
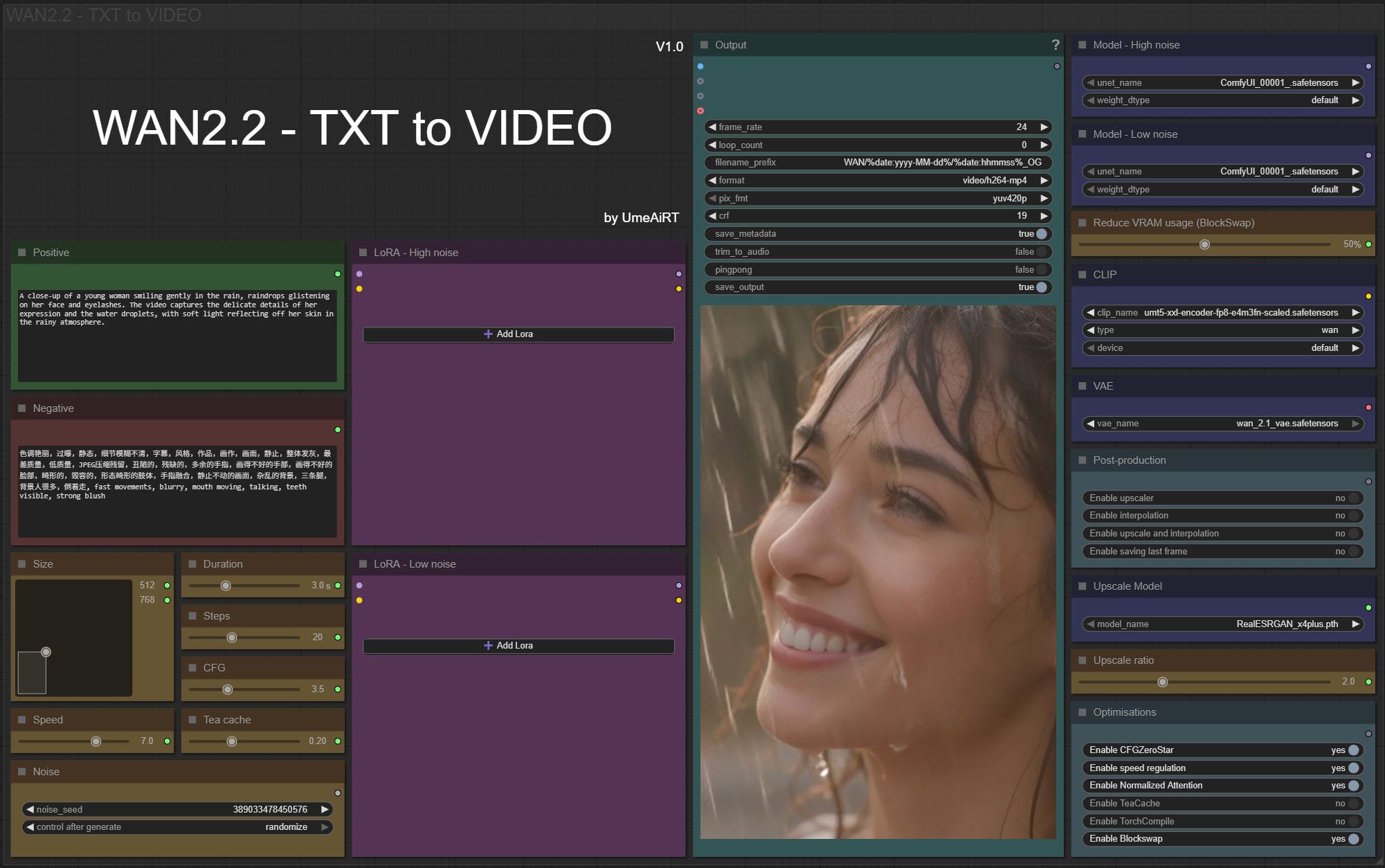
✨ WAN2.2 — Text to video — Simple Workflow
A clean, all-in-one WAN text-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors and wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
In models/diffusion_models
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
For GGUF version
I2V Quant Model : wan2.2_i2v_high_noise_14B_QX.gguf and wan2.2_i2v_low_noise_14B_QX.gguf
In models/unet
Quant CLIP: umt5-xxl-encoder-QX.gguf
in models/clip
For lightx2V version
lightx2V LoRA : Wan2.2-Lightning_T2V-A14B-4steps-lora_HIGH_fp16.safetensors and Wan2.2-Lightning_T2V-A14B-4steps-lora_LOW_fp16.safetensors
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
fixed wrong workflow upload (sorry i dont know how it happened)
FAQ
Comments (20)
Workflow is nice and simple as always, but I'm having issues with the LightX GGUF one.
Firstly MagCache throws an error if enabled. "NoneType" attribute "to" apparently. But whatever, disabling that and enabling TeaCache allowed a nice generation, pretty fast too, faster than my 2.1 WF.
However subsequent generations with different prompts and seeds threw up the same video as the first (woman holding an umbrella in the rain) but grainy/blotchy. Seems like TeaCache isn't properly clearing itself. I've updated all nodes to no avail. Disabling TeaCache lets it do another generation no issues. I might just leave it off for now, 190 seconds for a video is still an improvement over 2.1 for me.
Thanks!
Exact same issue here
Awesome workflow! Thanks! The only thing I personally felt was missing is the option to manually choose the sampler and maybe a live preview, so it’s easier to get a sense of what to expect during generation.
do you know why the videos are always washed out? the video is not sharp and the colors seem faded. maybe its just a setting somewhere...
maybe resolution size, anything below 720p will be bad quality, processing the video through an upscaler may also disturb the video quality. For example, if you have a decent video of a person and throw it through a bad or incompatible upscaler your original video could come out with the persons face blurry and with artifacts due to oversharpening.
Make sure you actually load the light loras, it can seem like it's loaded since it shows the name, but you have to select it in the list to make sure it loads your one.
Hi! Problem!!
WanVideoNAG
mat1 and mat2 shapes cannot be multiplied (385x768 and 4096x5120)
This error seems to be complaining about the encoder. Download and install this one https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
Using GGUF+lightx2v json: Sampler High gives error "'NoneType' object has no attribute 'to'". 15th Aug. 2025.
I fixed this by turning off Mag Cache in the options. Unfortunately Tea Cache is broken too, it will work for one generation then it won't clear. Works quite well with neither cache, but still waiting for a fix as TeaCache really speeds up the generations.
Wildcard integration would be awesome here
I install comfyui-dynamicprompts then add the node and connect it to normal prompt node, works fine :)
SysDeep Thank you, workflow wizard!
This workflow crashes my Comfyui every time.
No error in the logs.
RTX3090, 64GB ram.
Can you tell me how to reduce the speed of the video? I can't figure out where to change the settings so that the video becomes slower.
Does making the video longer use more VRAM with a 5080 I can get 4 seconds but 6 crashes. Anyway to make a longer video with the same VRAM?
You can use blockswap to tranfer some to RAM or use gguf models
Is for wan2.1 in description ?
For lightx2V version
lightx2V LoRA : Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank64.safetensors
I'm getting this error when I run this workflow, any recommendations please.
"RuntimeError: Expected all tensors to be on the same device, but got weight is on cpu, different from other tensors on cuda:0 (when checking argument in method wrapper_CUDA__native_layer_norm)"
In v.0.3.76+v1.2,
gguf works fine.
gguf+lightx2v seems to have some issues. I'm investigating the cause.
Thank you.