This workflow is intended to be used with the Z-Image Turbo model to generate an image and then refine the image using the GonzaLomo V6.0 Photo XL model. V6.0 will provide the image with much better detailed anatomical features.
Note that it's not required to use the GonzaLomo SDXL model as any photorealistic SDXL model should do a very good job at refining the Z-Image image.
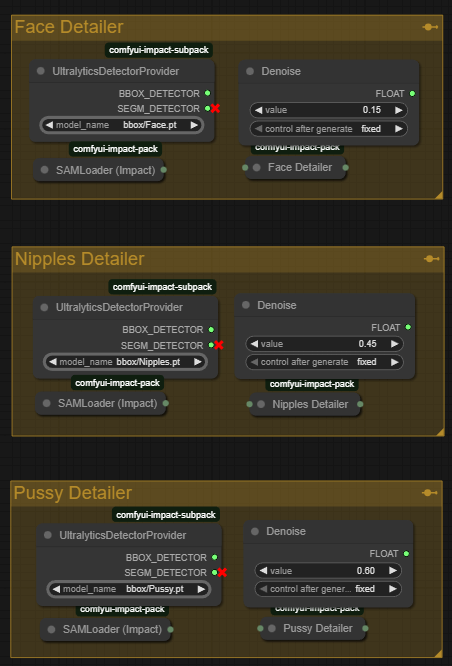
The different detailers require separate models that should go in your ComfyUI /models/ultralytics/bbox folder. I've uploaded them to this model page here but you can also find these files here and here.
Description
These are the Ultralytics bbox files I use with the FaceDetailer nodes to fix the bits of the image that Z-Image messes up. You know which bits I mean.
FAQ
Comments (69)
The ashllay yolo files you linked are marked as harmful on huggingface.
No, the files I use in my workflow are not marked that way. If you look at the header on https://huggingface.co/ashllay/YOLO_Models/tree/main/bbox it says that there are 12 files marked as unsafe and there's a button that will show you those files. The rest of the files on the page are scanned and safe.
Hi, thanks for the workflow. But I don't understand how to use it, first the z-image pipeline doesn't have the z-image model loaded so I changed it but I don't know if I did right. Then I can't find the "gonzalomoChroma_v12FP8UNET_Converted" model, I find the UNET or the Converted but not both hahahah Also I can't find flux.vae. Thanks again, your workflow looks promising.
yeah bro didnt include links to the models used in this workflow it seems.... just go to his gonzolomo pages and you can find the files there most likely
All the models used in these workflows are linked in the Suggested Resources section.
@GBRX no they aren't
@Jurangi they are just at the bottom of this page, check again. Thanks @GBRX I didn't know that Resources section even exists hahaha
@kazulu there are like 4 but not every single thing needed for every node
@Jurangi Please be specific about what you're missing to run the workflow.
Hi, i like your work, thank you. I wonder can you add links to model you using as its hard to find exackly one as you using specific name for it.. and i cant find same model for example chroma and also z image
Thanks! The Suggested Resources section on this page has all the model references you need.
Many thanks for creating this workflow. The refiner part of the workflow can be used with any model and it is fast. Fantastic work! Love it!
Exactly, it works great for refining anything. I use it for flux as well as z-image.
Thanks for greate work! Fixed the last puzzle of Z-Image. And not only for z-image,any model can use it.
Searching for detection models is like a treasure hunt. I've got a pretty big list after a few years, but it's always nice to find new once. A really good model when parsing faces for masking and detailing really makes the difference. The only use I have for z image is faces- it does a really good job fixing faces from anything. But your setup is interesting, maybe zit doesn't suck for everything else if used properly. I shall try it out. Thanks for the up.
Oho, very nice, very nice indeed. You've definitely addressed all of the shortcomings with which I was really disappointed when I first tried out ZiT. Real solid work, really nice. Bonus points for finding two or three newer bbox models.
@Ponder_Stibbons Thanks!
I found one issue. The workflow by default hates dongs. Mangles them. The refining stage specifically. Everything else is awesome. What I did to fix it was to add a segm dong detector after the initial generation. The mask output of the segm combo detector is inverted and the outgoing latent is masked with a 'set latent mask' node. This hides the dinguses from the refiner so it can't explode them into monstrous mutant blobs. Just an fyi for anyone who doesn't want to change models and has this problem. And yes, I tried a schlong refining stage, which doesn't work, as there is nothing to refine by the time it gets there, and all of the myriad LoRAs available to modify the refiner, and negging the hell out of it. But anyway it comes out of the first stage just fine so for me, masking the latent works perfectly, and it's easy. This was a weird one; I've never had a stage fight me so hard before, I guess it's just idiosyncratic of the model/encoder. This isn't a criticism of the workflow, just a workaround I can see other people needing maybe. For those people I would add that the penis does not go ON the chick, as in attached to her. I don't know how so many people on this site get this wrong.
The problem isn't the workflow. Z-Image has no idea what a penis is supposed to look like - similar to Flux. I think there are some other checkpoints and loras that are better trained for this. Maybe in the next version I'll try to improve it.
@GBRX No, really it's ok. Better than ok, it's awesome. At least in the WF I'm referring to CZXL, ZiT is only doing the refining - the first stage with Chroma does just fine. ZiT was mangling it in the refiner far, far more than it should have for at .5 denoise- like it had a grudge or something. After working my way through alternate samplers I discovered that this was mostly due to euler being the default. Took me a while to get to LCM, as I don't think I've ever used it for still images, but LCM/karras solved the problem. And you know what, that is specifically mentioned on the Zpop model page. So I'm not going to complain that it should be the default, obviously I should have gone to the page first and checked. Total n00b move on my part. Doesn't matter that ZiT is androphobic for a refine pass, with the proper sampler. And a phallus masker is easily adapted to a phallus refiner on the XL side, where it now has something to detect. So not a waste of time.
Again, really nice work. I had relegated ZiT to a face refiner, but you've given it a bit more to do, and the others, chef's kiss. Output is already incredible by the time it gets to XL. You can add to it, sure, but improve? A frightening prospect. Godspeed.
@Ponder_Stibbons Awesome, thanks for all the feedback!
how is it refining the required locations is this being done through some applied masking or something i don't really understand how selection refinement is automated into the rendering of the image? or is it just refinement over the whole image then i get it?
The FaceDetailer node is using bbox files that can segment the parts of the image they've been trained to detect. Then just those sections are refined.
Hello
i would like to use your workflow but i cant find the exact model : gonzalomoChroma_v12FP8UNET_Converted.safetensors
EDIT : i have find it on hugging face , i try to have same result than your generation "https://civitai.com/images/113830401" but its totally different.. there is 2 girls in my generation with exact same metadata.
and
gonzalomoZPop_v10_fp16.safetensors
______________________________________________________
I have downloaded all the models from the suggested resources but nothing have exact model name from your workflow , where do i made a mistake ? thanks for all !
@GBRX Could you please fix it on description? I was searching for same hahaha. Thanks !
should i train a lora on some of your models for better results or i can use basic z image model
When creating my models I haven't taken training into account so I can't guarantee how well that would work. I would probably stick to the official Z-Image releases when doing training.
Maybe im missing something but i cant find gonzalomoChroma_v12FP8UNET_Converted.safetensors or gonzalomoZPop_v10_fp16.safetensors
Does anyone have a download link for me? Or am i just blind af
The links to any models used are in the Suggested Resources on this page.
any juicy wf for base yet? :)
Sorry, not yet. I haven't had much of a chance to work with base yet.
where do I add a model for the samloader?
ComfyUI/models/sams
@GBRX Thanks. Could you also tell me why you use short prompts "1girl, blonde hair, blue jeans" etc? I thought ZIT works best with natural language prompts.
@pogo Because I'm lazy and time-constrained so I re-use a lot of my older SD 1.5 and SDXL tag-based prompts without rewriting them as captions. You can still get great results sometimes.
I find that when I use a character LoRA, the 'Chrome Base' outputs a the character perfectly, but the subsequent generations 'Refiner' and 'SDXL Detailers' completely lose my character LoRA and it's a completely different person. Hw can I fix this?
You would either need to keep the denoise very low on the refiner/detailers or have Z-Image and/or SDXL character loras as well so that the consistency is maintained.
Does anyone else get nightmare fuel when you add a lora? the regular z image workflow handles 2 at most, and then the same thing happens, Is that a thing with z image?
Try lowering the lora strength. I find 0.3-0.5 is a good strength for z-image loras. Weird stuff starts happening above 0.5.
@GBRX Thanks. I knew something must be weird about how it was handling loras. Some of them handle fine at 1, but I only have a few since I just started using z image
It seems to depend on the model too. My results on Moody and Redcraft aren't very good, but on Pornmaster the quality is excellent.
Hello i have tried to train Loras for this workflow, but it does not work with any of them, what model should i use as base for the training? I have tried ZIT
Im using CZXL1
I have connected the links with the lora in Zimage, and i have tried to applied the lora in the CHroma base and/or zit refiner, but none of them are taking it
Okay after testing more, if i use the lora on zit refiner 1.0 and denoise 1, looks that it workss better, but i cant generate the image with a lora
but which lora base do i need to create the base image?if i use it in the refiner it does strange things
@GBRX could you help me?
@null I don't understand what the issue is. What model architecture is your lora trained for?
@GBRX Ive tried with flux, sdxl and zit, but when they dont work in the base image generation, they do in the refiner but its poinless for me there
@null If you're using the CZXL workflow then the base image generation is Chroma, so you need a lora trained for Chroma there. Flux will probably also work. The refiner is Z-Image so you will need a lora trained for that model architecture there.
Working pretty good! Thanks! Is there a way to use this with I2I? I want to input NSFW images into this.
Takes pretty long and you get that typical plastic look. Thanks anyways.
Hello, I am getting this error when creating: VAEDecode
The size of tensor a (16) must match the size of tensor b (128) at non-singleton dimension 1
Can anyone help me with this?
It sounds like you're using the wrong VAE for the model. There's a model architecture mismatch somewhere.
@GBRX I noticed that you have Flux-vae there and I used Flux2-vae there. Could that be the problem?
@endurorebelsriders142 Yes, that's the problem
Great thanks, I fixed the problem but now I have another problem, specifically this one:
CLIPTextEncode
ERROR: clip input is invalid: None
If the clip is from a checkpoint loader node your checkpoint does not contain a valid clip or text encoder model.
Can you give me another advice on how to fix it? I would be very grateful...
@endurorebelsriders142 Impossible for me to debug it for you. I would go back to using the workflow as you downloaded it without modifications. Make sure it works first and then start making incremental changes.
@GBRX The workflow is in the basic version as I downloaded it, completely without any modifications, and yet I get this error...
@endurorebelsriders142 Which z-image model are you using? If it's one of mine and it doesn't say 'AIO' in the name then it doesn't include the clip or vae. 'AIO' means all-in-one. So you may need to load the clip and vae separately.
@GBRX I use: GonzaLomo ZPop
@endurorebelsriders142 That's a unet-only version. You need to supply the clip and vae
Hey there, great workflow, thank you. One question, the initial flux preview has a lot of noise/pixalated, the final refined image looks pretty good but I want to make sure this is intended and I'm not short changing myself here.
Hey thanks. The final result of the workflow is what is intended
Z Image Turbo looks so realistic but lacks in some areas. This adds so much more detail those "important" areas. I added some custom loras for the pony and turbo checkpoint that I'm using and it makes a big difference. I also highered the strength on some of the detailers which helped a lot. Thank you : )
Awesome, thanks for the great feedback
Thanks for the workflow, the detailer nodes are useful indeed.
Why the 2 samplings split at step 3, though? I can't see any difference with just running a single KSampler node.
It allows more flexibility to have different ksampler settings on the initial steps, affecting the composition, and then other ksampler settings on the later steps effecting the finer image details. In reality it probably is not going to make a huge difference.