





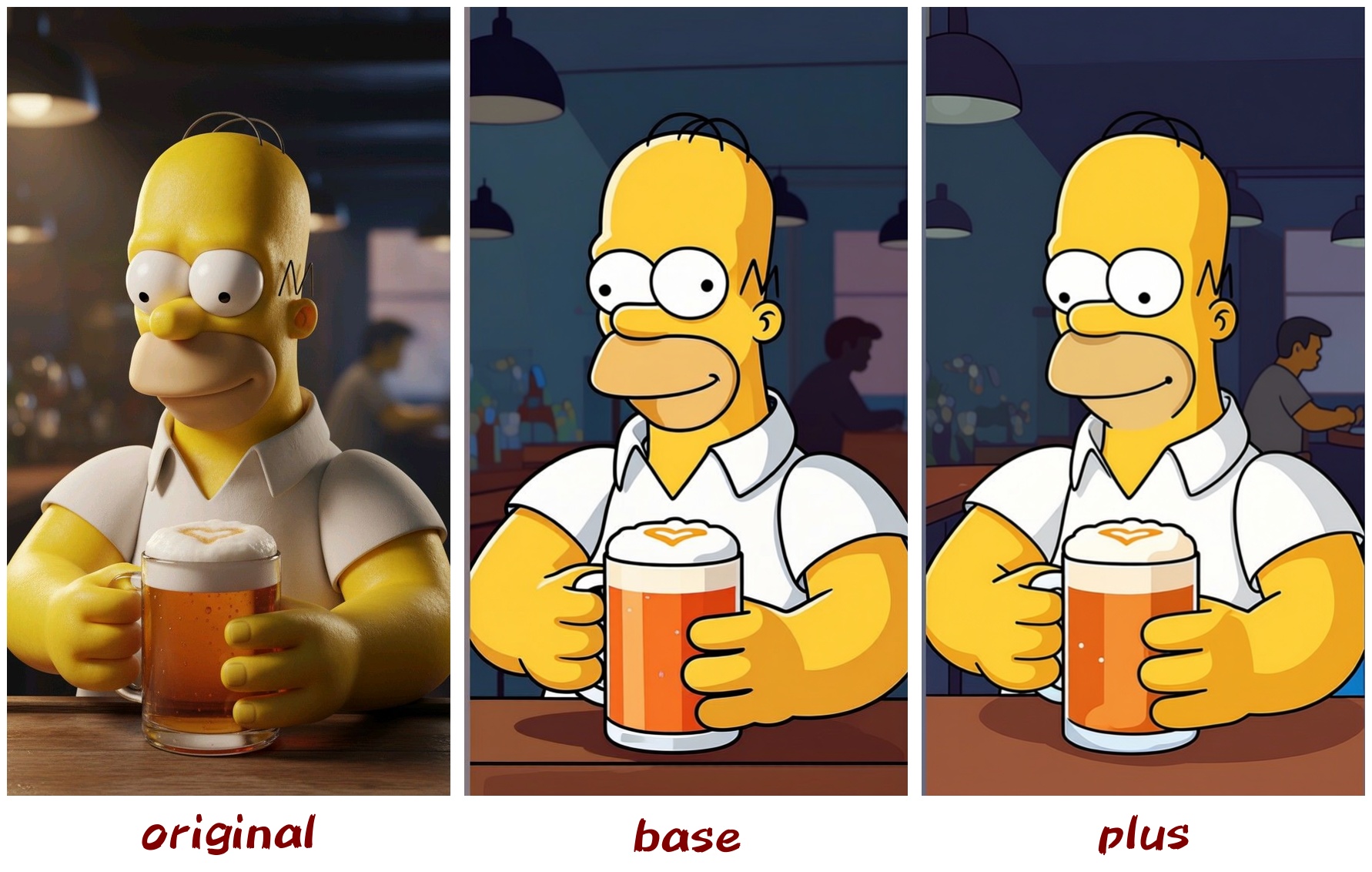




As we all know, the Canny function in ControlNet can accurately extract lines from the original image, but unfortunately, it cannot perform color transfer. This LoRA attempts to change this. It can not only achieve line extraction similar to Canny, but also extract the main colors from the original image and transfer them to the new image, thereby forming a new visual style.
Fields where this LoRA is suitable for application:
The production of memes

Nostalgic comics

Vector style illustrations

Instruction manual illustrations

It is also proficient in drawing complex structures/scenes

Supports input in multiple styles:
Whether it's realistic photos, film and television stills, 3D, 2.5D, 2D illustrations, or even AI-generated images, they can all achieve migration very well.



end - credit scene
If you feel that the output image is too flat, you can use the prompt "rick details" to add more detailed effects.

🙈🙉🙊🐵OK! That's all
If you like my work, please give it a 👍.
Thank you for reading this far.
English is not my native language. The above is translated by AI. If there is anything inappropriate, welcome to correct me. Finally, I hope you have fun!
👉👉👉My CivitAI homepage👈👈👈
Description
FAQ
Comments (28)
Try using the lora with a negative force using a drawing image to see if it converts to reality.
Then why don't you just use my other LoRA?
https://civitai.com/models/1934100
Yes, I know it exists, but in this case you wouldn't need two if this worked.
@NRDX Hahaha, what a clever guy! Hey, guy! That's just a 500M LoRA; there's no need to be so thrifty.
@vjleoliu I know that, it's not about economics, it's about testing and knowing what your own model is capable of doing.
Indeed its a brilliant idea.
An ingenious idea. I'll just sit here and wait for someone to try it.
(actually, I did try it, but I won't share the results to keep things interesting, or at least subscribe to my patreon (blocked in my country, whatever) where I download loras, test them for $1 each try and... and that's all folks).
@forfreelsd368 Hahaha, man, I don't object to people making money using their abilities, but isn't it a bit too much for you to promote your own Patreon in my post where I have a Patreon account?
@vjleoliu you afraid of... emm... completely solid and straight man to man competition?)
Wait, what channel? If I even got one - I'd can't got profit in $ from it. Maybe even got in jail.
@forfreelsd368 Of course, I don't oppose fair competition, but this is not within the scope of what I consider fair competition. I won't do this, and I don't want others to do this to me either.
Can you please try training a lora in qwen 2509 which takes solid colored chracter art something we do in ms paint(using bucket fill) and based on reference image it converts it into art. ❤️❤️❤️
What kind of reference image?
@vjleoliu one image with only solid colors of character,and detailed character image as reference image
@LastDelivery4801226 I understand, but what does the reference image look like?
@vjleoliu
Here the image 2 is colored art and as a reference image we should input a chracter full body chracter image in any style then it will convert to that style and pose
(https://www.reddit.com/r/DigitalArt/comments/1lvdn6n/first_rendering_vs_flat_vs_rendered/)this is not my post btw
@LastDelivery4801226 To make AI learn a style, training is required; style transfer cannot be achieved just through a single guide image.
@vjleoliu i think qwen 2509 can adapt most style from refrence image ? the base idea is to transfer pose based of colored art
@LastDelivery4801226 It sounds like you already have a solution.
@vjleoliu I tried inputing 2 images
1)canny map of chracter in desired pose.
2)chracter image
(So I was thinking if instead of canny a lora that will help convert roughly coloured art instead of Canny map to get chracter in desired pose,)
Also flux kontext is better at style preservation ,but training lora on it requires merged images so I was thinking of qwen 2509.
@LastDelivery4801226 Shouldn't adjusting the pose be done with openpose?
@vjleoliu indeed but rough sketch gives frame wise control and allows better details,also openpose doesnt work on fictional character ex centaur.
@LastDelivery4801226 If your work requirements are very specific, it's better to train the model and design workflows in a targeted manner; only then can you achieve the best results.
@vjleoliu thank you for guiding !!,
could you please create another lora for line art only, no colors, white background and black outlines. and also, could you please share the style prompt of the converted image that you have created to train. means, the output image is in which style and their style prompt.
That's a good question, but it's a bit related to the little secrets of my training model, lol. I think I'll put it on my Patreon or write an article about it later, because explaining this question will take some space.
oh,by the way,Using the Canny function of ControlNet does not require a specific LoRA. The images it generates only have lines without colors, and that is why my LoRA is called CannyColoring.
@vjleoliu but canny lines are white and background is black. But will share link to your patreon.
@leyermo1234204 Use the inverse color function?