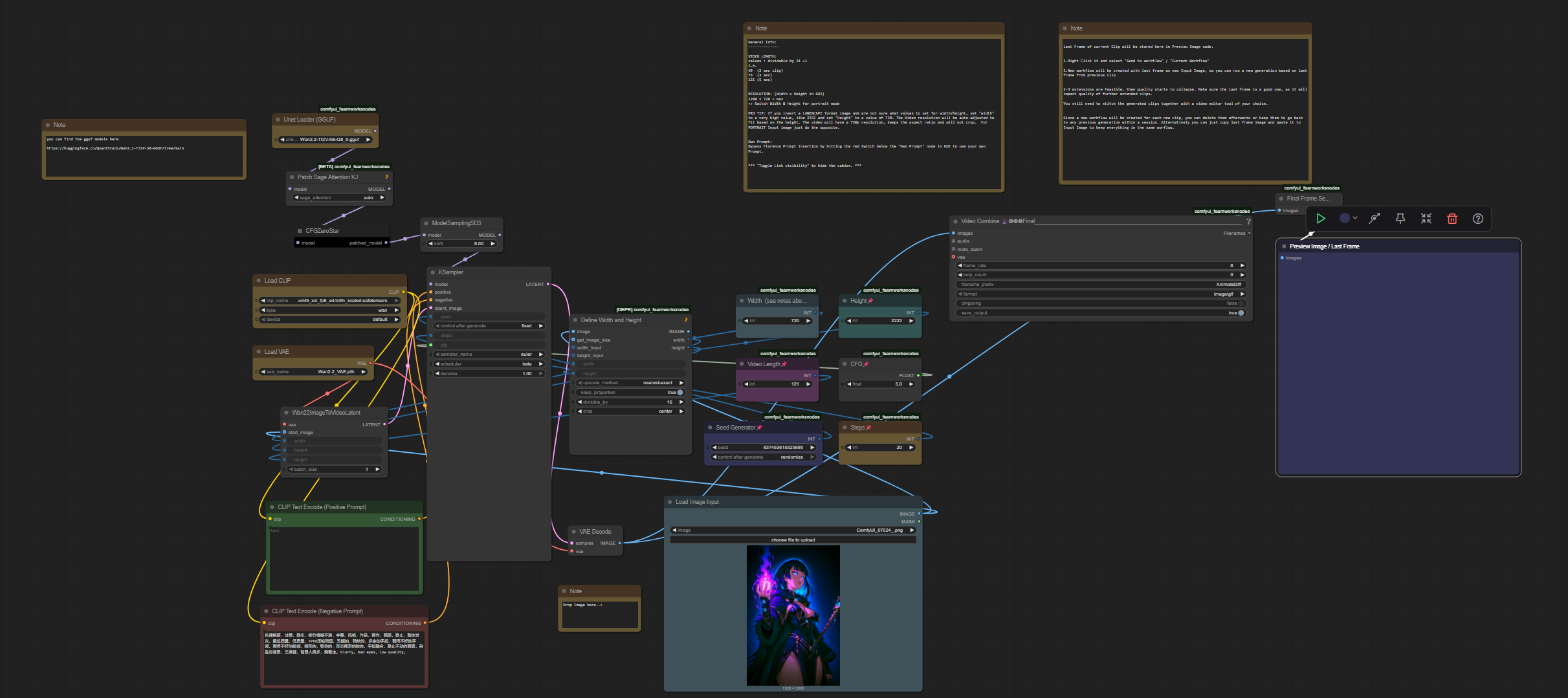
Low vram gguf workflow
Description
FAQ
Comments (8)
There's a major post on Reddit across a ton of different hardware PROVING that your video model should live in RAM, not VRAM, and this has no impact on iteration speed. This false information suggesting you need small models to make low VRAM work should end.
What matters is protecting VRAM for the latent frame information, and keeping model data out of VRAM. This can be achieved by launching Comfy with the right arguments. The one potential downside is clip (LLM) being processed by the CPU, which will add a constant overhead to render time, but will not impact iteration speed.
Im interested in reading up on that, could you please link to that reddit post ?
could you pls share the link for the reddit post here?
This claim with no link is crazy
is this some kind of snake oil pitch?
for god's sake op, please discuss here
Why would you post this with nothing to back it up?
Works. Could be better with lora etc.