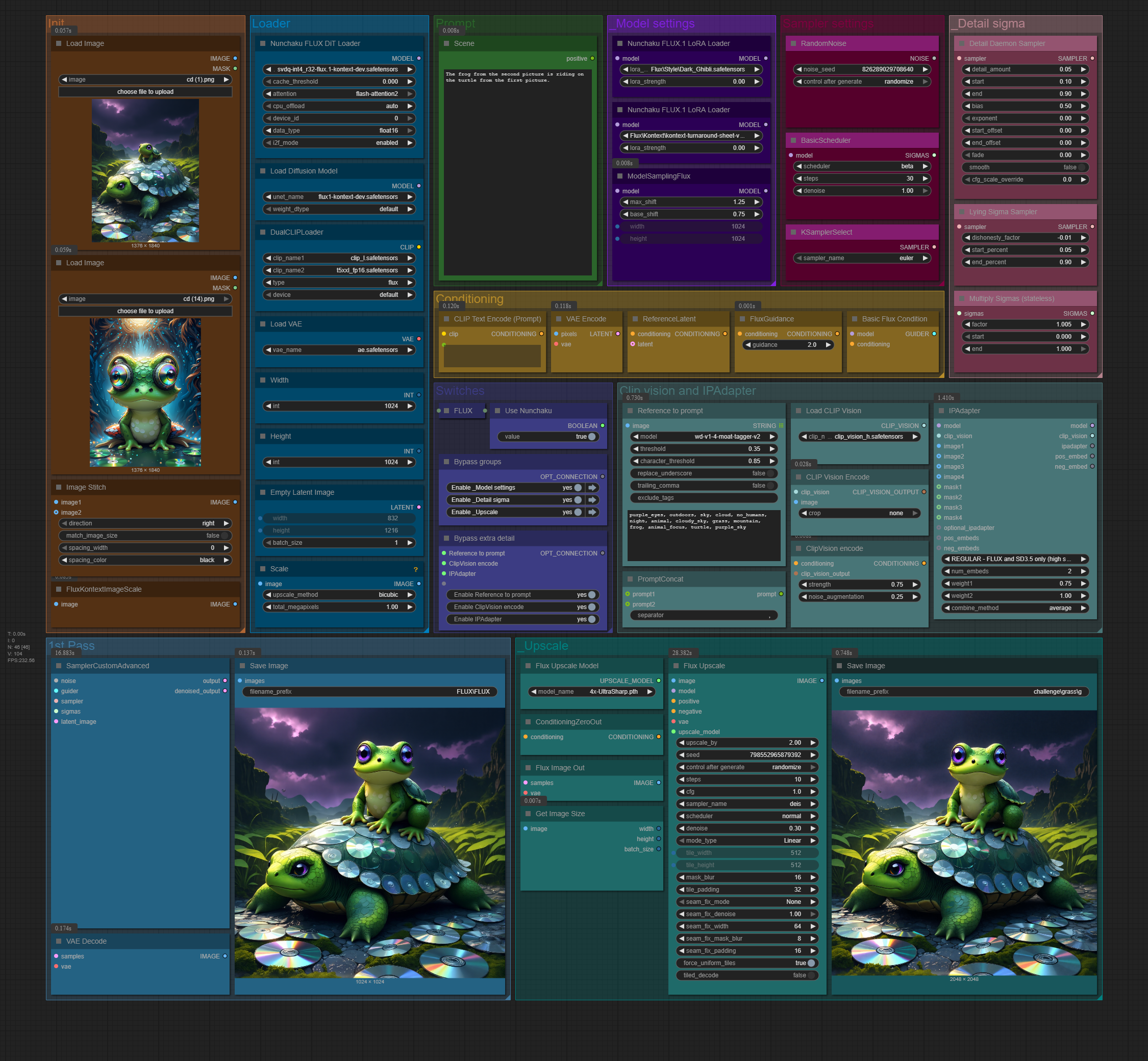
About the workflow:
Nodes you will probably want to adjust and use normally.
Init
Load the pictures to be used with Kontext.
Loader
Select the diffusion model to be used, as well as load CLIP, VAE and select latent size for the generation.
Prompt
Pretty straight forward: your prompt goes here.
Switches
Basically the "configure" group. You can enable / disable model sampling, LoRAs, detailers, upscaling, automatic prompt tagging, clip vision UNClip conditioning and IPAdapter. I'm not sure how well those last two work, but you can play around with them.
Model settings
Model sampling and loading LoRAs.
Sampler settings
Adjust noise seed, sampler, scheduler and steps here.
1st pass
The generation process itself with no upscaling.
Upscale
The upscaled generation. By default it makes a factor of 2 upscale, with 2x2 tiled upscaling.
Mess with these nodes if you like experimenting, testing things.
Conditioning
Worthy to mention that FluxGuidance node is located here.
Detail sigma
Detailer nodes, I can't easily explain what does what, but if you're interested, look the nodes' documentation up. I set them at a value that normally generates the best results for me.
Clip vision and IPAdapter
Worthy to mention that I have yet to test how well ClipVision works and IPAdapter's strength when it comes to Flux Kontext.
Description
FAQ
Comments (12)
Looks epic! Teacache is the one thing that just got officially supported for Kontext that I'll likely add - but looks gorgeous. (found it via Comet who found it via a request to search reddit for any cool new kontext WFs - great timing!)
Thanks!
I'll also look into Teacache on Kontext soon, too.
The NunchakuFluxDiTLoader will not work. Even when installed it errors out.
I got ComfyUI node manager to install it for me, so can't really troubleshoot on that one.
You can still turn off "Use nunchaku" and use the default Kontext diffusion models.
Go to the ComfyUI nunchaku github page and try following the install instructions there. Just installing the package in ComfyUI didn't work for me.
Yeah I solved this issue by manually installing this nunchaku from its github page:
Go to the releases page right there, Select a stable final version (I didn't select a pre-release until now) for example if you have Pytorch (Torch 2.7) which is default for ComfyUi 0.3.43 or 0.3.44 with its own embedded Python 3.12 , then, download the nunchaku package called ( nunchaku-0.3.1+torch2.7-cp312-cp312-win_amd64.whl ).
Copy that file to the python embedded path inside yout ComfyUi assuming you have ComfyUi portable ,
..\ComfyUI_windows_portable\python_embeded\
then Open a command prompt from that folder using any method you like ( the default way is press & keep pressing (Shift) + R-Click & Select Open Command Prompt Here ).
then, Use the following command to install it :
python.exe -s -m pip install "nunchaku-0.3.1+torch2.7-cp312-cp312-win_amd64.whl"
Close Comfy & its Server (its own command prompt window) if it is already opened, Launch it again, this time it should work.
yorgash looks need to install the wheel for this t work.
https://github.com/nunchaku-tech/ComfyUI-nunchaku/blob/main/example_workflows/install_wheel.json
trashkollector175 this make it works like a charm, I struggle alot to get it work and this simple trick resolved everything
Very clean workflow. I'm curious, do you know what controls the final image sometimes just being one of the original images or being a stitched image?
I have been trying to find out, but it seems to be internal to Kontext I think?
Still thankfully manage to get just the right amount of okay results I need :)
KayTool has removed their nodes from their releases (so it can't be downloaded via the manager), but still manually downloadable from git.
The only missing node is Preview_Mask.
Why UltraSharp when UltraSharpV2 is out