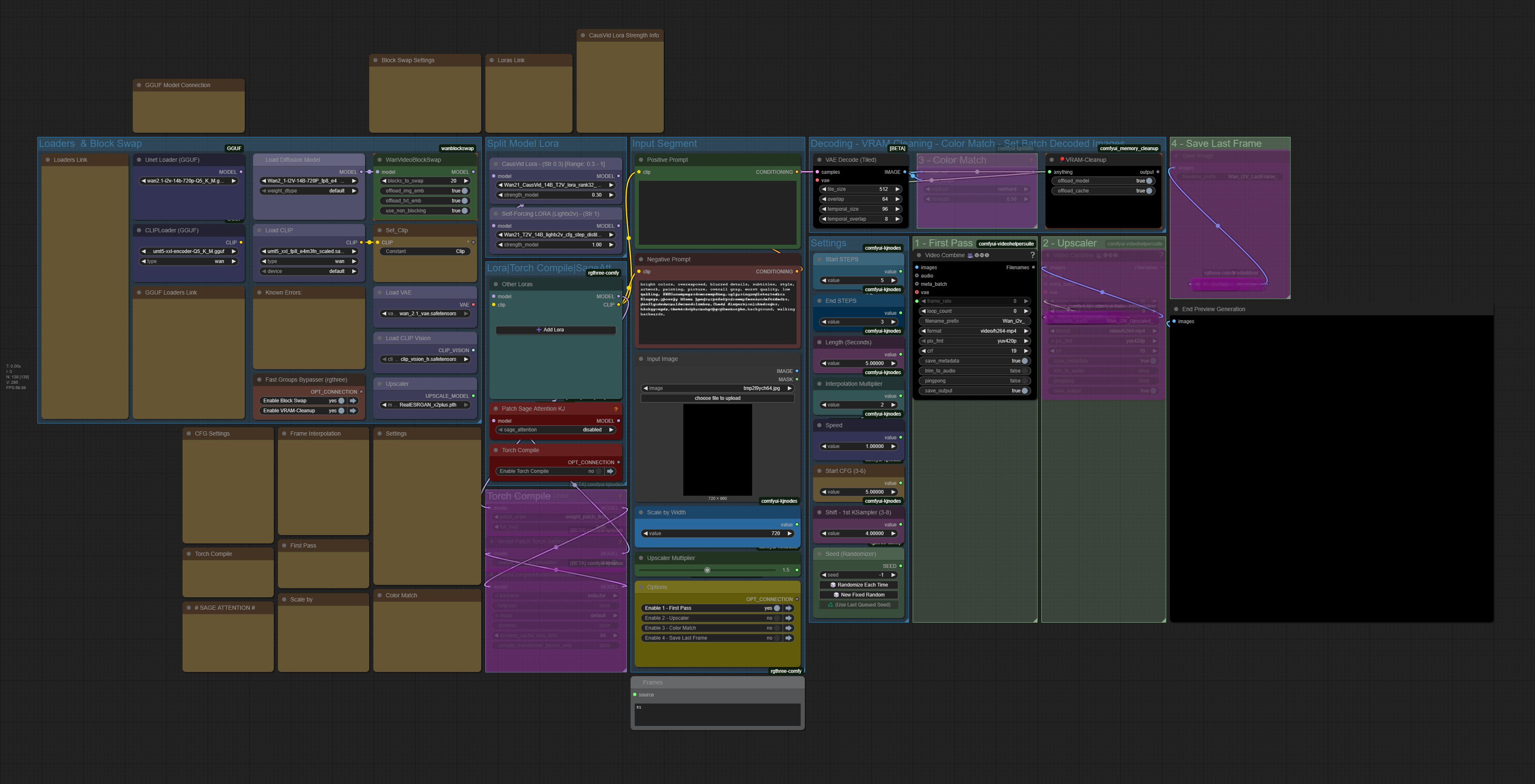
Post Processing Section (Expanded & Compacted):
When using "New Fixed Random" in the seed node, after a video is generated, we can change/edit inputs or choose another selections of option and generate again while skipping Sampling process/steps.
Example: Let's say you generated a video by clicking on the ComfyUI RUN button and you forgot to set the Interpolation Multiplier or choose Interpolate + Upscale Options. Once the video have finished generating, you can change and set the Interpolation Multiplier and/or select Interpolate + Upscale option and click ComfyUI RUN button again which will skip the Sampling process/steps because you are using the same seed number and Not change any inputs that is not in the Post Processing Section.
To generate a new seeded video, click on "New Fixed Random" in the seed node and click on the ComfyUI RUN button.
This method also speed up drafting for videos, so you don't waste time interpolating or upscale the video you might not want.
Small written guide in WF.
17/7 - Added 🟩 Single Sampler Workflows V2.1 to use with the new Self-Forcing(Lightx2v) Lora.
Single Sampler Downloads Contains the following WF:
Expanded (Shows all connections - mainly for learning + exploration)
Compacted (Only show essentials and hides everything else)
Simplified ("Standardized" WF for those who prefer to have more control over inputs)
Interpolation + 2x Upscaler (Useful when you want to generate a lot of videos until you get the desire one and interpolate+upscale later. )
Joiner/Merger (Joins 2 videos together)
This Single Sampler workflow includes:
GGUF Loaders for Diffuser Model + Clip (Best to use GGUF Model + Clip together)
Block Swap for memory management
Sage Attention (Speed up Generation Time) - I forgot how I managed to install this.
Torch Compile (Speed up Generation Time) - Enable only when your system support it.
NAG (Normalised Attention Guidance) - Adjusts negative prompt influence intelligently when using CFG 1.
Stack Lora Loader
Scale by Width for Image Dimension Adjustment
Video Speed Control
Frame Interpolation for Smoothing
Auto Calculation for Numbers of Frames and Frame Rates in accordance to the inputs of video length, speed and interpolation multiplier
Save Last Frame (For sequencing video)
Color Match (Useful for sequencing video or uniform color through out video)
VRAM - Clean-up
Upscaler (up to 2x)
5min 30sec generation time on my 3090 Ti 24 GB:
720x960 Image - 4 steps - 81 frames (5secs) - 4x Interpolation - Upscaler - GGUF - Torch Compile - Sage Attention
Videos posted above are without speed adjustment.
Includes Embedded Workflow. (Download the vid, drag into ComyfUI)
Links to models/lora files in workflow.
Always download the files from this page as there might be minor updates.
(use Videos posted for settings examples)
I only tested with a few loras and they seem good. Try to use alternative Loras if those that are not working to your desire, and you can always fall back on Dual Sampler if needed. (They are still functional but takes longer time than single). Can also try to lower Self-Forcing(lightx2v) strength.
🟨 Dual Samplers Section:
*V2.1 Minor Update.
Switch VAE Decode (Tiled) to the normal VAE Decode, which is causing "sudden flashing" when video are more than 5 seconds or 81 frames.
Updated CausVid v2 link in all WF or get it Here. (thx @01hessiangranola851)
*If you already using the WF:
experience flashing/sudden brightness when generating more than 5 sec vid. Try setting the temporal_size to 64 in the VAE Decode (tiled) or switch to the normal "untiled" VAE decode.
experiencing grey out first few frames, reduce the CausVid Strength or just set it to 0.3.
*V2 Update
GGUF Loaders for GGUF Diffusal Model & Clip with download links. (Choose either Native or GGUF. Disable/delete the ones not using.)
"Fixed" Torch Compile and add fp16 accumulation options.
Color Match (Useful for sequencing video or uniform color through out video) .
Template for External Video Merger/Joiner. (in expanded version)
CausVid Strength ( Range: 0.3 - 1 )
Minor visual and notes adjustments.
The i2v workflow is build with the intentions in mind:
Build for the use of Self-Forcing(lightx2v) Lora (but not limited to)
For learning and exploration
Experimental purposes
Modular Sections (add, build upon, swap or extract part of the workflow)
Exploded View - to see all connections (In expanded version)
This Dual Sampler workflow includes:
Block Swap for memory management
Sage Attention (switch on if you have it installed)
Torch Compile
Stack Lora Loader
Scale by Width for Image Dimension Adjustment
Video Speed Control
Frame Interpolation for Smoothing
Auto Calculation for Numbers of Frames and Frame Rates in accordance to the inputs of video length, speed and interpolation multiplier
Save Last Frame
Previews for both First KSampler Latent and End Video Images
Dual Sampling using 2 KSamplers
VRAM - Clean-up
Upscaler (up to 2x)
Template for external Frame Interpolation (in expanded version).
Models to use:
The workflow can use either wan2.1 14B 480p or 720p. (i2v).
720p model and higher resolution images are recommended as it gives better quality. Especially eyes and teeth during motions.
Examples:
5 first steps / 3 last step / 81 frames
 480p model - 480x640 Image
480p model - 480x640 Image
 480p model - 720x960 Image
480p model - 720x960 Image
 720p model - 480x640 Image
720p model - 480x640 Image
 720p model - 720x960 Image
720p model - 720x960 Image
Generation speed with my 3090 TI 24GB with Sage Attention no GGUF - 5 first steps & 3 last steps (total 8 steps) , 81 frames and 4x frame interpolation multiplier:
720 x 960 Image : ~750 secs 12-13 mins est.
480 x 640 Image : ~350 secs 5-6 mins est.
Note:
Some Loras may distort faces or the character. Either reduce the lora strength or use an alternative lora.
Sometimes you may need to generate a few times to have better motion seed. Be patient.
I did not test every loras, so you will need to test and figure it out yourself.
(480p/720p Model, Image Dimension, Lora Strength, Start CFG)
*If you find the other loras you are using with this workflow are too aggressive. (too much motion, color change, sudden exposure), lower down the Start CFG. Alternate between 3 & 5 to see which is better.
Some videos I posted above used lower CFG because the other loras are too aggressive with high CFG level.
Drafting for motion with other Loras:
Use smaller image dimension for faster generation to see if the lora you use have any motion.
Once satisfied with lora and prompt proceed to use desire image dimension.
Other tips:
You can also clean up distortion/blur by using other V2V workflow.
Like this one:
https://civarchive.com/models/1714513/video-upscale-or-enhancer-using-wan-fusionx-ingredients
and/or use face swap to clear face distortions.
🟨Dual KSampler
Recommended Steps:
5 start steps / 3 end steps (I used the most for testing)
4 start steps / 3 end steps
The old T2V Self-Forcing(lightx2v) may sometimes hinder, slow down or produce less motion for some loras.
In order to get more motion for some loras, you need a higher CFG level of more than 1, but when using Self-Forcing(lightx2v), you need to set the CFG to 1.
So this is when Dual KSampler is utilize.
The 1st KSampler uses high CFG level of 3-5 to create better "motion latent" along with Causvid Lora to increase more motion with lesser step generation.
The 2nd KSampler uses low CFG of 1 for finishing the video with 3 steps using Self-Forcing(lightx2v) lora for speed generation. More steps count will make Self-Forcing(lightx2v) lora to influence the video more and cause lesser motion again.
In order to pass "motion latent info" to the 2nd sampler, the 1st step count has to be more than half of the total steps.
Examples:
5 first steps / 3 last steps / 8 total steps
4 first steps / 3 last steps / 7 total steps
When it is configure in this way, you can see the images start to form in the latent preview:
 That is when it can be pass to the 2nd KSampler with "motion latent info" to finish it off without heavily influencing it in low steps.
That is when it can be pass to the 2nd KSampler with "motion latent info" to finish it off without heavily influencing it in low steps.
(If the 1st steps count is half or less than half of the total steps, you will see a very noisy image that does not resemble anything.)
Basically a 7-8 steps generation splits into 2 KSampler.
The 2nd KSampler continue the generation process from where the 1st KSampler left off.
(Using 2 normal samplers will not produce the same results as the 2nd sampler will not know at which step to continue from. It will take the product of the 1st KSampler, ignore what it has produce and start from step 0.)
With the initial KSampler generating at 3-5 CFG, its slower. But the trade off here is to get more motion when using it with other loras. Comparing it to a 20-30 steps with no CausVid or Self-forcing(Lightx2v), it way faster.
Unfortunately, KSampler with Start End Step is only available for Native and not WanWrapper.
Tooooo many GET and SET nodes....
!!! Only available when ComfyUI-Easy-Use custom nodes are installed.
You can utilize the Nodes Map Search (Shift+m) function.
In your Comfyui Interface panel. Usually on the left. Look for an icon with 1 small square on top and 3 small squares below it. It's call Nodes Map.

Let say you see a "Set_FrameNum" node.
And you want to know where the "Get_FrameNum" is.
Enter in the search bar:
Get_FramN....--! Case Sensitive !--
And you will see it filtered.
Double click on that and it will bring you to the node.
Likewise for Get nodes:
Example for "Set_FrameNum"
Search:
Get_FrameNum--! Case Sensitive !--
Filtered.
Double click.
Custom Nodes
ComfyUI-Custom-Scripts
rgthree-comfy
ComfyUI-KJNodes
ComfyUI-Frame-Interpolation
ComfyUI-mxToolkit
ComfyUI-MemoryCleanup
ComfyUI-wanBlockswap
MediaMixer
ComfyUI-Easy-Use (Install manually in your Custom Node Manager)
After notes:
You may build upon, use part of, edit, merge and publish without crediting me.
The reason why I don't use GGUF is because it keeps bricking my ComgfyUI every time I tried installing it.
I do not have more in-depth level of understanding beyond this point.
Description
Compacted
-Hides everything.
FAQ
Comments (11)
I wonder anyone experiencing if generating more than 5 secs in the Length(seconds) section will give slightly wild color boost at last sec, I tried exactly 5 sec is fine, but if change to 6 sec or more, the video will appear vibrant color at last sec which is a flaw for me. I changed color correct, lower shift and CFG just did not help.
same for me, usually after 81 frames. I dont have a solution to this at this moment.
Colormatch node is your friend. Learn it- use it- and never again will you have this problem
@jackietop515100 Try setting the temporal_size to 64 in the VAE Decode (tiled) or switch to the normal untiled vae decode. I going to update all WF soon.
You know, there is a CausVid V2 available that was created specifically to handle some CausVid V1 problems like the initial flash. It's available in the same Kijai repository where you download CausVid V1.
Do you have a version of this but for the T2V model?
no i dont, sorry. you probably could swap out some nodes to make it t2v. but i havent tested it on t2v.
It'd be a bit pointless to use this for T2V. This workflow is to specifically address the issue of Lightx2v causing poor movement when used for I2V by using CausVid (which usually results in lower quality vids on its own) to do the first early steps to establish the early steps and Lightx2v to polish it.
If you're doing t2v, just add Lightx2v as a lora to a standard workflow, set CFG to 1, and steps to 4-8.
Love the layout and descriptions! Very easy to understand workflow.
could anyone please share deepthroat workflow for this? I can't figure out good prompts and settings. I use this LORA https://civitai.com/models/1497390/deepthroat-wan-21-i2v?modelVersionId=1693883
Just save the video posted above, and drag it into the comfyui. The videos are embedded together with the workflow.