
Qwen Image Layered Automated Workflow
Quick Description
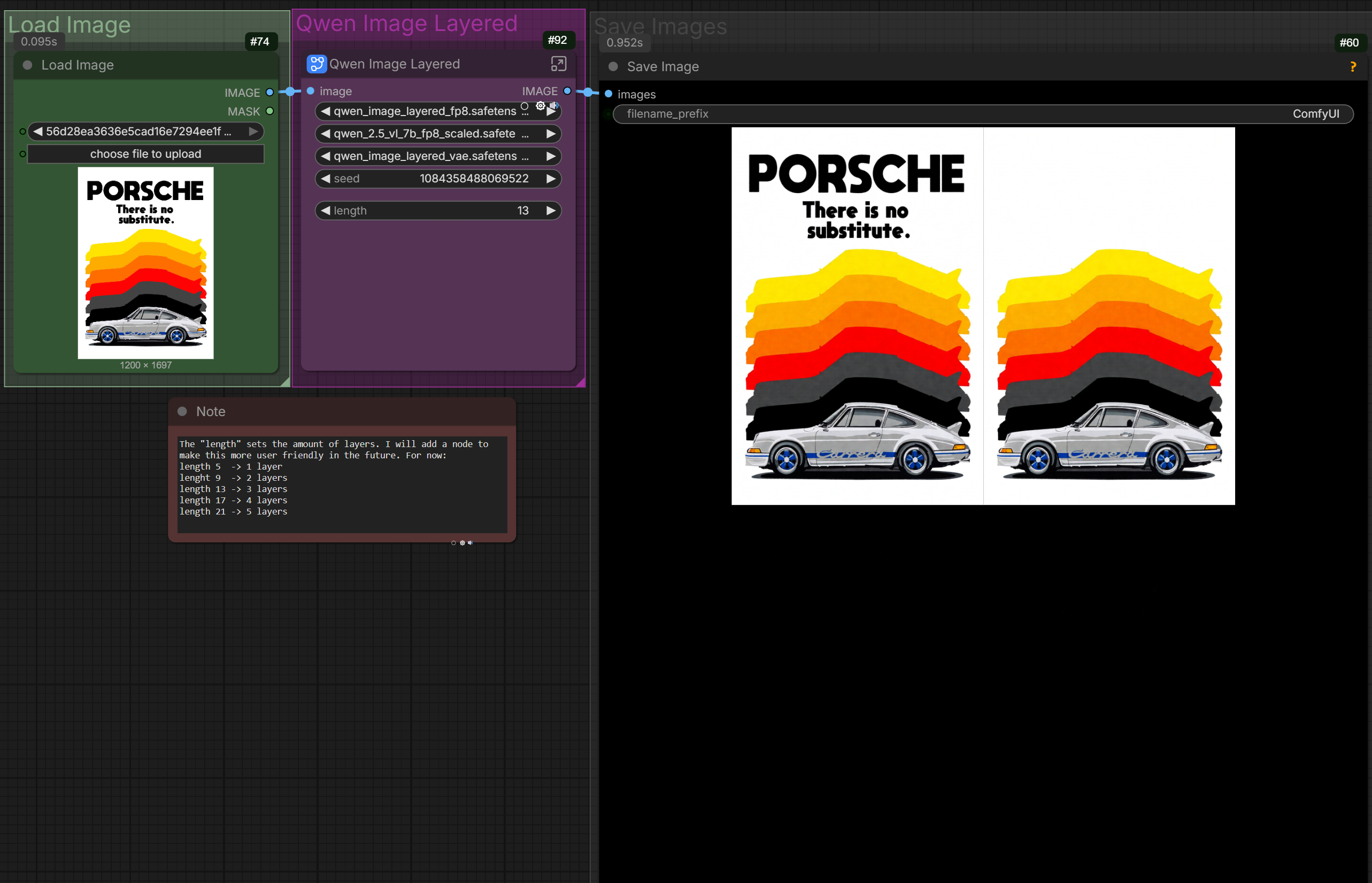
A fully automated ComfyUI workflow that intelligently detects the optimal Qwen-Image resolution for your input image's aspect ratio, automatically scales it, and generates stunning outputs using the Qwen Image Layered model with auto-captioning.
Key Highlights
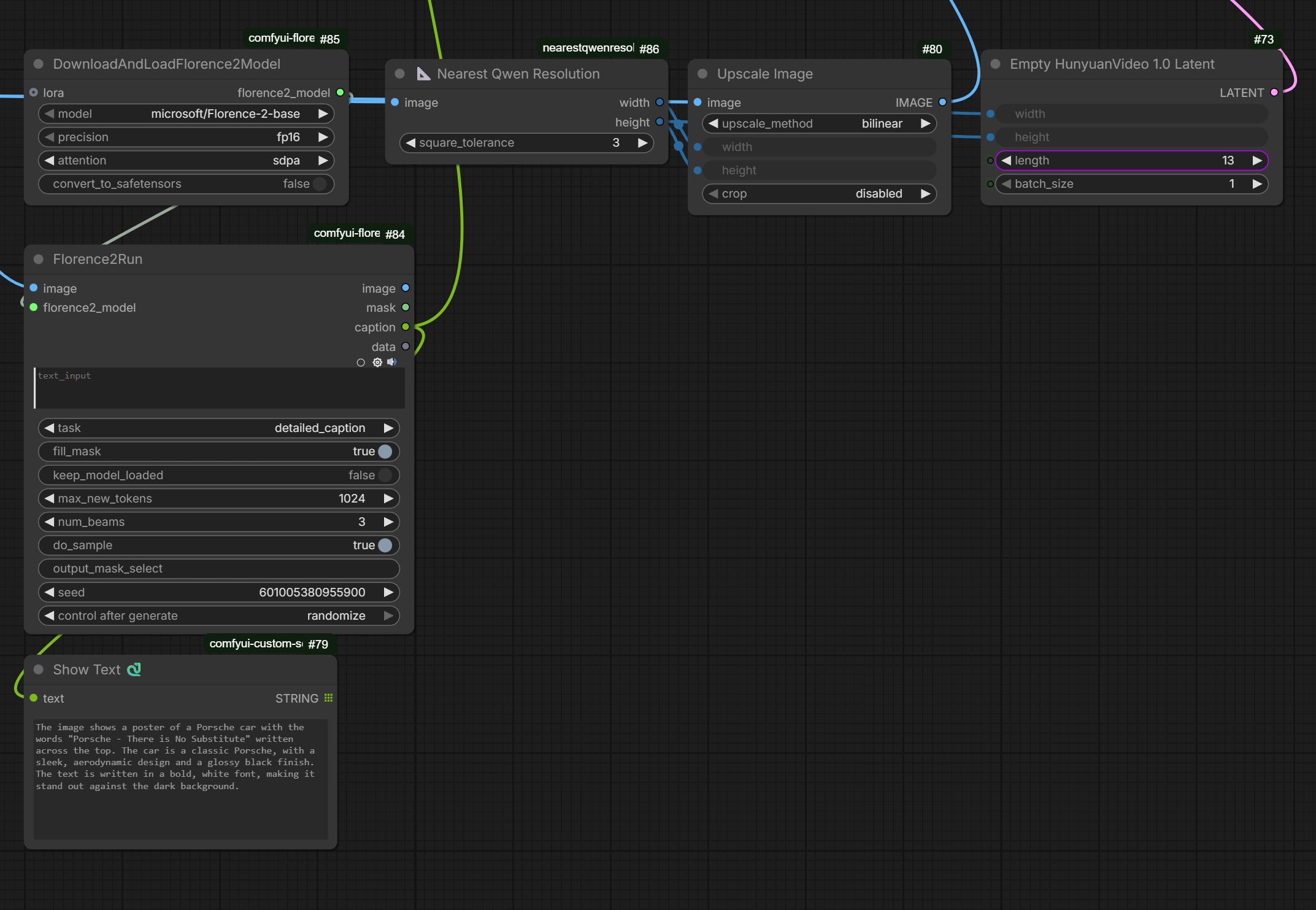
✨ Smart Resolution Auto-Detection – The Nearest Qwen Resolution node automatically analyzes your input image and selects the perfect Qwen-approved resolution (7 official presets covering all aspect ratios)
🎨 Fully Automated Pipeline – Load image → Auto-detect resolution → Auto-caption with Florence2 → Generate → Save (zero manual setup needed)
⚡ Optimized for Quality – Uses only official Qwen-Image training resolutions (~1-2 megapixels, 32-pixel multiples) for artifact-free generation
🔧 Highly Configurable – layer count, seed...
Installation
Install the https://github.com/DenRakEiw/ComfyUI-nearest-qwen-resolution custom node
Ensure you have Florence2 and Qwen Image Layered models
Load Workflow into ComfyUI
Hit generate!
Everything is automated – just load your image and watch it generate!
Description
FAQ
Comments (8)
Man, LatentCutToBatch node still has problem get installed. Updating ComfyUI does not work and the issue ticked of ComfyUI official guthub says thsi node has been merge Yesterday. I don't have the courage to update my ComfyUI to nightly. What do you force us to do?
I updated comfyui just now and that node isn't showing.
Update Comfyui with the update.bat
have to use nighly. it still doesn't work on stable comfy
Can't find that latentcuttobatch node. What node set is that coming from?
Update Comfyui with update.bat
@denrakeiw I did but still wasn't able to get that node. So I made my own nodes to do it, and my own nodes for using Qwen layered with diffusers. What are you finding works best in terms of prompts? No prompt is almost as good.
https://github.com/EricRollei/Qwen_Layers_Diffuser_Pipeline_Comfyui
Denis this is what I made for what it's worth. I didn't end up using the wan video latent or the latent cut to batch node that I made either. I went straight with the diffusers pipeline and used the embedded vision inside the Qwen iamge layered model directly so I skipped all of that stuff. Also I don't need any resize nodes since I do that internally in my decompose node as well. I added a few things like saving the image stack directly in a .psd file. Eats VRAM and GPU (I have rtx 6000 pro) but works. Maybe it was overkill but I think the internal caption works and possibly better in Chinese than english but may depend on context.