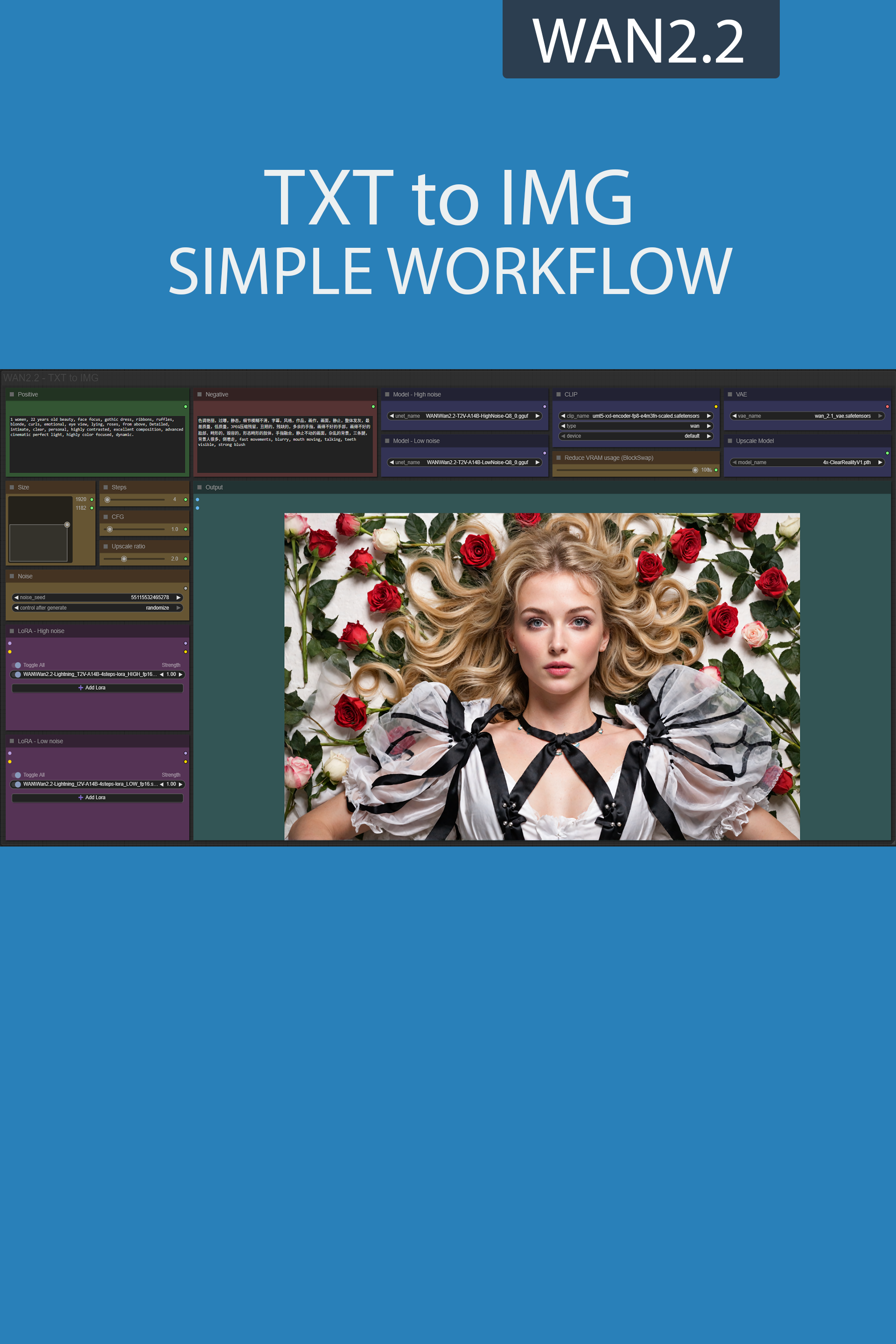
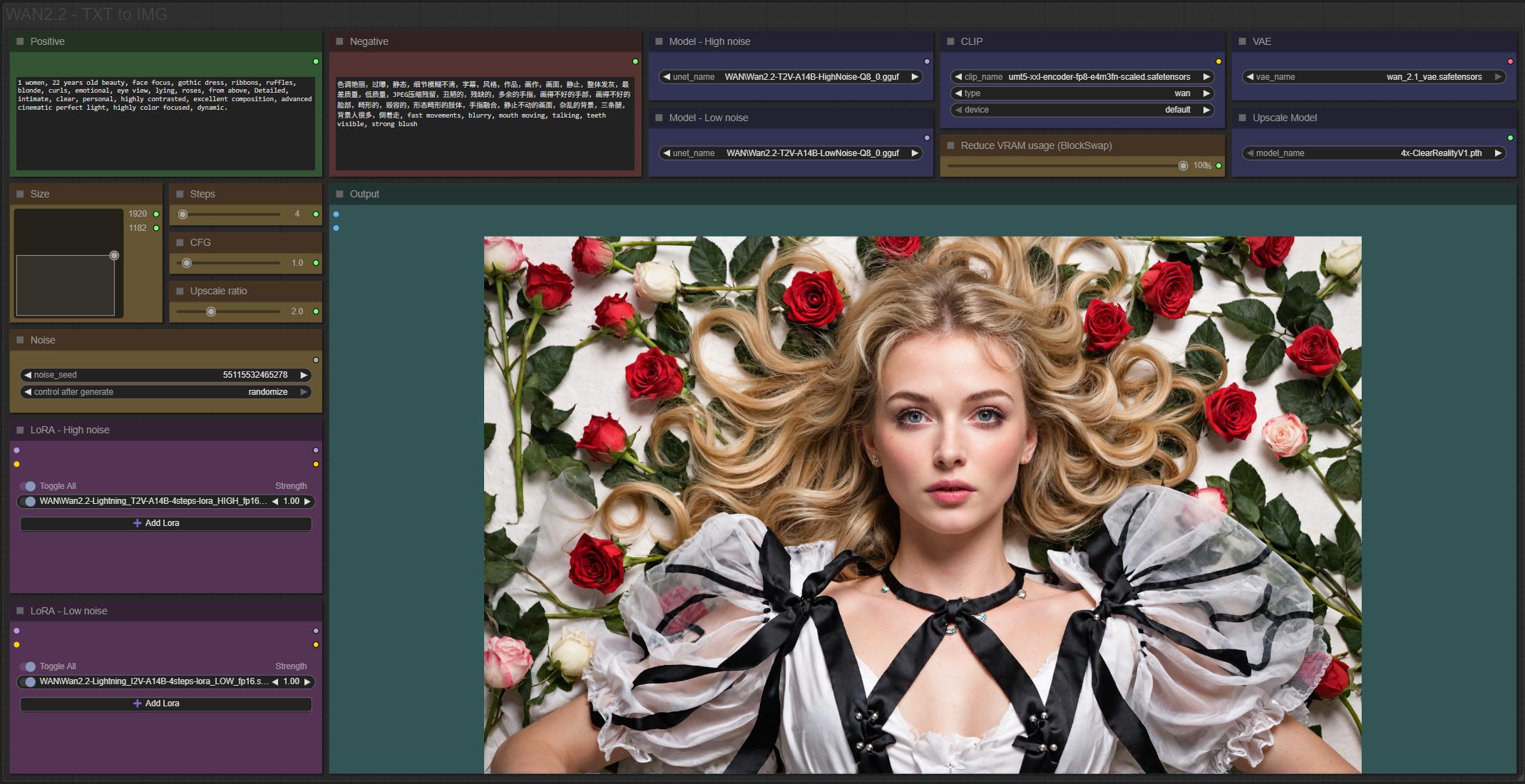
✨ WAN2.1 — Text to image — Simple Workflow
A clean, all-in-one WAN text-to-image workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 10 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
T2V Model: fp16, fp8
In models/diffusion_models
For GGUF version
T2V Quant Model: Q8, Q5, Q3
In models/diffusion_models
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
base version
FAQ
Comments (10)
Thank you! Very good workflow. I couldn't find your stock samplers, I used the pho flux that I liked, it handles the details very well.
Failed to validate prompt for output 515:
* KSamplerAdvanced 466:
- Value not in list: scheduler: 'bong_tangent' not in ['simple', 'sgm_uniform', 'karras', 'exponential', 'ddim_uniform', 'beta', 'normal', 'linear_quadratic', 'kl_optimal']
- Value not in list: sampler_name: 'res_2s' not in (list of length 40)
* KSamplerAdvanced 465:
- Value not in list: scheduler: 'bong_tangent' not in ['simple', 'sgm_uniform', 'karras', 'exponential', 'ddim_uniform', 'beta', 'normal', 'linear_quadratic', 'kl_optimal']
- Value not in list: sampler_name: 'res_2s' not in (list of length 40)
Output will be ignored
Failed to validate prompt for output 526:
Output will be ignored
Install the RES4LYF custom node package in ComfyUI
@wjzy123 Hey, this comment is already a month old. Do you think I haven't found a solution yet? Or that I've given up on it? Of course, I installed everything I needed a long time ago.
@redsnail what a salty azz u are. he tried to help, a month later or not. i hope your GPU goes up in smoke you salty prick
@wjzy123 Thank you buddy, i will try this. Guess redsnail nailed his snail to red, so he wont share his solution.
Is it possible to add wildcards into the workflow somehow?
Just link the Wildcard node (dynamic Prompt) to Positive Prompt
Why would you use a tool for video generation to make txt2img? There are models for that. WAN focus is totally different. Okay...
The zip file contains two files: WAN2.2 - TXT to IMG (base) and WAN2.2 - TXT to IMG (gguf)
When I open them they both contain Wan 2.2 high and low noise loaders! This is a Wan video workflow that has nothing to do with 'text to image'!
Perhaps the wrong file was uploaded? (Will now try to look for an older version)